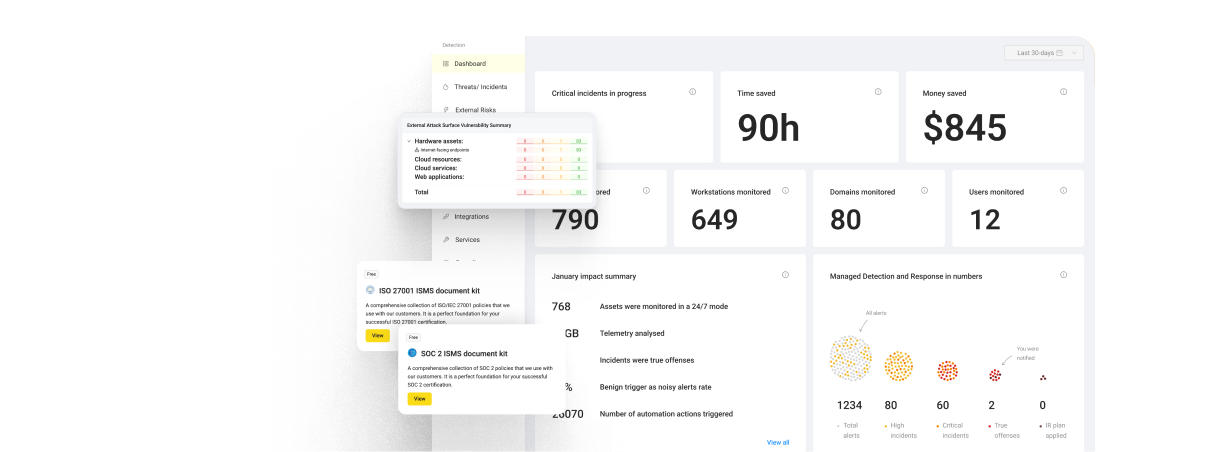
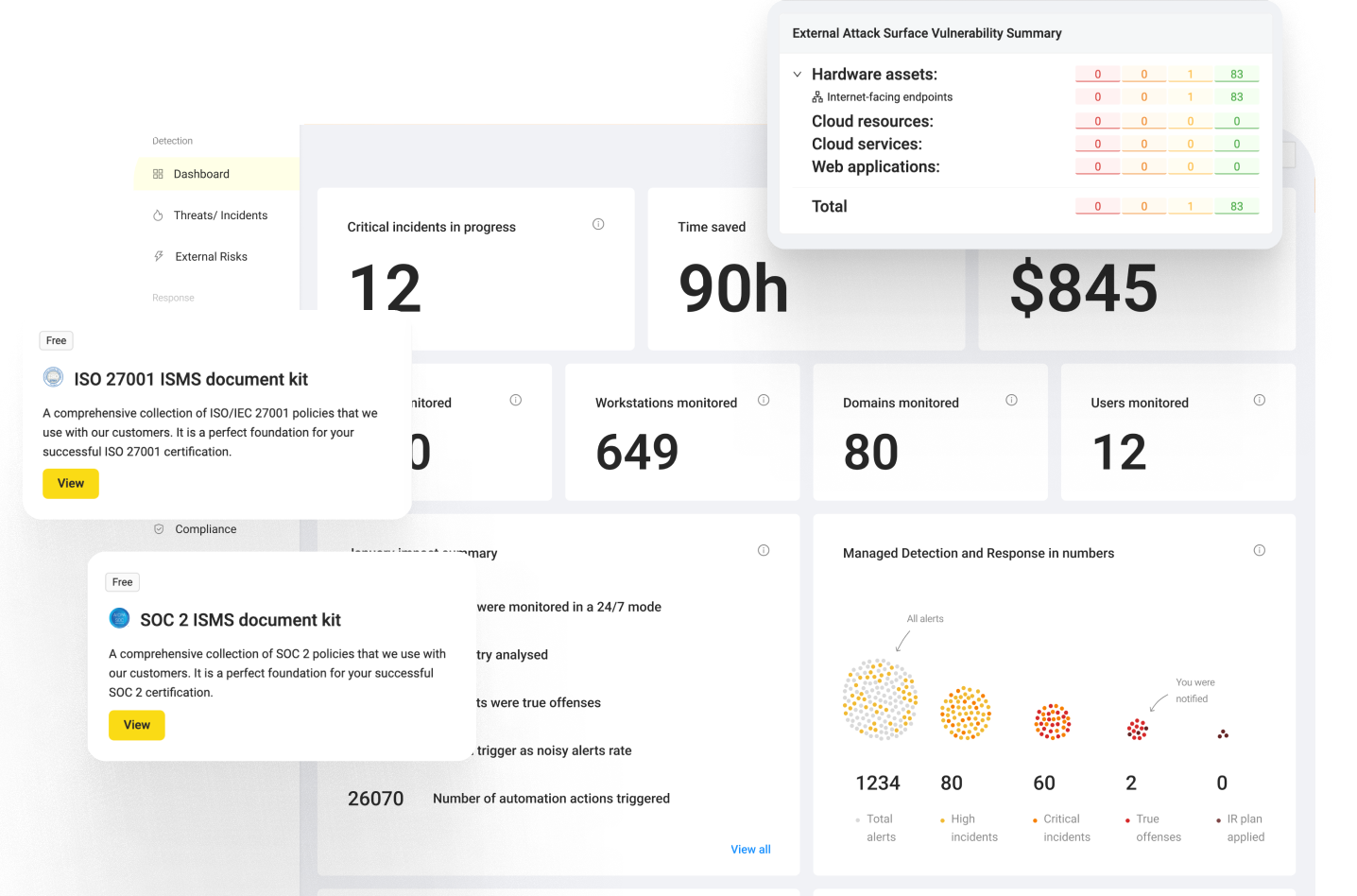
Q1. What is automated threat detection in 2026, and why has the definition changed?
Automated threat detection in 2026 is the use of agentic AI workflows that autonomously collect evidence, correlate signals across SIEM, EDR (Endpoint Detection and Response), identity, and cloud, and execute containment actions like credential wipes and user logouts in under two minutes, with human Tier 3 to Tier 4 analysts retained as final decision-makers. It is no longer rule-based alerting bolted onto a SIEM. That approach lost the speed race the moment threat actors weaponized AI for reconnaissance.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
The old workflow versus the new one
A 2022-era “automated” detection looked like this. A SIEM rule fires. A ticket lands in a queue. A Tier 1 analyst opens it forty minutes later. They paste an IP address into VirusTotal, then into the EDR console, then into the identity provider. They write three sentences in the ticket. They escalate.
An agentic workflow in 2026 looks different. The same signal fires. An AI agent pulls the EDR process tree, the identity sign-in logs, the DNS query history, and the cloud audit trail in parallel. It correlates them in seconds. It pings the user on Slack: “Did you just run this PowerShell on FIN-LAPTOP-217?” If the answer is no, it kills the session, resets the password, and writes a structured incident report. The human analyst reviews and signs off. That is the floor in 2026, not the ceiling. For teams comparing operating models, our guide to MDR services walks through how this floor shifts buying decisions.
Why the definition shifted under our feet
Threat actors have weaponized AI to become faster, more automated, and frankly less skilled. The 2024 Verizon Data Breach Investigations Report found that the median time-to-exploit a published vulnerability dropped to under five days. MITRE ATT&CK v15 added new sub-techniques specifically for credential abuse and identity-based lateral movement, because that is where modern attackers live. Defenders running manual triage at human speed have already lost this race.
