Q1. What Is Alert Fatigue in Cybersecurity, and Why Is the Problem Escalating?
Alert fatigue in cybersecurity is the state of cognitive, operational, and human exhaustion that occurs when SOC analysts are exposed to an overwhelming volume of security alerts, most of which are false positives, duplicates, or low-context notifications, leading to desensitization, missed threats, and delayed response.
Here’s a distinction that matters more than people realize: an alert is a signal; an incident is a confirmed threat. When fatigue causes analysts to treat every alert as noise, the gap between these two widens dangerously. I call this the “cry wolf effect.” After hundreds of false alarms, analysts psychologically de-prioritize ALL alerts, including the real ones. And that’s not a training problem. It’s an architectural one.
The Three Dimensions of Alert Fatigue
Not all fatigue looks the same. From what we’ve seen across hundreds of SOC environments, alert fatigue operates across three distinct dimensions:
Cognitive fatigue refers to the neurological degradation of decision-making quality after sustained exposure to repetitive, low-value signals. Analysts literally lose the ability to distinguish real threats from noise after processing hundreds of near-identical alerts. The brain defaults to “probably benign” as a survival mechanism.
Operational fatigue describes the systemic breakdown of SOC workflows when alert queues permanently exceed team capacity. SLAs breach, backlogs grow, and triage becomes checkbox-clearing rather than investigation. When your queue never empties, you’re not doing security. You’re doing data entry.
Human fatigue captures the emotional exhaustion, burnout, and career disillusionment that drives attrition. Analysts feel their expertise is wasted on mechanical noise-clearing rather than meaningful security work. According to Tines, 71% of SOC analysts report experiencing some level of burnout, with nearly half describing themselves as “very burned out.”

⚠️ The Numbers That Should Keep You Up at Night
The scale of this problem is quantifiable, not theoretical:
- Forrester reports SOC teams receive an average of 11,000+ alerts per day.
- SOC analyst burnout has reached crisis levels, with 67% of security professionals reporting severe fatigue and average SOC turnover rates hitting 28% annually.
- Alert fatigue peaks at 174 security alerts per analyst daily, with only 22% requiring genuine investigation.
- Excessive false positives consume 52% of analyst time, while manual processes that could be automated represent 38% of daily tasks.
- The global cybersecurity talent gap sits at 3.5 million unfilled positions, meaning most SOCs operate well below required headcount.
Why This Is Not a Volume Problem
Alert fatigue is not a volume problem you can hire your way out of. It’s an architectural failure in how security tools generate, prioritize, and present signals to human decision-makers. Throwing more analysts at 11,000 daily alerts is like hiring more people to carry water in buckets when you need a pipeline.
This playbook breaks alert fatigue into its component types and causes, maps its impact on teams and compliance, and provides a detection audit framework, technology strategy, and implementation roadmap to eliminate it. Several of the frameworks presented here are informed by UnderDefense’s operational data from managing 65,000+ endpoints across 500+ organizations.
Q2. What Are the Five Types of Alert Fatigue, and How Does Each Show Up by Tool?
Saying your SOC has “alert fatigue” is like saying your car has “engine trouble.” It doesn’t tell you what to fix. Each type of fatigue has different root causes, different tool sources, and different solutions. Identifying which types dominate your environment determines where to invest first.
The Five-Type Classification
Here’s the framework we use when diagnosing SOC fatigue across client environments:
Volume-Based Fatigue occurs when the sheer quantity of alerts exceeds human processing capacity regardless of quality. The queue never empties. Even if every alert were perfectly tuned, the math still doesn’t work at 174 alerts per analyst per day when only 22% require genuine investigation.
False Positive Fatigue emerges from repeated investigation of alerts that turn out to be benign, eroding analyst trust in the detection system itself. When 52% of analyst time goes to chasing false positives, the system is training your people to ignore it.
Context Starvation Fatigue happens when alerts arrive with insufficient information to make a decision. “Anomalous login from new IP” tells you nothing without organizational context: user role, travel status, and asset criticality. Analysts must manually pivot across 3 to 5 tools to gather enough context for a single verdict.
Tool-Switching Fatigue represents the cognitive cost of context-switching between multiple security tools during a single investigation. Each tool has a different UI, query language, and data schema. Your analyst’s brain has to reboot its working memory every time they alt-tab.
Repetitive/Duplicate Fatigue occurs when the same event generates alerts in multiple overlapping tools. One suspicious login triggers your SIEM correlation rule, your identity provider’s anomaly detection, your EDR behavioral flag, and your cloud security posture alert. Four investigations, one event.
📊 The Per-Tool Fatigue Map
Each type of fatigue maps to specific tool categories where it manifests most acutely:
| Tool Category | Primary Fatigue Type | What Happens |
|---|---|---|
| SIEM | Volume + Duplicate | Thousands of correlation rules fire simultaneously, many with overlapping logic. Analysts drown in correlated alert chains that may represent a single event. |
| EDR/XDR | False Positive | ML-based behavioral models flag legitimate admin activity as anomalous. PowerShell, WMI, and RDP usage by IT teams generates constant false positives. |
| Identity Security (Okta, Entra ID) | Volume + Context Starvation | Impossible logins, MFA fatigue attempts, and new device registrations for a mobile-first workforce generate enormous volume with limited context about legitimate travel or device changes. |
| Email Security Gateway | False Positive + Context Starvation | Sandboxing returns “suspicious but not confirmed” on 30–40% of flagged emails. Analysts must manually review each without clear binary signals. |
| Cloud Security (CSPM/CWPP) | Volume + Repetitive | Hundreds of best-practice violations flagged daily, most representing accepted risk or in-progress remediation that was never whitelisted. |
✅ The Diagnostic Move
Map your alert queue against these five types for one week. Most SOCs discover that 2 to 3 types account for 80% of their fatigue. That’s where your remediation effort should begin, not by trying to fix everything simultaneously.
UnderDefense MAXI addresses each type architecturally: volume and duplicates via intelligent deduplication and cross-tool alert grouping, false positives via continuous detection tuning, context starvation via automated multi-source enrichment, tool-switching via a unified investigation console, and repetitive alerts via correlation across 250+ integrated tools.
Q3. What Are the Root Causes of Alert Fatigue in a SOC?
Alert fatigue is a symptom, not a disease. To eliminate it, you must identify which structural failures are active in your SOC. Most organizations suffer from five to seven simultaneously, which is why point fixes like “just tune the SIEM” consistently fail.
The Nine Root Causes: A Diagnostic Checklist
Here’s every root cause we’ve mapped across client environments, each with a diagnostic question you can answer today:
1. Excessive false positives from poorly tuned detection rules
Detection rules deployed at vendor defaults without calibration to organizational baselines. Most customers never tune them.
🔍 Diagnostic: “What percentage of your detection rules have been tuned in the last 90 days?”
2. Tool sprawl and integration gaps
The average SOC investigation spans multiple tools with no shared context layer. Each investigation becomes a scavenger hunt across disconnected dashboards.
🔍 Diagnostic: “How many tools does an analyst open to investigate a single alert?”
3. Insufficient alert context
Alerts arrive as “anomalous login from new IP” with no organizational context. Two types of context are missing: organizational (who is this person, what’s their job, is this normal for them?) and telemetry (what happened before and after this event across all tools?).
🔍 Diagnostic: “Does your alert include the user’s role, manager, and recent activity when it arrives?”
4. Alert volume exceeding human cognitive processing capacity
Even well-tuned environments generate more signals than human analysts can process in real time. At 174 alerts per analyst daily, the math simply doesn’t work.
🔍 Diagnostic: “What is your current alert-to-analyst ratio?”