✅ Real automated threat detection collects evidence, correlates, and contains.
❌ “AI-washed” automated threat detection just renames the same SIEM rules with an LLM (Large Language Model) chat box on top.
Most of what gets sold as “AI SOC” in 2026 is the second category. We rebuilt UnderDefense Agentic AI SOC around agentic workflows specifically because the rebadge approach delivers no measurable noise reduction and no real MTTR (Mean Time to Respond) compression. Working with 500-plus customer environments, what I have noticed is a brutal pattern. The teams winning are not the ones with the fanciest dashboards. They are the ones whose AI agents do work a Tier 1 analyst used to do, while the humans focus on judgment calls. That is the bar. Most products called “AI SOC” do not clear it. For a sharper red-flag list, see AI SOC red flags.
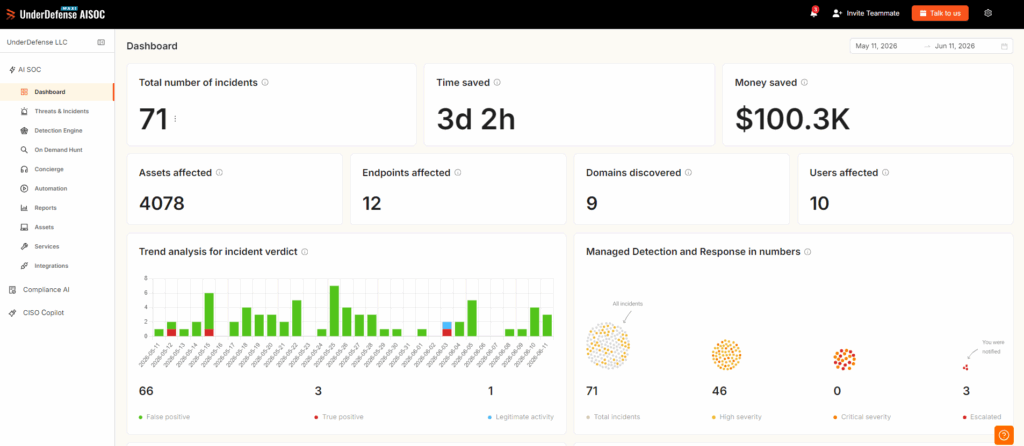
Q2. How does an AI-driven SOC actually reduce MTTR by 80%, phase by phase?
AI-driven SOCs cut MTTR by attacking each lifecycle phase separately. Detection latency drops via streaming analytics. Triage drops 90 percent or more via automated enrichment. Investigation collapses from hours to seconds via agentic log correlation. Containment runs in under two minutes via autonomous response. The 80 percent headline is real only when all four phases are automated together. Automating detection alone usually moves the needle by 15 to 25 percent.

The four sub-phases of MTTR most vendors quietly ignore
When a vendor tells you “we cut MTTR by 80 percent,” ask which phase. Most cannot answer. The 2024 IBM Cost of a Data Breach Report found that organizations using AI and automation extensively identified and contained breaches 108 days faster than those without, and saved an average of 1.88 million dollars per breach. Mandiant M-Trends 2024 reported a global median dwell time of ten days, down from 16, almost entirely driven by automated triage and EDR coverage. For the math behind these phases, our breakdown of SOC metrics, including MTTD and MTTR, is worth a read.
Where automation actually compresses the clock
| MTTR Phase | What happens here | Automation lever | Realistic % reduction |
|---|---|---|---|
| Detection latency ⏰ | Signal-to-alert | Streaming analytics, behavioral baselines | 30 to 50 percent |
| Triage | Alert-to-investigation start | Auto-enrichment, deduplication, ChatOps | 85 to 95 percent |
| Investigation | Hypothesis-to-evidence | Agentic log correlation, multi-system queries | 70 to 90 percent |
| Containment | Decision-to-action | Pre-approved playbooks, autonomous response | 60 to 80 percent |
We hold an internal 2-minute Alert-to-Triage SLA on UnderDefense Agentic AI SOC, with a 15-minute escalation for critical incidents. Commoditized managed SOC partners often run 30 to 60 minutes for the same step. That gap is the entire ballgame when the SEC Cyber Disclosure Rule (Item 1.05 of Form 8-K) gives you four business days to determine materiality and disclose. MTTR is no longer just an ops metric. It is a legal liability clock. Our case study on how MDR reduced MTTR to 9 minutes for a US government organization shows the same SLA pattern in production.
What is realistic in Year 1 versus Year 3
I might be wrong here, but in our experience onboarding mid-market enterprises, Year 1 typically lands at 40 to 55 percent MTTR reduction. The 80 percent number shows up in Year 2 or Year 3, after detection-as-code is in place, after ingestion is tuned, and after the response playbooks have been battle-tested. Anyone promising 80 percent in 90 days is selling you a deck, not a SOC.
A CISO at a US healthcare network told me last quarter, “We do not need faster alerts. We need fewer decisions.” That is the right framing. Reduce decisions, not just seconds. For the deeper SLA breakdown, our piece on SLA in cybersecurity covers the contract-level math.
Q3. Which AI/ML techniques actually power modern threat detection: UEBA, NLP, anomaly detection, and agentic reasoning?
Four AI/ML technique families do the real work. Supervised ML handles known-signature classification at 95 to 99 percent accuracy on known threats, with up to a 40 percent drop on adversarially crafted inputs. UEBA (User and Entity Behavior Analytics) catches insider threats and lateral movement via behavioral baselines. NLP and LLMs (Large Language Models) summarize logs and generate playbooks. Agentic reasoning chains multi-step investigations. None are autonomous truth-tellers. AI is correct in roughly 30 percent of security cases on its own, which is why Tier 3 to Tier 4 human oversight is non-negotiable.
Supervised ML and anomaly detection: strong on known, fragile on novel
Supervised models are great at “I have seen this malware family before.” They are weak the moment an attacker mutates the binary or shifts the call pattern. A 2023 USENIX Security paper on adversarial evasion against deep-learning-based intrusion detection showed performance drops of 30 to 45 percent on perturbed inputs. That is not a rounding error. That is the gap attackers walk through.
Where each technique earns its keep
| Technique | Best at | Weakest at | Where it sits in the kill chain |
|---|---|---|---|
| Supervised ML ⭐ | Known malware, known IOCs | Novel and adversarial samples | Initial Access, Execution |
| Anomaly Detection | Statistical outliers, beaconing | High false positives without context | Command and Control |
| UEBA | Insider threats, lateral movement | Cold-start on new users | Lateral Movement, Privilege Escalation |
| NLP / LLMs | Log summarization, playbook drafting | Hallucinations on edge cases | Reporting, Analyst assist |
| Agentic reasoning | Multi-step investigation, correlation | High-stakes irreversible decisions | Investigation, Containment |
UEBA catches the attackers who hide in business hours
Attackers in 2026 are smart enough to operate at 2 a.m. local time, when 9-to-5 admins are asleep. They are also smart enough to operate at 11 a.m., looking exactly like a normal user. UEBA models learn that “Maria in finance” never opens PowerShell, never logs in from Lagos, and never touches the GitHub admin console. When “Maria” suddenly does all three in twenty minutes, the model fires. The 2024 SANS SOC Survey found that UEBA-driven detections had a 3.2x higher true-positive rate than rule-based detections in mature SOCs.