5. Staffing shortages and the cybersecurity talent gap
With 3.5 million unfilled global cybersecurity positions, most SOCs operate at 60–70% of required headcount. You can’t solve an architectural problem with hiring, but understaffing makes every other problem worse.
🔍 Diagnostic: “How many open SOC positions have been unfilled for more than 90 days?”
6. Lack of risk-based prioritization
All alerts arrive as “high” or “critical” with no asset criticality scoring or business impact weighting. The CFO’s laptop and a test server trigger the same priority level.
🔍 Diagnostic: “Does your alerting system differentiate between a developer workstation and a domain controller?”
7. Default/generic detection rules shipped with security products
Vendors ship broad detection rules to minimize missed threats, knowing customers will tune them. Most customers never do.
🔍 Diagnostic: “How many of your active detection rules are vendor defaults vs. custom-written?”
8. No feedback loop between triage analysts and detection engineering
Analysts clear false positives daily, but their findings never systematically flow back to improve the rules that generated them.
🔍 Diagnostic: “Do your analysts have a documented process to submit tuning requests that get implemented within 7 days?”
9. KPIs rewarding alert throughput over investigation quality
SOC teams measured on “alerts closed per shift” incentivize fast clearing, not thorough investigation. Quantity metrics crowd out quality metrics.
🔍 Diagnostic: “Are your analysts measured on alerts closed or threats confirmed?”
⚠️ Score Yourself
If you answered unfavorably on five or more of these questions, your SOC has structural alert fatigue that no single tool purchase will fix. The remediation sections that follow address each cause systematically.
UnderDefense’s 30-day onboarding begins with mapping each of these nine causes to specific misconfigurations in your existing stack, typically identifying 40–60% of rules as candidates for tuning, consolidation, or retirement. As one reviewer noted:
“Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into.”
— Verified User, Marketing and Advertising UnderDefense G2 – Verified Review
Q4. How Does Alert Fatigue Impact SOC Teams, Business Risk, and the Bottom Line?
⏰ 3:12 AM on a Thursday
Your on-call analyst’s phone buzzes for the ninth time tonight. She opens the SIEM console, spends 22 minutes investigating a critical alert, and it’s another false positive from a developer deploying to staging. She clears it, lies back down, and the phone buzzes again at 3:38 AM. By 7 AM, she’s investigated six false positives and missed the one real alert buried at position 47 in the queue: a credential-stuffing attack active since 2:47 AM. Dwell time: four hours and counting. By the time she logs in for her regular shift, the attacker has moved laterally to a database server containing 2.3 million customer records.
This scenario is not hypothetical but the operational reality of every SOC running at 174 alerts per analyst per day where only 22% warrant genuine investigation.
The Impact Breakdown
❌ Missed threats and increased breach risk: 71% of SOC analysts experience burnout, and average SOC turnover rates hit 28% annually. Fatigued analysts miss real threats because their brains have been trained by thousands of false positives to default to “probably benign.”
⏰ Delayed incident response: MTTD and MTTR both increase dramatically when analysts are overwhelmed. Organizations lose approximately $1.4 million annually per burned-out senior analyst through recruitment, training, and knowledge transfer costs.
⚠️ Real-world breach example, Target (2013): FireEye detection tools flagged the malware. The security team received the alerts and did not act on them. Result: 40 million payment cards compromised, 70 million customer records stolen, and $200+ million in total costs. Target had 300+ security staff and cutting-edge detection tools. They still missed the breach.
💸 Leadership confidence erosion: When the CISO presents SOC metrics showing “4,500 alerts processed daily” but can’t demonstrate those alerts translated into threat prevention, board confidence in security investment erodes. The metrics become performative rather than protective.
💰 The Cost Quantification Formula
Here’s a model you can calculate internally:
Annual Alert Fatigue Cost = (Daily FP Volume × Avg Investigation Time in Hours × Analyst Hourly Cost × 365) + (Annual SOC Turnover Rate × Per-Analyst Replacement Cost × SOC Headcount) + (Breach Probability Uplift from Fatigue × Organization’s Avg Breach Cost)
Example calculation:
(3,588 daily FPs × 0.25 hrs × $65/hr × 365) + (28% turnover × $75K × 10 analysts) + (15% uplift × $10.22M) = $21.3M + $210K + $1.53M = ~$23M annual exposure
👉 Calculate your exact SOC cost exposure with UnderDefense’s SOC Cost Calculator →
✅ What the Ideal State Looks Like
In a properly architected SOC, analysts wake up to a morning summary, not a 3 AM alert storm. They review 5 to 10 pre-investigated, context-enriched incidents with full timelines, affected user verification already completed, and recommended containment actions. Their expertise is applied to decision-making, not data gathering.
We built UnderDefense MAXI around this exact vision: 2-minute alert-to-triage and 15-minute escalation for critical incidents. Agentic AI handles the mechanical investigation steps (log collection, enrichment, correlation, and user verification) that analysts currently perform manually at 3 AM.
UnderDefense clients report a 99% reduction in customer-facing alerts after detection tuning and agentic AI triage, shifting analyst workload from reactive noise management to proactive threat hunting.
“Before MaxiMDR, we were slightly overwhelmed with alerts and often unsure of how to prioritize or respond to them. Now, not only do we get alerts, but we also get clear guidance on how to handle them. This has significantly reduced our response time and has given our team a newfound confidence in managing potential threats. False positives have become a rarity.”
— Valeriia D., Marketing Specialist UnderDefense G2 – Verified Review
“Not having to worry about ransomware, alert overload and reporting. Getting a clear view of my security posture, where the threats are coming from and how they are handled. They literally took care of all our problems.”
— Arlin O., Enterprise (1000+ emp.) UnderDefense G2 – Verified Review
“Our IT team was overwhelmed by the sheer volume of security alerts and doesn’t have the resources for 24/7 monitoring.”
— Andriy H., Co-Founder and CTO UnderDefense G2 – Verified Review
Q5. How Do Attackers Weaponize Alert Fatigue to Bypass Your Defenses?
Alert fatigue isn’t just your problem. It’s your attacker’s strategy. Sophisticated threat actors have figured out that the best way past a SOC isn’t to evade detection entirely but to drown real attacks in a flood of noise that analysts are conditioned to ignore. When your team auto-clears 80% of alerts without investigation, attackers only need their malicious activity to resemble the other 80%. False positive rates in enterprise SOCs frequently exceed 50%, with some organizations reporting rates as high as 80%. That gap between detection and investigation is exactly where attackers live.
⚠️ The Threat Landscape Has Shifted
The barrier to entry for sophisticated attacks is collapsing while attack effectiveness is skyrocketing. Threat actors have weaponized agentic AI: reconnaissance, vulnerability identification, exploit development, and lateral movement are all accelerated by AI systems that work 24/7 without fatigue. What took days or weeks now happens in hours. A mediocre attacker with access to AI agents can now execute attacks that previously required elite red team skills.
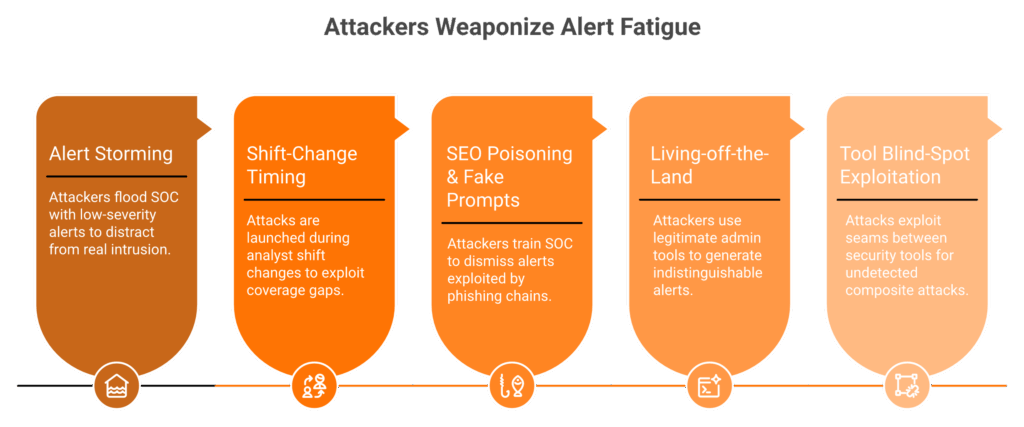
The Attacker Playbook: 5 Exploitation Methods
Alert Storming (T1498/T1046)
Deliberately triggering hundreds of low-severity alerts via port scans and login brute-forcing across non-critical systems to overwhelm the SOC while the real intrusion targets a single high-value asset. Your analysts are busy investigating noise on the left while the breach happens on the right.