NLP, LLMs, and the 30 percent ceiling
LLMs are excellent at writing the report. They are terrible at deciding whether to lock out the CFO during an earnings call. An IEEE 2024 systematization of knowledge on deep learning for cybersecurity flagged hallucination rates of 8 to 22 percent on security-specific reasoning tasks. That is why we use ChatOps to “break the fourth wall.” When the AI is unsure, UnderDefense Agentic AI SOC pings the actual user on Slack or Teams: “Did you just authorize this?” That single move closes the context gap that no model can close on its own.
What my experience of shipping UnderDefense Agentic AI SOC tells me is this. AI is an accelerator, not an oracle. Treat it that way and you win. Treat it as a decision-maker and you will roll dice on production. For a longer view on this trade-off, our piece on whether AI kills or saves your SOC team is worth the read.
Q4. What does an agentic AI threat detection architecture look like, and how does it differ from SIEM, SOAR, XDR, and MDR?
An agentic AI architecture has five layers. Ingestion tuning filters 50 to 90 percent of low-value telemetry. A detection-as-code engine versions rules in Git. An agentic investigation layer queries logs and correlates across systems. An autonomous response layer executes pre-approved containment. A human Tier 3 to Tier 4 oversight loop governs the irreversible calls. SIEM is the data lake. SOAR (Security Orchestration, Automation, and Response) is the playbook engine. XDR (Extended Detection and Response) is cross-layer telemetry. MDR (Managed Detection and Response) is outsourced eyes. Agentic AI SOC is the orchestrator that ties all four into outcomes.
The five layers, explained without jargon
Think of your security stack like a restaurant kitchen. The SIEM is the pantry. The EDR is the stove. The SOAR is the recipe book. Without a chef, none of it cooks.
Layer 1: Ingestion tuning 💰 filters the pantry before you pay for storage. Most SIEM bills are 40 to 70 percent waste. We routinely cut customer ingestion by 50 to 90 percent on the first pass. Our managed SIEM service is built around this single lever.
Layer 2: Detection-as-code keeps your recipes versioned, peer-reviewed, and tested. Sigma rules in Git, deployed via CI/CD (Continuous Integration / Continuous Deployment).
Layer 3: Agentic investigation is the chef. It pulls ingredients from every shelf and tells you what is on the plate.
Layer 4: Autonomous response is the waiter. It serves containment actions like credential wipes and session kills inside a 2-minute Alert-to-Triage SLA.
Layer 5: Human oversight ⭐ is the head chef. The senior analyst signs off on anything irreversible.
How the operating models actually compare
| Capability | SIEM | SOAR | XDR | MDR | Agentic AI SOC |
|---|---|---|---|---|---|
| Data lake | ✅ | ❌ | Partial | Vendor-dependent | ✅ (BYO) |
| Playbook automation | ❌ | ✅ | Partial | ✅ | ✅ |
| Cross-layer correlation | Manual | Scripted | ✅ | Vendor-locked | ✅ (vendor-agnostic) |
| Human analyst response | ❌ | ❌ | ❌ | ✅ | ✅ |
| Autonomous containment | ❌ | Limited | Limited | Rare | ✅ (under 2 min) |
| Detection-as-code | DIY | DIY | Vendor-locked | Hidden | ✅ |
| Use case | Storage and search | Workflow automation | Single-vendor telemetry | Outsourced 24/7 | Outcomes, not alerts |
The 2024 Gartner Magic Quadrant for SIEM noted that buyers increasingly want “platform consolidation without vendor lock-in,” which is exactly the gap pure-XDR plays cannot fill. Forrester’s 2024 Wave for MDR flagged “transparency of investigation evidence” as the fastest-rising buyer requirement. For a buyer-side decision frame, our MDR buyers guide walks through the same questions.
The Ferrari in the SOC paradox
I have walked into Fortune 500 SOCs that own Splunk Enterprise Security, Microsoft Sentinel, and CrowdStrike Falcon, and still cannot answer “did this user click that link.” They bought Ferraris. Nobody learned to drive them. MITRE D3FEND maps defensive techniques to ATT&CK adversary behaviors, but the framework only pays off if someone is actually wiring rules to it.
BYO stack integration: preserve what you already paid for
When we deploy UnderDefense Agentic AI SOC, we do not ask you to rip out Splunk or Sentinel or CrowdStrike. We sit on top. We tune the ingestion. We write the detection-as-code. We run the agentic investigations against your existing data. We respond. You keep your data, your contracts, and your sunk cost. That is the whole point of a vendor-agnostic agentic layer. The “rip and replace” pitch from single-vendor XDR plays sounds clean on a slide, but it costs 18 months and seven figures in practice. ❌
✅ Keep your SIEM.
✅ Keep your EDR.
✅ Add the chef, the waiter, and the head chef.
❌ Do not buy another pantry.
For a deeper look at the integrations that make this BYO model real, see the WarRoom platform page.
Q5. How do you map detection rules to MITRE ATT&CK and build a Detection-as-Code pipeline (with a Sigma rule example)?
Treat detection logic as software. Write rules in Sigma or Python, version control them in Git, peer review through pull requests, run automated unit tests against red team simulations, and ship through CI/CD. Tag every rule to a specific MITRE ATT&CK sub-technique to expose silent gaps where attackers operate at night to dodge 9 to 5 admins. Detection-as-Code teams cut false positives by 35 to 60 percent versus static, hand-edited rules.
Why “wall poster ATT&CK” stops working at scale
Most SOCs I walk into still treat MITRE ATT&CK as decoration. It hangs on the wall, but no rule in their SIEM (Security Information and Event Management platform) is tagged to a sub-technique. That breaks the moment a CISO asks, “what is our coverage for TA0008 lateral movement?” Without a tag map, the honest answer is, “I do not know.”
The shift is simple. Every detection becomes code. Every code change has a reviewer. Every release runs through tests. That is Detection-as-Code (DaC). For the orchestration patterns that wrap this discipline, our piece on SOC automation walks through the CISO checklist.
The five-step DaC pipeline I recommend on Monday morning
- ✅ Author the rule in Sigma, the open, vendor-neutral detection format maintained by SigmaHQ.
- ✅ Commit the rule to Git with a YAML front matter that includes the ATT&CK tactic and technique IDs.
- ✅ Open a pull request. A second engineer reviews logic, false-positive risk, and coverage overlap.
- ✅ CI runs the rule against a corpus of recorded attack telemetry (Atomic Red Team, Caldera output, and real IR samples).
- ✅ On merge, the converter pushes the rule into your SIEM, EDR (Endpoint Detection and Response), or XDR (Extended Detection and Response) backend.
This is the same release discipline software teams have used for a decade. Security is finally catching up. If you operate inside Splunk, our MDR for Splunk deployment uses this exact pattern out of the box.
A working Sigma rule for credential dumping (T1003.001)
title: Suspicious LSASS Memory Access via Common Tools
id: 9e2b1c44-1f8e-4a8a-9b41-2f3a1c7e0001
status: stable
description: Detects access to LSASS process memory, a common credential dumping pattern.
author: UnderDefense Detection Engineering
date: 2026/02/10
tags:
- attack.credential_access
- attack.t1003.001
logsource:
category: process_access
product: windows
detection:
selection:
TargetImage|endswith: '\lsass.exe'
GrantedAccess:
- '0x1010'
- '0x1410'
filter_legit:
SourceImage|endswith:
- '\MsMpEng.exe'
- '\wmiprvse.exe'
condition: selection and not filter_legit
falsepositives:
- Endpoint protection tools doing legitimate scans
level: highThe tags block is the heartbeat. Pipe Git into a coverage script, and you can render an ATT&CK heatmap that shows which sub-techniques have one rule, three rules, or none.