Shift-Change Timing
Launching primary attack phases during analyst shift changes (typically 6–8 AM and 6–8 PM) when handoff gaps create 15- to 30-minute coverage windows. Attackers know your SOC isn’t a machine. It has seams, and those seams are predictable.
SEO Poisoning, Malvertising, and Fake Browser Prompts
Generating alerts that SOC analysts learn to classify as “user clicked bad link, reimaged machine, move on,” training the SOC to auto-dismiss the exact alert category that advanced phishing chains exploit. Unit 42 data shows social engineering remained the top initial access vector at 36% of all incidents, with more than one-third involving non-phishing techniques like SEO poisoning and fake system prompts.
Living-off-the-Land and Slow Exfiltration (T1059/T1048)
Using legitimate admin tools (PowerShell, WMI, and certutil) and low-bandwidth exfiltration to generate alerts indistinguishable from normal IT activity. Your SOC has tuned these alerts to low priority because they fire 200 times daily from legitimate admin work.
Tool Blind-Spot Exploitation
Targeting the seams between security tools where no single tool sees the full picture. Activity generates a low-severity EDR alert AND a low-severity identity alert, but no correlation engine connects them into the composite attack they represent.
🔍 The Architectural Response
Defending against weaponized alert fatigue requires a system that reasons across tools, not within them. When an attacker blends into EDR noise while simultaneously exploiting identity blind spots, only cross-telemetry correlation with organizational context, including who is this person, should they be doing this, at this time, from this location, can surface the composite threat. This is the fundamental shift from tool-centric detection to context-aware investigation.
How UnderDefense MAXI Fights Back
We built UnderDefense MAXI for this exact threat landscape. Agentic AI correlates signals across your entire stack, including endpoint, identity, cloud, network, and email, at machine speed. It connects the low-severity EDR alert to the low-severity identity alert to the subtle DNS anomaly that together constitute a coordinated intrusion. When behavioral alerts need human context (Did the user authorize that OAuth grant at 2:41 AM?), our analysts reach out directly via Slack or Teams to verify, the “breaking the fourth wall” capability.
The attacker’s strategy of blending into noise fails when the system asks the actual human: Was this you?
✅ Proof: Speed Matters
The traditional SOC model, where human analysts manually respond to alerts and contain threats, cannot match AI-powered attacker speed. UnderDefense MAXI fights AI with AI: agentic investigation at attacker speed, augmented by experienced analysts who understand intent, context, and business impact. Proactive threat hunting at 96% MITRE ATT&CK coverage scans for exactly these exploitation patterns. In documented head-to-head comparisons, UnderDefense detected and contained threats 2 days faster than CrowdStrike OverWatch, because when 13% of social engineering incidents trace back to ignored or untriaged alerts, speed isn’t a luxury. It’s survival.
Q6. Where Does Your SOC Stand? The Alert Fatigue Maturity Model
Most SOCs know they have an alert fatigue problem. Few can quantify how severe it is or benchmark against operational maturity. Score your SOC against this 5-level model to identify your current state and the specific capabilities needed to advance.
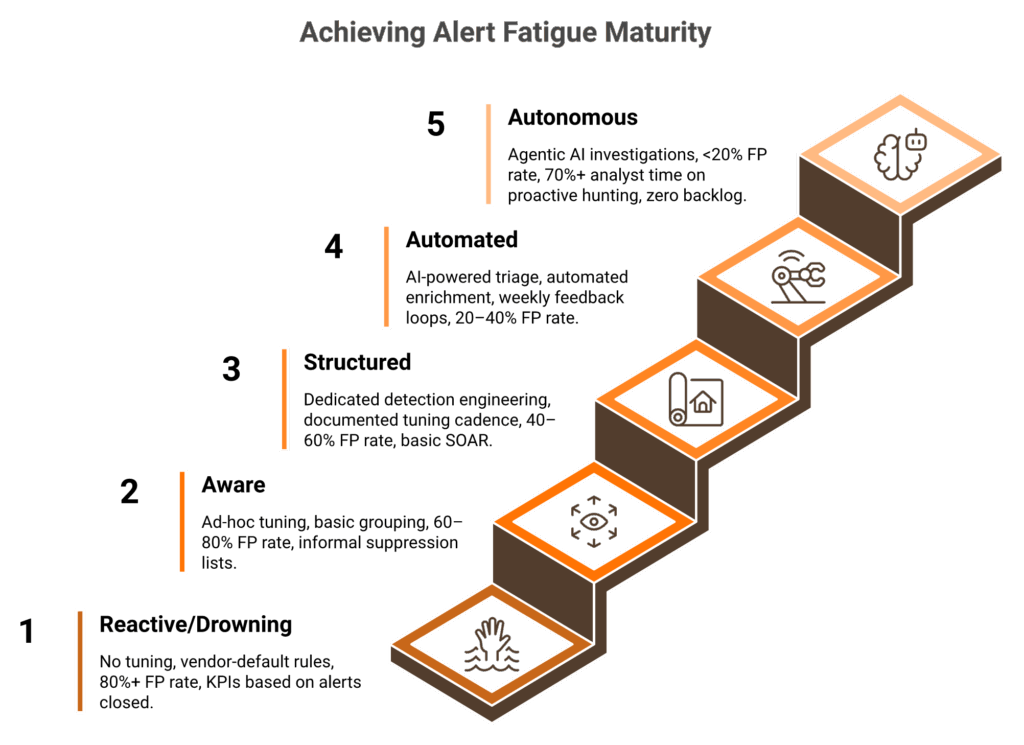
📊 The 5-Level SOC Maturity Model
| Level | State | Diagnostic Criteria | Recommended Action |
|---|---|---|---|
| 1 — Reactive/Drowning | No tuning, all vendor-default rules, >80% FP rate, analysts triaging raw alerts manually, no feedback loops, KPIs based on alerts closed | Begin emergency detection rule audit (see Q7) | Begin emergency detection rule audit (see Q7) |
| 2 — Aware | Some ad-hoc rule tuning, basic alert grouping, 60–80% FP rate, informal suppression lists, awareness that fatigue exists but no systematic program | Assign detection engineering ownership, implement tuning request process | Assign detection engineering ownership, implement tuning request process |
| 3 — Structured | Dedicated detection engineering function, documented tuning cadence, risk-based prioritization with asset criticality scoring, 40–60% FP rate, basic SOAR playbooks for top-10 alert types | Deploy AI-powered triage for automated enrichment | Deploy AI-powered triage for automated enrichment |
| 4 — Automated | AI-powered triage for all alert types, automated enrichment and cross-tool correlation, analyst feedback loops feeding detection engineering weekly, 20–40% FP rate, proactive threat hunting program exists | Implement agentic AI investigation and ChatOps user verification | Implement agentic AI investigation and ChatOps user verification |
| 5 — Autonomous | Agentic AI conducts full investigations autonomously, organizational context fully integrated, <20% FP rate, analyst time is 70%+ proactive hunting, continuous adaptive learning, zero alert backlog as operational norm | Optimize and refine; focus on emerging threat landscapes | Optimize and refine; focus on emerging threat landscapes |
☐ Diagnostic Self-Assessment Checklist
Rate yourself honestly. Each “yes” earns one point:
- ☐ Do you have a documented detection rule review cadence? (Level 2+)
- ☐ Can you measure your false positive rate per alert source? (Level 2+)
- ☐ Do analyst investigation findings feed back into detection tuning within 7 days? (Level 3+)
- ☐ Are alerts enriched with organizational context (asset owner, user role, and business unit) before analyst review? (Level 4+)
- ☐ Do you have risk-based alert prioritization using asset criticality scoring? (Level 3+)
- ☐ Can your system verify suspicious user activity directly via Slack/Teams without analyst intervention? (Level 5)
- ☐ Does your SOC operate at consistent quality 24/7/365, including nights and weekends? (Level 4+)
- ☐ Do your analysts spend more time on proactive threat hunting than reactive alert triage? (Level 5)
- ☐ Is your team measured on investigation quality (threats confirmed, MTTR) rather than throughput (alerts closed)? (Level 3+)
- ☐ Can a new alert be fully investigated, with enrichment, correlation, and context, within 2 minutes? (Level 5)
📈 Score Interpretation
| Score | Maturity | What It Means |
|---|---|---|
| 0–3 checks | Level 1–2 | ❌ Critical gaps: your SOC is likely missing real threats daily and burning out analysts on noise. Immediate action required. |
| 4–6 checks | Level 3 | ⚠️ Foundation in place: you’ve reduced the worst noise but lack automation, contextual enrichment, and feedback loop maturity. Strong candidate for AI augmentation. |
| 7–10 checks | Level 4–5 | ✅ Mature operations: focus on optimization, expanding proactive hunting, and continuous adaptive tuning. |
How UnderDefense Closes the Gap
UnderDefense MAXI is designed to move SOCs from Level 1–2 directly to Level 4–5 within 30 days of onboarding. Agentic AI handles mechanical investigation steps (context collection, log enrichment, multi-system correlation, and structured reporting). ChatOps user verification closes the organizational context gap that separates Level 3 from Level 5. Continuous feedback loops ensure detection rules improve with every analyst verdict. Most clients score 7+/10 within the first month, without replacing their existing SIEM or security tools.
“Before MaxiMDR, we were slightly overwhelmed with alerts and often unsure of how to prioritize or respond to them. Now, not only do we get alerts, but we also get clear guidance on how to handle them. This has significantly reduced our response time and has given our team a newfound confidence in managing potential threats.”
— Valeriia D., Marketing Specialist UnderDefense G2 – Verified Review
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User, Marketing and Advertising UnderDefense G2 – Verified Review
“UnderDefense MAXI integrates well with our systems, specifically with our SIEM, Splunk. Their team is proactive in identifying and addressing threats, providing 24/7 oversight.”
— Oleg K., Director Information Security UnderDefense G2 – Verified Review
Q7. How Do You Audit Detection Rules to Eliminate Noise at the Source?
Every article about alert fatigue says “tune your SIEM.” None tell you how. This 10-step detection rule audit provides a repeatable, scorable process your detection engineering team can execute quarterly. It’s the single highest-ROI activity for reducing alert fatigue, fixing noise at the source rather than filtering it downstream.
The Action-Centric Detection Philosophy
Only alert on events you can take action on. If a detection rule fires and the standard response is “investigate and probably close,” that rule is noise, not detection. Every rule must have a defined response action before it enters production.
🔧 The 10-Step Detection Rule Audit
- Inventory all active detection rules across all sources (SIEM, EDR, cloud, identity, and email).
- Calculate signal-to-noise ratio per rule: true positives ÷ total firings over 90 days.
- Map each rule to MITRE ATT&CK technique coverage. Identify both gaps AND redundancies (multiple rules covering the same technique).
- Assign ownership. Every rule must have a named analyst or team responsible for its performance.
- Score each rule on 4 dimensions (1–5 scale):
- Fidelity: true positive rate
- Coverage: ATT&CK mapping breadth
- Freshness: last tuned date; rules untuned >180 days are suspect
- Actionability: does the alert provide enough context for the analyst to decide without pivoting to other tools?
- Triage results: rules scoring <8/20 are candidates for retirement or consolidation; 8–14/20 need tuning; 15+/20 are production-ready.
- Implement context enrichment for surviving rules. Ensure each alert arrives with asset criticality, user role, recent activity timeline, and related alerts pre-attached.
- Deduplicate overlapping rules. Where 3 tools fire on the same event, consolidate to a single enriched alert with cross-tool context.
- Establish a formal feedback loop. Every analyst false-positive verdict generates a tuning request ticket with 7-day SLA for detection engineering review.
- Schedule quarterly re-audits. Detection rules degrade as environments change; what was well-tuned 6 months ago may be generating noise today.
📋 Sample Scoring Table
| Detection Rule | Fidelity | Coverage | Freshness | Actionability | Total | Verdict |
|---|---|---|---|---|---|---|
| Failed login > 5 attempts | 1 (fires from password managers, VPN reconnections) | 2 (T1110 Brute Force) | 1 (vendor default, never tuned) | 1 (no user context) | 5/20 | ❌ RETIRE or rebuild with context |
| Lateral movement via PsExec to domain controller | 4 | 5 (T1021.002) | 4 | 4 | 17/20 | ✅ PRODUCTION-READY |
| New OAuth app consent | 2 | 3 (T1550.001) | 3 | 2 (no user verification) | 10/20 | ⚠️ TUNE: add user verification via ChatOps, add app reputation scoring |
How UnderDefense Simplifies This
UnderDefense’s 30-day onboarding includes a complete detection rule audit across your existing SIEM and EDR stack. Our detection engineers apply this 10-step framework to every active rule, typically identifying 40–60% as candidates for retirement or consolidation, and deploy custom rules mapped to your specific threat profile with 96% MITRE ATT&CK technique coverage. Rules aren’t just tuned; they’re rebuilt with organizational context enrichment and action-centric design. As one CISO from a podcast session put it: “All of my business logic stays with me” when the SIEM ownership stays with the customer, and that’s exactly how we operate.
Q8. SIEM Tuning vs. SOAR vs. MDR vs. XDR vs. AI SOC: Which Technology Actually Solves Alert Fatigue?
Organizations fighting alert fatigue face a bewildering market of solutions: tune your SIEM, deploy SOAR, buy XDR, outsource to MDR, or adopt an AI SOC. Each claims to solve the problem. Most address only one dimension of fatigue while creating new ones.
📊 Technology Comparison
| Approach | What It Does Well | Where It Falls Short | Best For | Alert Fatigue Impact |
|---|---|---|---|---|
| SIEM Tuning | Foundational rule quality improvement | Manual, requires dedicated detection engineers; doesn’t speed investigation | Organizations with mature detection engineering teams | 🟡 Reduces noise at source but doesn’t scale |
| SOAR | Automates known playbooks | Brittle to novel threats; creates “playbook maintenance fatigue” | Repetitive, well-defined response workflows | 🟡 Automates triage for known patterns only |
| MDR | Outsources analyst workload 24/7 | Many providers just forward alerts (monitoring-only trap) | Teams lacking 24/7 coverage | 🟠 Varies wildly: some reduce fatigue, some just relocate it |
| XDR | Consolidates telemetry into one platform | Often creates vendor lock-in (CrowdStrike, Microsoft, and Palo Alto each building closed ecosystems) | Single-vendor environments | 🟡 Reduces tool-switching fatigue but forces replacement |
| AI SOC | Agentic investigation, adaptive learning, organizational context reasoning | Maturity varies wildly; some are SOAR with an AI label | Organizations wanting machine-speed investigation + human judgment | 🟢 Addresses root cause when implemented properly |
❌ Why SOAR Alone Didn’t Solve Fatigue
For the past 5 years, SOAR was positioned as the answer to alert fatigue. It didn’t work. Organizations that deployed SOAR still report 60–70% false positive rates and persistent burnout. Three failure modes explain why:
- SOAR can’t reason about novel attack patterns outside predefined playbooks.