The heatmap conversation that scares boards
Most heatmaps look strong on Initial Access and Execution. They go quiet on Lateral Movement (TA0008), Defense Evasion (TA0005), and Command and Control (TA0011). That silence is the gap. Attackers move at 2 a.m. through SMB, WMI, and remote services, and a 9 to 5 admin team will not see it unless rules and analysts are watching those paths.
The Silent Pen Test, in our words
We had a prospect who ran a full red team engagement against their existing managed detection and response (MDR) provider. Lateral movement across three subnets. Credential reuse. New service install. Zero alerts. The MDR dashboard stayed quiet through the entire test. After we onboarded them onto UnderDefense Agentic AI SOC, we rebuilt their detection set as code, mapped every rule to ATT&CK, and ran the same simulation. Twelve high-fidelity alerts in under four minutes. Silence is not safety, but missing telemetry plus untagged rules. For teams worried about the same blind spots, our penetration testing service runs this exact validation.
“The biggest win for me was getting actual control over our security alerts. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified Marketing & Advertising User UnderDefense G2 – Verified Review
“Lack of true remediation in the response, costing us significantly in resources and introducing risks in security.”
— VP of Technology, Services Arctic Wolf – Gartner Verified Review
Q6. What does threat hunting automation actually automate, and where must humans stay in the loop?
Automate the mechanical 90 percent. That means querying SIEM, pulling logs, correlating identities across systems, and generating structured investigation reports. Leave hypothesis generation, contextual judgment, and the final call to senior analysts. The F3EAD model (Find, Fix, Finish, Exploit, Analyze, and Disseminate) draws the cleanest line. AI handles Find and Fix at machine speed. Humans own Exploit and Analyze. ChatOps closes the context gap by pinging users to validate suspicious activity.
F3EAD, translated for a SOC lead
F3EAD came from special operations intelligence work. SANS adapted it for incident response. Here is how each step splits in 2026.
- Find: AI scans telemetry, flags anomalies, and ranks by confidence. Fully automatable.
- Fix: AI pulls context, enriches with threat intel, and builds a timeline. Fully automatable.
- Finish: A senior analyst decides containment or escalation. Human owned.
- Exploit: Pull artifacts, IOCs (Indicators of Compromise), and TTPs (Tactics, Techniques, and Procedures) for hunting. Mixed.
- Analyze: Build the narrative. Human owned.
- Disseminate: Share findings, and update detections. Mixed.
Most “AI hunting” tools market Find and Fix as the whole product. That is half the loop. Our take on conversational SOCs covers why the missing half matters.
ChatOps, breaking the fourth wall
The hardest signal to grade in any SOC is “did this user actually do this?” Logs say a finance VP ran PowerShell at 11:47 p.m. UTC. Was it her, or a session token replay?
We solved this by pinging users directly through Slack, Teams, or SMS. “Hi Maria, did you run this PowerShell command on your laptop two minutes ago?” Most of the time she replies in 30 seconds. If she says no, UnderDefense Agentic AI SOC auto-isolates the endpoint and resets credentials. If yes, we close it. That single workflow kills hours of investigation grunt work.
“They’ve also made our audit process much less painful. The reports from their platform give us clear evidence of our security controls and incident response capabilities.”
— Verified Marketing & Advertising User UnderDefense G2 – Verified Review
The 30 percent ceiling, and why Tier 3 humans still decide
Working with hundreds of customer environments, what I have noticed is that AI gives a correct, complete answer in about 30 percent of investigation cases. The other 70 percent need context AI cannot see, like a planned penetration test, a new acquisition’s odd asset inventory, or a dev who just spun up Kali in a sandbox.
That is why senior analysts (Tier 3 and Tier 4) stay in the loop on Finish and Analyze. Automating their judgment is not a feature, but a liability. The right question is not “how do we replace them,” but “how do we give them ten times the throughput?” Our breakdown of outsourced vs in-house SOC is the deeper read on staffing this layer.
“Some alerts are just a regurgitation of Microsoft alerts which means duplicates.”
— Sr Cybersecurity Engineer, Manufacturing Arctic Wolf – Gartner Verified Review
Q7. How does autonomous response work in practice, and how do you align it with NIST SP 800-61?
Autonomous response works best for high-confidence, low-blast-radius actions. Credential wipes, password resets, user logouts, endpoint isolation, and malicious IP blocking. All executable in under two minutes when pre-approved playbooks are wired to detection signals. Mapped to NIST SP 800-61, AI handles Detection and Analysis plus most of Containment. Humans own Eradication, Recovery, and Post-Incident Activity. The governance line is reversibility. If reversible in under five minutes, automate it. If not, escalate.
Mapping autonomous actions to the NIST IR lifecycle
NIST SP 800-61 defines four phases for incident response: Preparation; Detection and Analysis; Containment, Eradication, and Recovery; and Post-Incident Activity. Here is how I split automation versus human ownership in 2026. Our IR plan template maps cleanly to this split.
| NIST Phase | Automate Now | Human Owned |
|---|---|---|
| Detection and Analysis | Alert triage, log enrichment, and IOC lookup | Hypothesis, novel TTP review |
| Containment | Isolate endpoint, kill session, block IP, and disable account | Network segmentation, business comms |
| Eradication | Quarantine known malware | Root cause confirmation, patch decisions |
| Recovery | Re-image from gold image (when pre-approved) | Restore decisions, data integrity sign-off |
| Post-Incident | Auto-generate timeline and report | Lessons learned, control updates |
The $300k accidental discovery
⚠️ One of our mid-market customers signed up expecting standard ransomware coverage. Three weeks in, UnderDefense Agentic AI SOC flagged an odd pattern. A payroll administrator’s account was creating ghost vendor records, then approving small wire transfers below the audit threshold.
Traditional malware-focused MDR would have ignored this. There was no payload, no C2 (Command and Control) beacon, and no ransomware. But our identity behavior rules picked it up. The autonomous response disabled the account in 90 seconds, alerted the CFO through ChatOps, and froze the pending wires. Final loss avoided: about $300,000. The service paid for itself in 90 days. Our incident response team owns this concierge model end to end.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified Program Development User UnderDefense G2 – Verified Review
Reversibility, the kill-switch governance test
The single rule I give CISOs designing autonomous response governance: ⏰ if the action is reversible in under five minutes, automate it. If not, escalate.
✅ Auto-execute: account lockout, session kill, IP block, and endpoint isolation.
❌ Escalate: domain controller reboot, mass password rotation, production service shutdown, and firewall rule change at the perimeter.
This single test prevents the worst autonomous-response failure mode, which is an AI that takes a confident but wrong action against business-critical infrastructure at 3 a.m. on a Saturday.
“Log collectors show working, however when asked to provide logs for an investigation no logs could be provided. Analysts provide little context.”
— CISO, Manufacturing Arctic Wolf – Gartner Verified Review
“24/7 protection at a good price. It’s reassuring to know they’re always watching for threats. They catch and stop problems quickly.”
— Serhii B., CISO UnderDefense G2 – Verified Review
Q8. How do you tell real Agentic AI from “AI-washed” MDR, and how do leading providers actually compare?
Real Agentic AI passes five tests. It shows the agent’s investigation reasoning. It version-controls detection rules. It executes autonomous containment, not just alerts. It publishes adversarial-evasion test results. And it operates on top of your existing SIEM and EDR rather than forcing rip-and-replace. AI-washed MDRs fail at least three of those tests. Ask any vendor to walk you through one real customer investigation transcript end to end. Black-box providers will refuse.
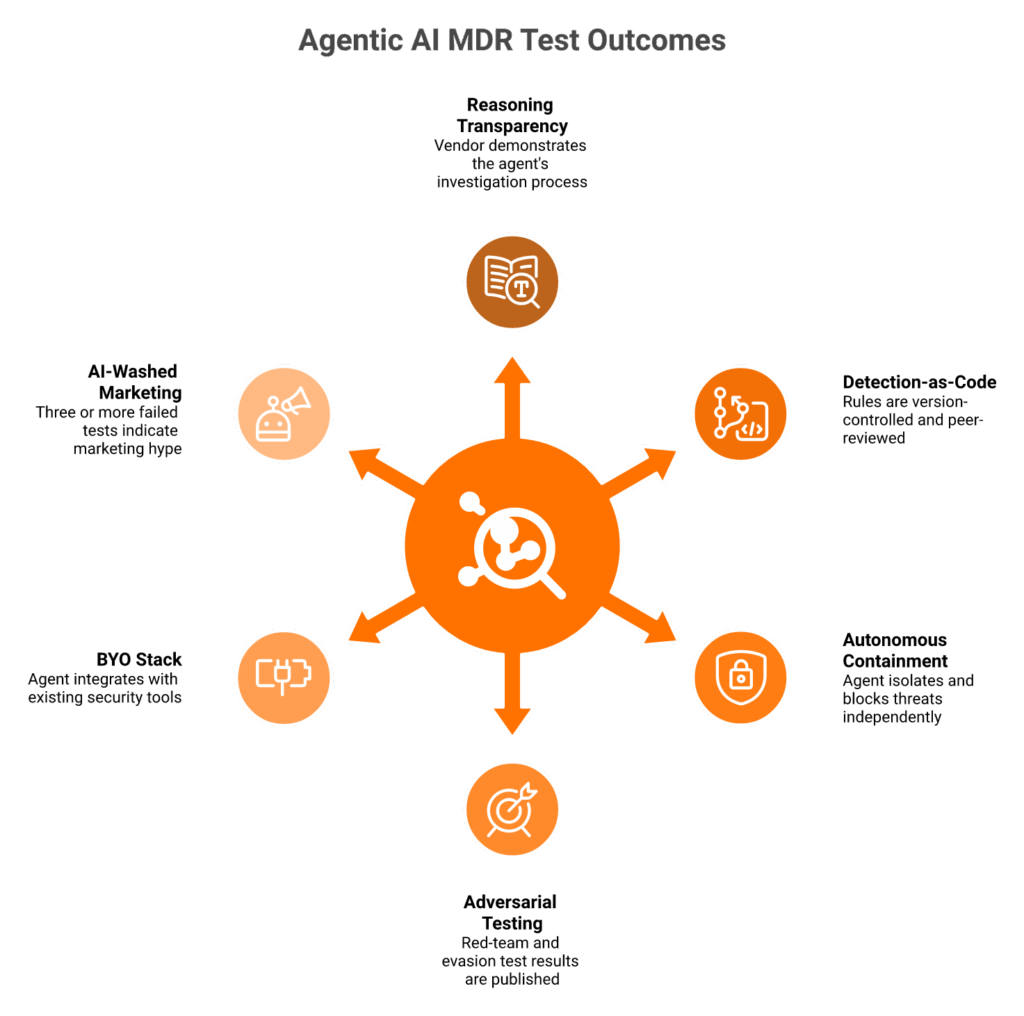
The 5-test rubric for buying meetings
Run every vendor through these five questions. Score honestly.
- ⭐ Transparency: Will they show you the agent’s chain of reasoning for a real investigation, redacted but complete?
- ⭐ Detection-as-Code: Are their rules version-controlled, peer reviewed, and ATT&CK-tagged?
- ⭐ Autonomous containment: Do they execute responses (isolate, lockout, and block) under SLA, or just send you a ticket?
- ⭐ Adversarial testing: Do they publish red team or evasion results, or hide behind “proprietary” testing?
- ⭐ BYO stack: Do they sit on top of your Splunk, Sentinel, or CrowdStrike, or do they require migration to their console?
Three or more “no” answers means you are buying marketing. For the longer red-flag list, see our piece on AI SOC red flags.
Head-to-head, the comparison CISOs actually want
| Capability | UnderDefense Agentic AI SOC | Arctic Wolf | CrowdStrike Falcon Complete | ReliaQuest GreyMatter | Legacy MSSP |
|---|---|---|---|---|---|
| Investigation transparency | Full transcript visible | Black box, escalation only | Limited to Falcon console | Mixed, GreyMatter pane | Ticket-only |
| BYO stack support | 250+ integrations, Splunk/Sentinel/CrowdStrike supported | Proprietary, must adopt their stack | Falcon-centric | Open XDR claim, pragmatic | Varies |
| Autonomous containment SLA | Under 2 minutes for high-confidence actions, with 15-minute escalation for critical incidents | Manual escalation, often 30 to 60 min | Strong on endpoint, weak on identity | Playbook driven | Slow, human only |
| Detection-as-Code | Yes, customer-visible rules | Vendor managed, opaque | Vendor managed | Customer can co-author | No |
| Deployment options | Cloud, on-prem, hybrid, and air-gapped | Cloud only | Cloud only | Cloud only | On-prem common |
| Pricing transparency | Published $11 to $15 per endpoint | Opaque, sales-led | Premium, opaque | Mid-to-premium | Custom |
For a buyer-side decision frame across the same vendors, our MDR buyers guide walks through the questions one by one.
Scenario picks, no fence-sitting
- 💰 Mid-market healthcare with Splunk and CrowdStrike already deployed: BYO-stack MDR with HIPAA-aware playbooks. Avoid rip-and-replace. See MDR for Healthcare.
- 💸 PE portco rolling up five companies in 18 months: vendor-agnostic MDR with fast onboarding and unified visibility across mixed stacks.
- ⚠️ Scaling SaaS at 1,000 to 5,000 employees: prioritize autonomous response SLA and identity coverage over endpoint-only providers.
- 🔍 EU enterprise under NIS2 and GDPR: sovereign deployment options (on-prem or air-gapped) and EU data residency are non-negotiable.
Sovereign deployment, the question nobody asks until it is too late
A regulated EU customer once asked me, “can you keep all telemetry inside our jurisdiction?” Most cloud-only MDR vendors said no, or offered a “regional cloud” with vague guarantees. We deploy UnderDefense Agentic AI SOC on-premises, hybrid, or air-gapped on the WarRoom platform. For regulated industries, that single feature is the difference between bidding and getting filtered out at procurement.
“UnderDefense Agentic AI SOC integrates well with our systems, specifically with our SIEM, Splunk. Their team is proactive in identifying and addressing threats.”