- SOAR can’t incorporate organizational context. It doesn’t know that Jane is the CFO traveling in Singapore; it just sees “anomalous login from unusual geography.”
- SOAR creates NEW fatigue, specifically “playbook maintenance fatigue,” where SOC teams maintain hundreds of brittle automation rules that break when tool APIs change, vendors update alert schemas, or the environment evolves.
Behavioral analytics, alert deduplication, correlation, and proactive threat hunting all complement SOAR’s limitations, but no single bolt-on solves the architectural gap.
🧠 The Agentic AI Thesis
Agentic AI doesn’t follow playbooks. It conducts investigations. It autonomously queries your SIEM, pulls relevant logs, enriches with threat intelligence, correlates across data sources, and delivers structured investigation reports to analysts in seconds. The critical distinction: AI collects context and evidence; the human analyst makes the decision. This isn’t automation but augmentation.
Multi-agent systems run parallel investigations where specialized AI agents handle different aspects simultaneously: one enriches threat intelligence, another queries identity systems, another pulls endpoint forensics, and another reaches out to the affected user. Continuous adaptive AI learns from every analyst verdict. When an analyst marks an alert as false positive, the system adjusts its investigation approach for similar future alerts.
✅ UnderDefense MAXI as Reference Implementation
UnderDefense MAXI was built on the agentic AI principle: augment your analysts with machine-speed investigation, don’t replace their judgment. When MAXI encounters an alert, it conducts a full investigation: queries your existing SIEM (Splunk, Sentinel, and Chronicle, working with your stack, not a replacement), pulls relevant logs, enriches with threat intelligence, correlates across endpoints/identity/cloud/network, and when human context is needed, reaches out directly to affected users via Slack or Teams.
Key differentiators:
✅ Vendor-agnostic: works with 250+ existing tools without forcing replacement
⏰ 2-minute alert-to-triage, 15-minute escalation for critical incidents
✅ ChatOps user verification: the only AI SOC that “breaks the fourth wall” by directly contacting users
✅ Perfect fit for 5,000+ employee organizations who already have an internal SOC with SIEM and don’t want an MDR provider managing their systems
✅ Continuous learning: every analyst verdict improves future investigations
“Started out well but over the years the service has consistently not met expectations. The issues that we have experienced has greatly outweighed the benefits… Log collectors show working, however when asked to provide logs for an investigation no logs could be provided.”
— CISO, Manufacturing Arctic Wolf – Gartner Verified Review
“We received little value from ArcticWolf. The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Their team provided us with clear and detailed insights into security vulnerabilities, along with practical recommendations on how to fix them. This level of transparency made it easy for our team to take action and strengthen our security.”
— Arman N., CTO UnderDefense G2 – Verified Review
While traditional MDR tells you “suspicious login detected, please investigate,” UnderDefense tells you who logged in, confirms with the user directly, and contains the threat before your team wakes up, with documented response times 2 days faster than CrowdStrike OverWatch. That’s not automation replacing analysts but AI making every analyst operate at 10x capacity.
Q9. What Compliance Gaps Does Unresolved Alert Fatigue Create?
Alert fatigue isn’t just an operational problem but a compliance failure hiding in plain sight. When alerts go uninvestigated, your organization fails to meet specific, auditable security controls across every major regulatory framework. During your next audit, an assessor won’t accept “we had too many alerts” as an explanation for why a breach went undetected for 60 days. This section maps exactly which controls alert fatigue violates, so your GRC team can quantify regulatory exposure alongside operational risk.
⚠️ The Compliance Crosswalk: Alert Fatigue Failures Mapped to 9 Frameworks
| Framework | Controls Violated by Alert Fatigue | Why It Matters |
|---|---|---|
| NIST CSF | DE.CM (Continuous Monitoring), DE.AE (Anomalous Activity Detection), RS.AN (Response Analysis) | Uninvestigated alerts = non-compliant monitoring; assessors verify investigation logs, not alert volume |
| ISO 27001 | A.12.4 (Logging and Monitoring), A.16.1 (Information Security Incident Management) | Alert fatigue directly undermines both controls. Logging without investigation is checkbox theater. |
| SOC 2 | CC7.2 (System Monitoring), CC7.3 (Identification of Anomalies) | Auditors increasingly test whether flagged anomalies were actually investigated, not just detected |
| HIPAA | §164.312(b) (Audit Controls), §164.308(a)(6) (Security Incident Procedures) | Uninvestigated alerts on systems containing PHI create direct liability; logging without review is a known gap |
| PCI DSS | Req 10.6 (Review Logs and Security Events), Req 12.10 (Incident Response) | Req 10.6 requires DAILY review; auto-closing 80% of alerts without investigation violates by definition |
| GDPR | Art. 32 (Security of Processing), Art. 33 (Breach Notification within 72 hours) | Extended dwell time from fatigue makes 72-hour notification impossible |
| NIS2 | Art. 21 (Cybersecurity Risk Management Measures) | EU directive requiring proportionate security monitoring; fatigue-induced gaps are non-proportionate |
| SEC | Cybersecurity Disclosure Rules (2023) | Material incident disclosure obligations; delayed detection from fatigue delays disclosure |
| SOX | Section 404 (Internal Controls) | For organizations where IT systems impact financial reporting, unmonitored alerts represent internal control deficiencies |
💰 The Regulatory Cost of Ignoring Alerts
What makes this especially dangerous is the compounding effect. A single uninvestigated alert that masks a breach triggers failures across multiple frameworks simultaneously. A healthcare organization that misses a phishing-based credential theft because the alert was buried in 500 daily false positives faces HIPAA penalties for inadequate audit controls, NIST CSF non-compliance for failed continuous monitoring, and potential GDPR Article 33 violations if EU patient data is involved. All from one missed alert.
✅ How UnderDefense Closes the Compliance Gap
UnderDefense’s MDR includes forever-free compliance kits that automatically generate audit evidence from security monitoring activities, including alert investigation logs, response timelines, and detection coverage reports mapped to all nine frameworks above. When your auditor asks for evidence of continuous monitoring and incident investigation, the documentation is already assembled. This is particularly critical for healthcare organizations (HIPAA), financial services (PCI DSS, SOX), and EU-operating companies (GDPR, NIS2) where alert fatigue creates direct regulatory penalties, not just operational risk.
Q10. The Analyst Experience Playbook: How to Reduce SOC Burnout Beyond Technology
⏰ A Scenario That Plays Out Every Quarter
Your best Tier 2 analyst, the one who caught the supply chain attack last quarter, just submitted her two-week notice. Exit interview reason: burnout. She’s not leaving cybersecurity; she’s leaving SOC operations for a GRC role that doesn’t require 3 AM alert triage. You’ve now lost 18 months of institutional knowledge and roughly $75K in replacement costs. Her replacement will take 6 months to reach the same proficiency level. In the interim, alert coverage degrades, remaining team members absorb her workload, and the burnout cycle accelerates.
❌ The Numbers Don’t Lie
SOC analyst average tenure sits at 18–24 months, among the shortest in all of IT. According to the Tines Voice of the SOC Analyst report, 71% of SOC analysts experience burnout, and 64% are considering leaving their roles within a year. The SANS 2025 survey found that 62% of organizations do not retain talent adequately. This isn’t a people problem but a system design failure.