— Oleg K., Director of Information Security UnderDefense G2 – Verified Review
“Over the past few years, we’ve undergone several external penetration tests, and during these assessments, Red Canary was not able to identify the malicious activity while the tests were ongoing.”
— Verified Insurance Enterprise User Red Canary – G2 Verified Review
“The product offered little visibility when we were using it. Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager Cybersecurity Services Arctic Wolf – G2 Verified Review
Q9. What is the build-vs-buy economics of an AI SOC in 2026?
Building an AI Security Operations Center (SOC) in-house typically costs $2.5M to $4.5M in Year 1. That covers 24/7 staffing of 8 to 12 full-time employees, SIEM/SOAR/EDR licenses, integration labor, and detection engineering, before any AI tooling. Buying a managed agentic-AI service compresses that to $400K to $900K with a faster Mean Time to Respond (MTTR) floor. The decision pivots on three variables: alert volume, regulatory deployment constraints, and whether you have the drivers for the engines you already own.
What it actually costs to build
A 24/7 SOC needs five shifts of coverage, minimum. (ISC)² 2024 Workforce Study put the global cyber workforce gap at 4.8 million, and the average time to fill a Tier 2 analyst role at 6 to 9 months. Salary alone is the smaller piece. Our SOC cost calculator walks the math line by line.
- 💰 Headcount: 8 to 12 FTEs (Tier 1, Tier 2, Tier 3, and a SOC manager) at a fully loaded $130K to $220K each.
- 💰 Tooling: SIEM licenses, SOAR (Security Orchestration, Automation, and Response), EDR, threat intel, and case management.
- 💰 Integration labor: 6 to 12 months to wire log sources, write playbooks, and tune detections.
- 💰 Detection engineering: a dedicated function most teams discover they need only after Year 1.
What it actually costs to buy
A managed agentic-AI MDR (Managed Detection and Response) service folds those line items into a per-endpoint or per-asset fee. The honest range I see in the market is $11 to $25 per endpoint per month for credible providers. Ingestion economics matter as much as the subscription. Cutting SIEM data volume by 50 to 90 percent through tuning, which is what we do for customers on Splunk and Sentinel, often funds the entire managed service from existing budget. For the line items at retail, see our MDR price guide.
NIST CSF budget mapping, the “Response vacuum”
Run your security spend against the NIST Cybersecurity Framework 2.0 functions: Govern, Identify, Protect, Detect, Respond, and Recover. Most enterprises I audit are 60 to 70 percent invested in Detect and Protect, with single-digit percentages in Respond. That is the Response vacuum. SIEMs alert. Nobody answers at 2 a.m. The 2026 cybersecurity budget playbook shows how to rebalance.
| Cost Component | Build In-House (Year 1) | Buy Managed AI SOC |
|---|---|---|
| Staffing (24/7) | $1.5M to $2.6M | Included |
| SIEM/SOAR/EDR licenses | $400K to $900K | Often BYO, kept |
| Integration labor | $300K to $600K | Included, 30 to 60 days |
| Detection engineering | $250K to $400K | Included |
| Total Year 1 | $2.5M to $4.5M | $400K to $900K |
The Ferrari in the SOC
⚠️ The contrarian take. Most enterprises I meet have already bought the engines. Splunk Enterprise Security, Microsoft Sentinel, CrowdStrike Falcon, and full M365 E5. They just do not have the drivers. One prospect told me they spent four years tuning their EDR and still were not done. That is the 4-Year Tuning Treadmill, the hidden operational debt of build-it-yourself. Our take on cybersecurity technical debt goes deeper.
The decision pivot is simple. If your alert volume is under 50K per month, your team is over five senior analysts deep, and you have no sovereign deployment constraint, build can work. Otherwise, buy and keep your stack with a vendor-agnostic MDR service.
Q10. What does the SOC Automation Maturity Model look like, and where are you on it today?
The SOC Automation Maturity Model spans five levels. Level 0 Manual (analysts triage every alert), Level 1 Scripted (basic SOAR playbooks), Level 2 Augmented (AI enrichment plus human triage), Level 3 Agentic-Assisted (AI investigates, humans decide), and Level 4 Autonomous-Bounded (AI investigates and contains within reversibility limits, humans govern). Most enterprises sit at Level 1.5. The Level 2 to Level 3 jump is where MTTR (Mean Time to Respond) drops by 60 to 80 percent for routine cases.
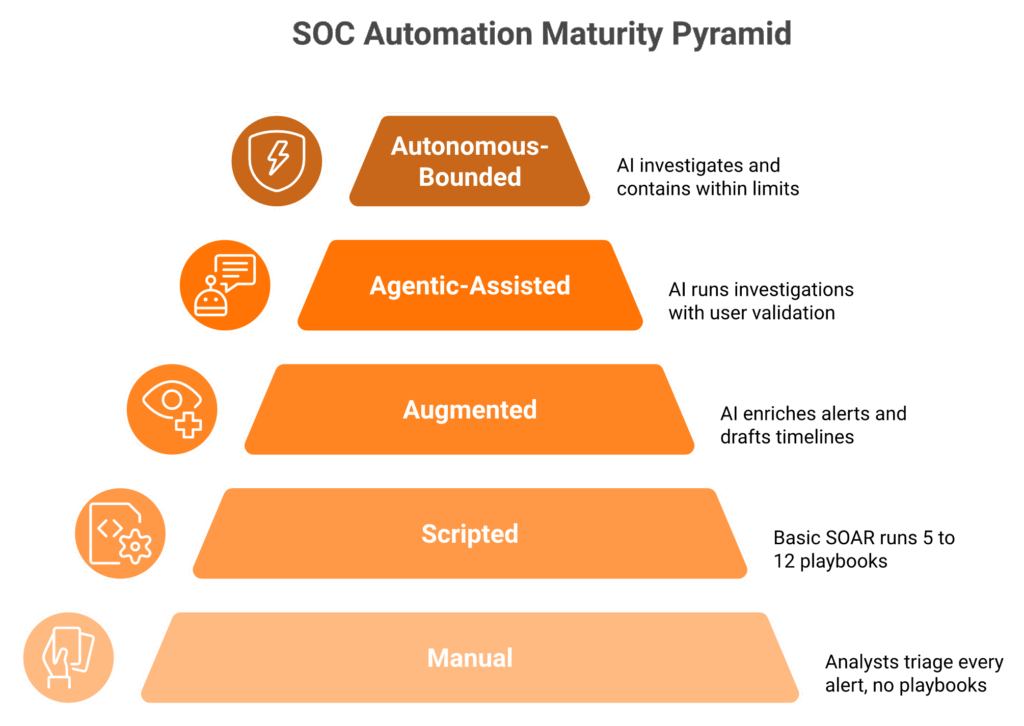
Level 0 and Level 1, the operational debt zone
Level 0 Manual. Analysts open every alert by hand. No playbooks. Every shift starts from zero. Backlog grows on weekends. ❌
Level 1 Scripted. SOAR (Security Orchestration, Automation, and Response) runs maybe 5 to 12 playbooks. Phishing triage, IP blocks, and simple enrichment. Anything novel still bounces to a human at 2 a.m. ❌
How to score yourself in 5 minutes:
- Backlog over 24 hours old? Level 0 or 1.
- MTTR measured in hours, not minutes? Level 0 or 1.
- Tier 1 attrition above 25 percent annually? Level 0 or 1.