✅ The Analyst Experience Playbook: 8 Interventions That Actually Work
- Cognitive load rotation: Alternate analysts between alert triage, threat hunting, detection engineering, and incident response on weekly or bi-weekly cycles. Monotonous triage should never be a permanent assignment.
- Shift design: Implement follow-the-sun models, AI-augmented night shifts, or outsourced Tier 1 coverage to eliminate 3 AM human triage; overnight alerts should arrive pre-investigated by morning.
- Feedback loops with SLA: Every analyst false-positive verdict generates a tuning request with a 7-day implementation SLA; when analysts see their feedback actually reducing future noise, engagement and retention improve.
- KPI transformation: Replace “alerts closed per shift” with investigation quality metrics: threats confirmed, mean investigation depth, tuning recommendations submitted, and false positive rate reduction contribution.
- Career path architecture: Create advancement tracks within SOC operations (Analyst → Detection Engineer → Threat Hunter → SOC Architect → Security Strategist) that don’t require leaving the operations team.
- Recognition systems: Track and celebrate real threat catches; make “needle in the haystack” moments visible to leadership and the broader organization.
- HR communication: Brief HR on alert fatigue as a quantified operational risk with dollar impact, not “people just complaining”; include fatigue metrics in quarterly business reviews.
- Cross-training investment: Allow analysts dedicated time (4–8 hours/week) for skill development, certification preparation, and security research that isn’t alert triage.
How UnderDefense Enables the Playbook
Technology alone doesn’t solve burnout, but the right technology removes the conditions that cause it. UnderDefense MAXI shifts analyst workload from mechanical investigation (collecting logs, pivoting between tools, and gathering context) to strategic decision-making (evaluating pre-investigated incidents with full context, approving containment actions, and refining detection strategy). When the AI handles the 80% that’s mechanical, analysts apply their expertise to the 20% that’s genuinely interesting and career-developing. That’s how you retain your Tier 2 analyst: give her problems worth solving, not noise to clear.
From Nazar’s perspective on the hybrid SOC model: for organizations at a certain scale, outsourcing Tier 1 to a partner like UnderDefense while retaining Tier 2–3 in-house preserves business context where it matters most and offloads the high-turnover, high-burnout triage function to a team purpose-built for it. As one CISO described during our webinar: “If I can offshore the level one work, that work tends to be very commoditized… people are frequently moving on in their career path. So it might make sense for me to ask a vendor to manage that turnover. But I still keep a level two or level three team in-house.”
⭐ What the Data Shows
Organizations using agentic AI-augmented SOC models report 40% lower analyst turnover, because the job description changes from alert triage to threat investigation and strategic defense. UnderDefense clients report that analysts freed from mechanical triage spend significantly more time on proactive threat hunting and detection engineering, exactly the work that develops skills, builds expertise, and keeps experienced professionals engaged long-term.
“Their experienced SOC engineers work closely with our team, providing continuous monitoring and threat detection. They’re always on the lookout for potential vulnerabilities and take swift action to address them.”
— Oleksii M., Mid-Market UnderDefense G2 – Verified Review
“Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
“Started out well but over the years the service has consistently not met expectations. The issues that we have experienced has greatly outweighed the benefits… Analysts provide little context, and when asked for more information in the investigation nothing is ever provided.”
— CISO, Manufacturing (3B–10B USD) Arctic Wolf – Gartner Verified Review
Q11. The 90-Day Alert Fatigue Elimination Roadmap: From Reactive to Autonomous
Understanding alert fatigue is step one. Eliminating it requires a disciplined 90-day execution plan that addresses technology, process, and people simultaneously. Attempting all three at once creates change fatigue on top of alert fatigue. This phased roadmap sequences the highest-ROI activities first.
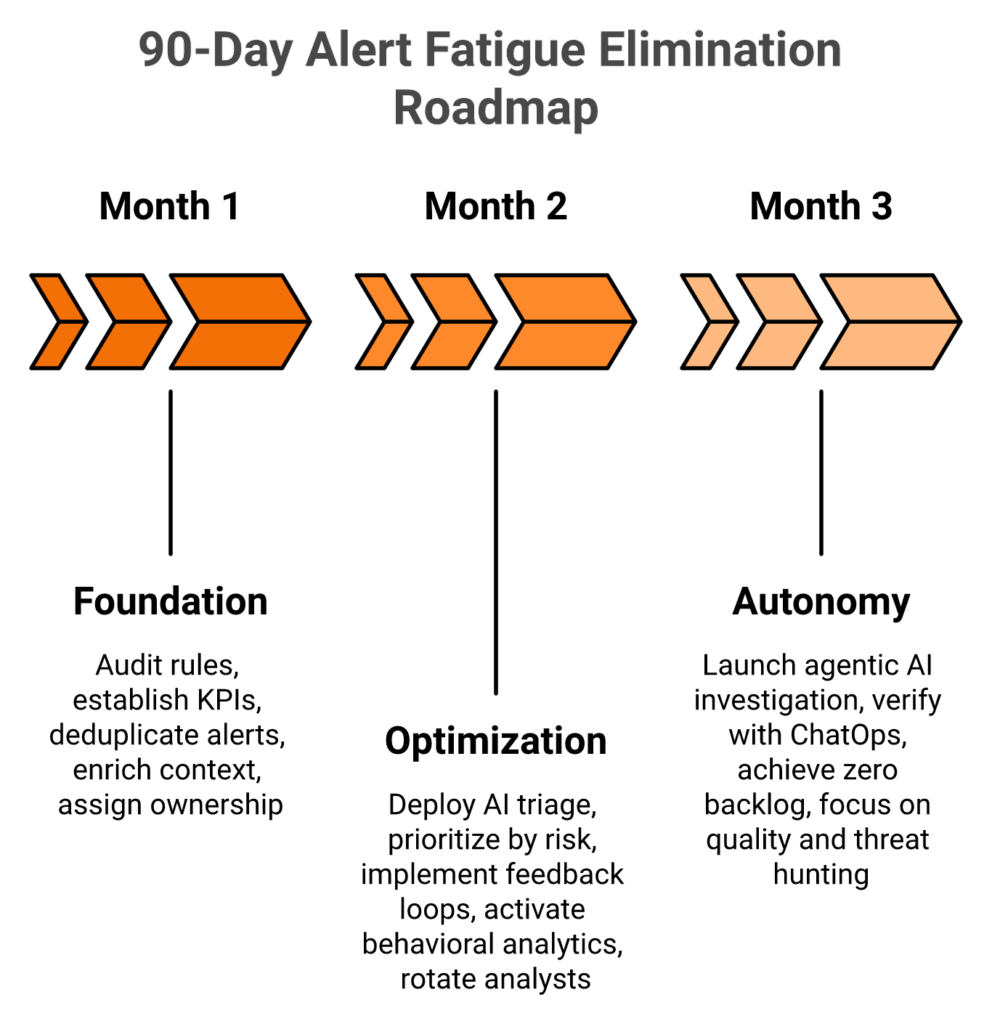
Phase 1: Foundation (Month 1)
- Conduct a detection rule audit across all alert sources
- Baseline all KPIs: current false positive rate, MTTD, MTTR, alert-to-incident ratio, and analyst satisfaction score
- Implement alert deduplication and basic suppression for known benign patterns
- Assign detection rule ownership to specific engineers (no orphaned rules)
- Deploy context enrichment for the top-20 highest-volume alert types
- Begin SOAR playbooks for the 5 most repetitive alert categories
Phase 2: Optimization (Month 2)
- Deploy AI-powered triage across all alert sources
- Implement risk-based prioritization with asset criticality scoring
- Activate feedback loops: analyst verdicts → detection engineering with 7-day SLA
- Begin behavioral analytics to replace signature-based rules where appropriate
- Consolidate overlapping tool coverage to reduce duplicate alerts
- Launch the analyst rotation schedule from the cognitive load management playbook
Phase 3: Autonomy (Month 3)
- Activate agentic AI investigation for full autonomous enrichment-correlation-verdict workflow
- Implement ChatOps user verification for identity-based alerts
- Establish zero alert backlog as the operational target
- Transition analyst KPIs from throughput to quality metrics
- Launch proactive threat hunting program with reclaimed analyst capacity
- Set quarterly re-audit schedule for continuous improvement
⭐ Eight Evaluation Criteria for Alert Management Platforms
Score each platform 0–2 per criterion. Platforms scoring 12+ out of 16 represent genuine operational partnership.
| # | Criterion | What to Look For |
|---|---|---|
| 1 | Vendor-agnostic integration | Works with existing SIEM, EDR, cloud, and identity stack, or requires proprietary replacement? |
| 2 | Investigation depth | Conducts full investigations (enrichment + correlation + context), or just prioritizes the queue? |
| 3 | Organizational context reasoning | Incorporates who the user is, what they do, and whether this activity is normal for them? |
| 4 | User verification capability | Contacts affected users directly via collaboration tools to verify suspicious activity? |
| 5 | Feedback loop automation | Analyst verdicts automatically improve future detection and investigation quality? |
| 6 | Compliance evidence generation | Produces audit-ready documentation mapped to regulatory frameworks automatically? |
| 7 | Deployment speed | Operational within 30 days, or requires 6-month professional services? |
| 8 | Pricing transparency | Published, predictable per-endpoint costs, or hidden behind “contact sales”? |
📋 KPIs to Measure Success: Before vs. After Benchmarks
| Metric | Before (Industry Baseline) | Target (Post-Implementation) |
|---|---|---|
| False Positive Rate | 60–80% | <20% |
| MTTD (Mean Time to Detect) | 197 days (industry average) | <24 hours |
| MTTR (Mean Time to Respond) | Hours to days | <15 minutes for critical |
| Alert-to-Incident Ratio | 1000:1 | 50:1 or better |
| Analyst Satisfaction Score | Survey baseline | >30% improvement |
| Analyst Turnover Rate | 35%+ (industry) | <15% |
| Proactive Hunting Time | <10% of analyst time | >50% |
| Alert Backlog | Hundreds to thousands daily | Zero sustained backlog |
The operational goal is not faster triage but no triage. When agentic AI investigates and resolves routine alerts autonomously, and only escalates confirmed threats requiring human decision, the alert backlog ceases to exist as a concept.
The Future of Alert Management
The trajectory is clear: from alert triage (human sorts through noise) to threat resolution (AI investigates, human decides, system acts). Continuous adaptive AI means the system improves with every alert processed. Every false positive verdict, every confirmed threat, and every analyst correction trains the model. Within 12–18 months of deployment, mature agentic AI systems achieve investigation accuracy levels that approach experienced Tier 2 analysts for routine alert types, while maintaining 24/7 consistency that human teams cannot.
UnderDefense MAXI’s 30-day onboarding maps directly to Month 1 of this roadmap: detection rule audit, baseline measurement, context enrichment deployment, and AI triage activation. Most organizations complete all three months’ objectives within the first 30 days because the agentic AI platform handles Months 2–3 activities concurrently with foundation work.
Q12. What Are the Best SOC Tools and Platforms for Eliminating Alert Fatigue?
The most effective SOC tools for eliminating alert fatigue in 2026 span five categories: AI SOC platforms (UnderDefense MAXI), SIEM with advanced correlation (Splunk, Microsoft Sentinel, and Chronicle), SOAR for playbook automation (Swimlane and Tines), XDR for telemetry consolidation (CrowdStrike Falcon and Palo Alto Cortex), and MDR services for outsourced investigation (UnderDefense, Arctic Wolf, and Expel). The right combination depends on your existing stack, team size, and whether you need augmentation or full outsourcing.
Why No Single Tool Solves Alert Fatigue
Alert fatigue elimination requires tools that address all five fatigue types identified in this article: volume, false positives, context starvation, tool-switching, and repetitive alerts. No single tool category solves all five. The architectural differentiator is whether the platform investigates alerts (agentic AI) or just prioritizes them (traditional automation).
Selection Criteria Preview
What separates tools that eliminate fatigue from tools that just manage it:
- Investigation capability: Does it conduct full investigations or just re-sort the queue?
- Vendor-agnostic integration: Does it work with your existing 250+ tools or force replacement?
- Organizational context: Can it reason about who the user is and whether this is normal for them?
- User verification: Can it contact affected users directly via Slack/Teams/email?
- Published response SLAs: Documented MTTR vs. vague “faster response” claims
- Compliance evidence: Automatically generated audit documentation vs. separate tools required
- Transparent pricing: Published per-endpoint rates vs. “contact sales for quote”
Where Each Tool Excels
Each tool excels in different scenarios: Splunk for organizations deeply invested in custom detection engineering, CrowdStrike for Falcon-native environments, and UnderDefense MAXI for teams that want agentic AI investigation layered onto their existing stack without vendor lock-in. The detailed comparison below evaluates the top SOC tools across all criteria with pricing, features, and deployment considerations.
This analysis is based on documented response times, G2 Spring 2026 rankings, published pricing, MITRE ATT&CK evaluations, and operational outcomes across 500+ MDR deployments managing 65,000+ endpoints.
1. What is alert fatigue in cybersecurity, and why is it getting worse in 2026?
Alert fatigue in cybersecurity is the cognitive, operational, and human exhaustion that occurs when SOC analysts face an overwhelming volume of security alerts, most of which turn out to be false positives, duplicates, or low-context noise. The result is desensitization: analysts begin psychologically defaulting to “probably benign,” causing real threats to slip through undetected.
The problem is escalating in 2026 for three compounding reasons. First, Forrester reports SOC teams now receive an average of 11,000 alerts per day, while only 22 per analyst require genuine investigation. Second, the global cybersecurity talent gap sits at 3.5 million unfilled positions, meaning most SOCs operate well below required headcount. Third, attackers have weaponized agentic AI, collapsing the barrier to sophisticated attacks and generating more intrusion attempts than ever before.
We’ve observed across hundreds of SOC environments that alert fatigue operates across three dimensions: cognitive (degraded decision-making after repetitive exposure), operational (queue backlogs that turn triage into checkbox-clearing), and human (burnout driving 28% annual analyst turnover). This is not a volume problem you can hire your way out of. It’s an architectural failure in how security tools generate and present signals to human decision-makers. Our SOC service addresses all three dimensions simultaneously.
2. What are the main types and root causes of alert fatigue in a SOC?
We classify alert fatigue into five distinct types, each with different root causes and tool sources. Volume-based fatigue occurs when alert quantity exceeds human processing capacity regardless of quality. False positive fatigue emerges from repeated investigation of benign alerts, eroding analyst trust. Context starvation fatigue happens when alerts lack enough information for a decision. Tool-switching fatigue represents the cognitive cost of pivoting between multiple disconnected security tools. Repetitive/duplicate fatigue occurs when the same event fires alerts in overlapping tools.
Behind these five types, we’ve mapped nine structural root causes across client environments: poorly tuned detection rules, tool sprawl and integration gaps, insufficient alert context, alert volume exceeding cognitive capacity, staffing shortages, lack of risk-based prioritization, vendor-default detection rules never customized, no feedback loop between analysts and detection engineering, and KPIs rewarding throughput over investigation quality.