Carnegie Mellon’s SEI calls this the “reactive” stage in their SOC Capability Maturity Model. The 4-Year Tuning Treadmill lives here. One prospect told me they spent four years tuning their EDR (Endpoint Detection and Response) and still were not done. That is the cost of staying at Level 1. Our breakdown of outsourced vs in-house SOC compares the two paths out of this zone.
Level 2 to Level 3, the inflection that pays for itself
Level 2 Augmented. AI enriches alerts, pulls related logs, and drafts a timeline. A human triages and decides. Detection and Analysis time drops from 30 minutes to 8 to 12 minutes for routine cases. ✅
Level 3 Agentic-Assisted. AI runs the full investigation. It queries the SIEM (Security Information and Event Management platform), correlates identity across systems, validates with the user through ChatOps (Slack, Teams, or SMS), and produces a structured incident report. A senior analyst confirms or escalates. Routine cases close in under 3 minutes. ✅
In our experience shipping UnderDefense Agentic AI SOC across hundreds of customer environments, what I have noticed is the Level 2 to Level 3 transition is rarely a tooling problem. It is a trust problem. Analysts will not accept AI investigations until they can audit the chain of reasoning. Show the work or the adoption stalls.
Level 4 Autonomous-Bounded, the governance envelope
⭐ Level 4 Autonomous-Bounded. AI investigates and contains within pre-approved reversibility limits. Account lockouts, session kills, malicious IP blocks, and endpoint isolation. Anything reversible in under 5 minutes runs without a human in the loop. Anything else escalates.
The “Bounded” word is doing all the work. NIST CSF 2.0’s Govern function makes this a board-level requirement, not a tooling preference. Document the envelope, test the kill switch quarterly, and log every autonomous action immutably for SEC 8-K Item 1.05 readiness. For the orchestration patterns underneath, see our SOC automation checklist.
Three diagnostic questions for your Monday standup
- ⏰ What is your MTTR by phase: detection, analysis, and containment? If you cannot answer, you are at Level 1 or below.
- 🔍 What percentage of alerts close without a human keystroke? Under 30 percent means Level 1. Between 30 and 60 percent means Level 2. Over 60 percent means Level 3.
- ⚠️ For a credential-misuse alert at 2 a.m., who decides containment? If the answer is “the on-call analyst, woken up,” you are Level 1.5. If the answer is “the playbook, with the analyst auditing in the morning,” you are Level 4.
“The biggest win for me was getting actual control over our security alerts. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified Marketing & Advertising User UnderDefense G2 – Verified Review
Q11. What governance guardrails do you need when AI agents start making security decisions, and how do they tie to SEC, NIS2, and GDPR?
Governance for AI-driven detection requires four guardrails. An immutable audit log of every agentic action (required for SEC 8-K Item 1.05 disclosure within four business days), a reversibility-based kill-switch policy, an AI-agent monitoring layer that watches what Copilot, Cursor, and Claude do in production, and a Shadow AI policy that monitors rather than bans personal-device LLM usage. Banning ChatGPT does not stop usage. It removes visibility, the worst outcome for a CISO accountable under NIS2 and GDPR Article 33.
The four guardrails, mapped to compliance
The contrarian view I keep arriving at: most “AI governance” decks are theater. Real governance ties every agent action to a regulator’s clock. Our compliance services wire these guardrails to the audit clock directly.
- ⭐ Immutable audit log. Every AI action, query, and decision logged with cryptographic integrity. This is what auditors need for SEC Form 8-K Item 1.05, which requires public companies to disclose material cyber incidents within four business days.
- ⭐ Reversibility kill-switch. Documented, testable, and exercised quarterly. NIST AI RMF 1.0 calls this a “managed risk” control.
- ⭐ Agent-monitoring layer. Watches Copilot, Cursor, Claude, and any MCP (Model Context Protocol) server connected to production data. Our dedicated MDR for AI service is built for this.
- ⭐ Shadow AI policy. Visibility first, controls second.
Why banning AI is a security risk
I have watched three Fortune 1000 CISOs ban ChatGPT in the last two years. In every case, employees moved to personal devices and personal phones. Visibility went to zero. EU NIS2 Directive Article 21 holds the management body personally liable for cybersecurity risk management. You cannot manage what you cannot see. ❌
The better play. Sanction a corporate LLM. Monitor egress for paste-to-LLM patterns. Educate. GDPR Article 33 still gives you 72 hours to notify on a personal-data breach, and a Shadow AI leak counts. For more on this trade-off, our piece on AI in cybersecurity is the long read. ✅
The new agent-governance TAM
What I think we will see in the next 18 to 24 months is a new total addressable market that legacy MDRs cannot serve. Production environments now run autonomous agents (Claude code agents, Cursor in CI pipelines, and Copilot acting on calendars and inboxes). These agents have credentials, network access, and decision authority. They are not endpoints, not users, and not servers. Most MDR detection content does not have a single rule for them.
The question I would ask any vendor next quarter: “show me one detection rule that fires on agent misuse.” Most cannot.
Before you commit to any vendor on this list, see how UnderDefense Agentic AI SOC resolves a real incident on your stack.
Q12. What should you do on Monday morning to start reducing MTTR this quarter, and how do you scope an Agentic AI SOC pilot?
Start Monday with a 30-day alert audit to baseline your MTTR by phase. In days 31 to 60, audit your Microsoft 365 E5 entitlements for security features you already own but have not operationalized, and migrate one detection rule set to a Detection-as-Code pipeline. In days 61 to 90, run a Silent Pen Test against your current MDR with full lateral movement, then use the gaps to scope an Agentic AI SOC pilot. Not a rip-and-replace.
Days 1 to 30, baseline what you actually have
⏰ You cannot improve what you do not measure. Start with three numbers.
- Alert volume per week, by source.
- MTTR split into detection, analysis, and containment phases.
- Percentage of alerts that close without human action.
Pull these from your SIEM and ticketing system. Walk the SOC floor. Sit in on a 2 a.m. shift handover. The data lies less than the dashboards do. For the metrics framework, our piece on SOC metrics, including MTTD and MTTR, is the cheat sheet.
Days 31 to 60, harvest what you already own
💸 Most enterprises I audit pay for Microsoft 365 E5 and use under 40 percent of the security features. Defender for Identity, Defender for Cloud Apps, Purview Insider Risk, Conditional Access policies, and the full audit log API are all included. Run an entitlement audit before you write a single new procurement request. Our MDR for Microsoft 365 service is built around exactly this audit.
In the same window, pick one detection rule set (start with credential access, T1003) and migrate it to Detection-as-Code. Sigma format, Git, peer review, and CI tests. This becomes your reusable pattern.
Days 61 to 90, run the Silent Pen Test
🔍 Hire a red team or use an internal one. Run a full lateral movement simulation against your current MDR. Track every alert that fires and every step that goes unnoticed. The CISA Known Exploited Vulnerabilities (KEV) catalog is a free roadmap of techniques actively used in the wild. Use it to scope the test. Our penetration testing team runs this exact validation for customers.