Most organizations suffer from five to seven root causes simultaneously, which is why point fixes like “just tune the SIEM” consistently fail. We recommend mapping your alert queue against these five types for one week. Most SOCs discover that two to three types account for 80% of their fatigue. That’s where your remediation effort should begin. Our managed SIEM service helps identify which root causes are active in your specific environment.
3. How does alert fatigue impact compliance with frameworks like HIPAA, GDPR, and PCI DSS?
Alert fatigue creates direct, auditable compliance failures across every major regulatory framework. When alerts go uninvestigated, your organization violates specific security controls that assessors will verify during audits. An assessor won’t accept “we had too many alerts” as an explanation for a breach that went undetected for 60 days.
The compliance exposure spans nine frameworks simultaneously. NIST CSF requires continuous monitoring (DE.CM) and response analysis (RS.AN), both of which uninvestigated alerts violate. ISO 27001 controls A.12.4 and A.16.1 are directly undermined when logging exists without investigation. PCI DSS Req 10.6 requires daily log review, meaning auto-closing 80% of alerts without investigation violates the requirement by definition. HIPAA §164.312(b) audit controls create direct liability when uninvestigated alerts exist on systems containing protected health information. GDPR Article 33 requires breach notification within 72 hours, which becomes impossible when extended dwell time from fatigue delays detection.
What makes this especially dangerous is the compounding effect. A single missed phishing alert can trigger failures across HIPAA, NIST CSF, and GDPR simultaneously. Our compliance services include forever-free compliance kits that automatically generate audit evidence mapped to all nine frameworks.
4. How do attackers deliberately exploit alert fatigue to bypass SOC defenses?
Sophisticated threat actors have figured out that the best way past a SOC is to drown real attacks in a flood of noise that analysts are conditioned to ignore. When your team auto-clears 80% of alerts without investigation, attackers only need their malicious activity to resemble the other 80%.
We’ve documented five exploitation methods. Alert storming (MITRE T1498/T1046) involves deliberately triggering hundreds of low-severity alerts via port scans and brute-forcing to overwhelm the SOC while the real intrusion targets a high-value asset. Shift-change timing launches primary attack phases during analyst handoff windows (6–8 AM and 6–8 PM) when 15- to 30-minute coverage gaps are predictable. SEO poisoning and fake browser prompts train the SOC to auto-dismiss the exact alert category that advanced phishing chains exploit. Living-off-the-land techniques use legitimate admin tools (PowerShell, WMI, certutil) to generate alerts indistinguishable from normal IT activity. Tool blind-spot exploitation targets seams between security tools where no single tool sees the composite attack.
Defending against this requires cross-telemetry correlation with organizational context. UnderDefense MAXI correlates signals across endpoint, identity, cloud, network, and email at machine speed, connecting low-severity alerts across tools that together constitute a coordinated intrusion.
5. What is the best technology to solve alert fatigue: SIEM tuning, SOAR, MDR, XDR, or AI SOC?
Each technology addresses only one dimension of alert fatigue while creating new problems. SIEM tuning improves foundational rule quality but requires dedicated detection engineers and doesn’t speed investigation. SOAR automates known playbooks but is brittle to novel threats and creates “playbook maintenance fatigue.” MDR outsources analyst workload 24/7 but many providers just forward alerts (the monitoring-only trap). XDR consolidates telemetry but often forces vendor lock-in. AI SOC platforms offer agentic investigation and adaptive learning, but maturity varies wildly; some are SOAR with an AI label.
For the past five years, SOAR was positioned as the answer. It didn’t work. Organizations that deployed SOAR still report 60–70% false positive rates and persistent burnout because SOAR can’t reason about novel attack patterns, can’t incorporate organizational context (it doesn’t know Jane is the CFO traveling in Singapore), and creates new “playbook maintenance fatigue.”
The architectural differentiator is whether the platform investigates alerts or just prioritizes them. Agentic AI conducts full investigations: querying your SIEM, enriching with threat intelligence, correlating across data sources, and delivering structured reports in seconds. We built UnderDefense MAXI on this principle: augment analysts with machine-speed investigation without replacing their judgment. Compare your options with our MDR buyers guide.
6. How can we reduce SOC analyst burnout caused by alert fatigue?
SOC analyst average tenure sits at 18–24 months, among the shortest in all of IT. According to the Tines Voice of the SOC Analyst report, 71% of SOC analysts experience burnout, and 64% are considering leaving their roles within a year. Each departed analyst represents approximately $75K in replacement costs and six months of degraded coverage. This is not a people problem but a system design failure.
We recommend eight interventions that actually work. Cognitive load rotation: alternate analysts between triage, threat hunting, detection engineering, and incident response on weekly cycles. Shift design: implement follow-the-sun models or AI-augmented night shifts to eliminate 3 AM human triage. Feedback loops with SLA: every false-positive verdict generates a tuning request with a seven-day implementation SLA. KPI transformation: replace “alerts closed per shift” with investigation quality metrics. Career path architecture: create advancement tracks (Analyst → Detection Engineer → Threat Hunter → SOC Architect) within operations. Recognition systems, HR communication, and cross-training investment round out the playbook.
Technology alone doesn’t solve burnout, but the right technology removes the conditions that cause it. When agentic AI handles the 80% that’s mechanical, analysts apply their expertise to the 20% that’s genuinely interesting. Organizations using AI-augmented SOC models report 40% lower analyst turnover.
7. How do you audit detection rules to reduce false positives at the source?
Every article about alert fatigue says “tune your SIEM.” None tell you how. We use a 10-step detection rule audit that your detection engineering team can execute quarterly. It is the single highest-ROI activity for reducing alert fatigue, fixing noise at the source rather than filtering it downstream.
The core philosophy: only alert on events you can take action on. If a detection rule fires and the standard response is “investigate and probably close,” that rule is noise, not detection. The 10 steps are: inventory all active detection rules across all sources, calculate signal-to-noise ratio per rule over 90 days, map each rule to MITRE ATT&CK technique coverage, assign named ownership for every rule, score each rule on fidelity/coverage/freshness/actionability (1–5 scale each), triage results (rules under 8/20 are retirement candidates), implement context enrichment for surviving rules, deduplicate overlapping rules, establish a formal feedback loop with seven-day SLA, and schedule quarterly re-audits.
Our 30-day onboarding includes a complete detection rule audit across your existing SIEM and EDR stack. Our detection engineers typically identify 40–60% of active rules as candidates for retirement or consolidation, then deploy custom rules mapped to your specific threat profile with 96% MITRE ATT&CK technique coverage.
8. What does a 90-day roadmap to eliminate alert fatigue look like?
Eliminating alert fatigue requires a phased 90-day execution plan addressing technology, process, and people simultaneously. Attempting all three at once creates change fatigue on top of alert fatigue. We sequence the highest-ROI activities first across three phases.
Phase 1, Foundation (Month 1): conduct a detection rule audit across all alert sources, baseline all KPIs (false positive rate, MTTD, MTTR, alert-to-incident ratio, analyst satisfaction), implement alert deduplication and basic suppression, assign detection rule ownership, deploy context enrichment for the top-20 highest-volume alert types, and begin SOAR playbooks for the five most repetitive categories.
Phase 2, Optimization (Month 2): deploy AI-powered triage across all alert sources, implement risk-based prioritization with asset criticality scoring, activate analyst feedback loops with seven-day SLA, begin behavioral analytics, consolidate overlapping tool coverage, and launch analyst rotation schedules.
Phase 3, Autonomy (Month 3): activate agentic AI investigation for full autonomous workflows, implement ChatOps user verification, establish zero alert backlog as the operational target, transition KPIs from throughput to quality, and launch proactive threat hunting with reclaimed analyst capacity. UnderDefense MAXI’s 30-day onboarding maps directly to Month 1, and most organizations complete all three phases within 30 days because the agentic AI platform handles Months 2–3 concurrently.