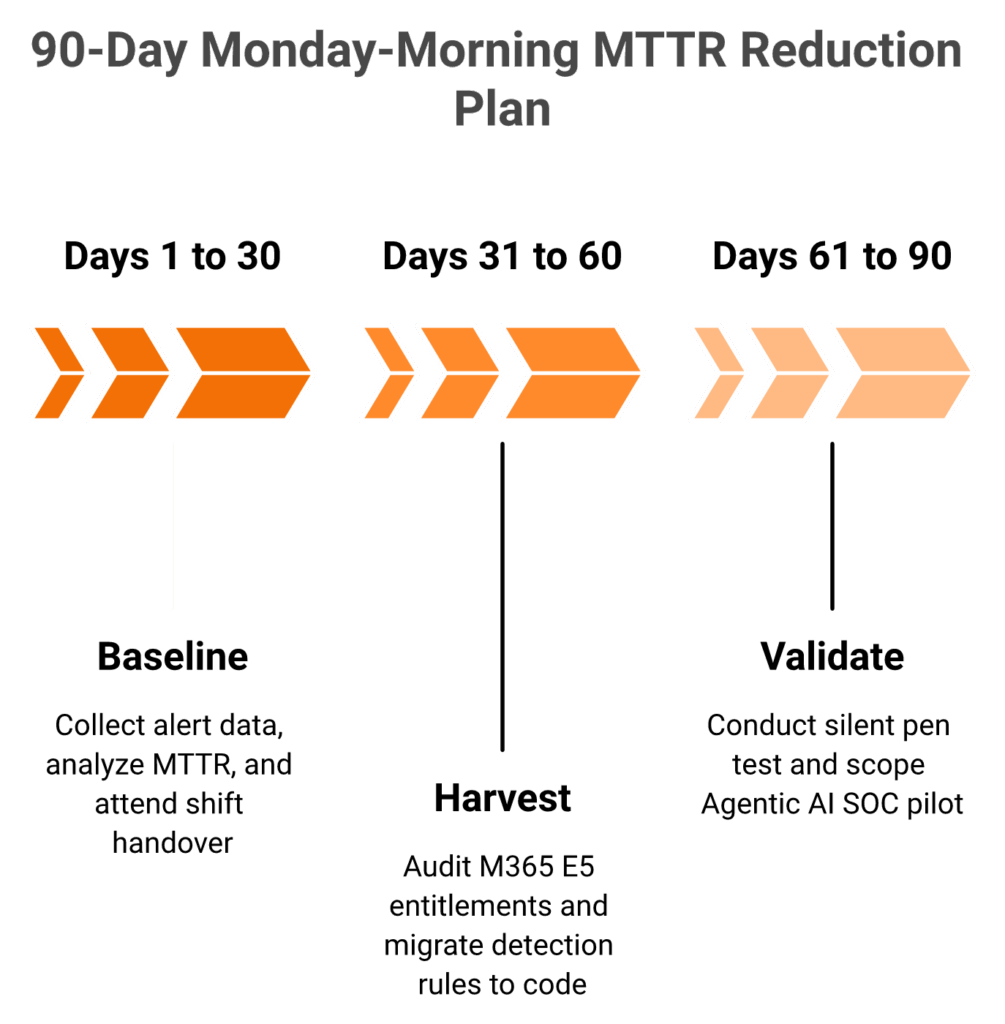
The output is your pilot scope. Not “replace everything.” Just “close these specific gaps.” A scoped Agentic AI SOC pilot of 60 to 90 days, with clear success metrics on the gaps you found, is a defensible board ask.
Run the Silent Pen Test with us
If your dashboard has been quiet for weeks, that is a tuning gap, not safety. Our team will simulate full lateral movement against your current SIEM, EDR, and identity stack, and show you exactly where UnderDefense’s agentic AI closes the gap, with a 2-minute Alert-to-Triage SLA and a 15-minute escalation for critical incidents. No rip-and-replace. BYO Splunk, Sentinel, or CrowdStrike.
Book a 30-minute walkthrough →Transparent pricing. Vendor-agnostic integration. Concierge analyst response.
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified Program Development User UnderDefense G2 – Verified Review
References
Research Papers
Apruzzese, G., et al. “The Cross-Evaluation of Machine Learning-Based Network Intrusion Detection Systems.” USENIX Security Symposium, 2023.
Gardiner, J., and Nagaraja, S. “On the Security of Machine Learning in Cybersecurity: A Systematization of Knowledge.” IEEE Security & Privacy, 2024.
Official Docs / Indian Statutes
Verizon. “2024 Data Breach Investigations Report” Published: May 2024.
MITRE Corporation. “MITRE ATT&CK Framework, v15” Published: 2024.
IBM Security and Ponemon Institute. “Cost of a Data Breach Report 2024” Published: July 2024.
Mandiant. “M-Trends 2024 Special Report” Published: April 2024.
U.S. Securities and Exchange Commission. “Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure (Item 1.05, Form 8-K)” Published: December 2023.
SANS Institute. “2024 SANS SOC Survey” Published: 2024.
Gartner. “Magic Quadrant for Security Information and Event Management” Published: May 2024.
Forrester Research. “The Forrester Wave: Managed Detection and Response, Q2 2024” Published: 2024.
MITRE Corporation. “MITRE D3FEND Knowledge Graph” Published: 2024.
SigmaHQ. “Sigma: Generic Signature Format for SIEM Systems (open-source rule repository)” Published: 2024.
SANS Institute. “F3EAD: Find, Fix, Finish, Exploit, Analyze, Disseminate (adapted for cyber threat intelligence)” Published: 2024.
NIST. “SP 800-61 Rev. 3: Incident Response Recommendations and Considerations for Cybersecurity Risk Management” Published: April 2025.
Gartner. “Market Guide for Managed Detection and Response Services” Published: 2024.
(ISC)². “2024 Cybersecurity Workforce Study” Published: October 2024.
NIST. “Cybersecurity Framework (CSF) 2.0” Published: February 2024.
Carnegie Mellon University Software Engineering Institute. “SOC Capability Maturity Model” Published: 2024.
NIST. “AI Risk Management Framework (AI RMF 1.0)” Published: January 2023.
European Union. “Directive (EU) 2022/2555 on measures for a high common level of cybersecurity (NIS2)” Published: December 2022.
European Union. “General Data Protection Regulation (GDPR), Article 33” Effective: May 2018.
Microsoft. “Microsoft 365 E5 Security Documentation” Published: 2024.
CISA. “Known Exploited Vulnerabilities (KEV) Catalog” Published: Updated continuously.
Blogs
G2. “Verified user reviews of UnderDefense MAXI on G2.” [Secondary source]
G2 and Gartner Peer Insights. “Verified user reviews of Arctic Wolf, Red Canary, Rapid7, Alert Logic, and Expel.” [Secondary source]
1. What does automated threat detection actually mean in 2026?
We define automated threat detection in 2026 as agentic AI workflows that autonomously collect evidence across SIEM, EDR, identity, and cloud, correlate signals in seconds, and execute pre-approved containment actions like credential wipes and session kills in under two minutes. Tier 3 to Tier 4 humans remain the final decision-makers, because AI is correct in roughly 30 percent of investigations on its own. The shift from 2022 is real. Rule-based alerting bolted onto a SIEM lost the speed race the moment threat actors weaponized AI for reconnaissance. We have seen median time-to-exploit on published vulnerabilities drop to under five days. At UnderDefense, we built Agentic AI SOC on this agentic foundation, with a 2-minute Alert-to-Triage SLA and a 15-minute escalation for critical incidents. For a deeper read on the operating model, our guide to MDR services walks through how this changes buyer decisions.
2. How do AI-driven SOCs actually reduce MTTR by 80 percent?
We see the 80 percent reduction land only when all four MTTR phases are automated together: detection latency, triage, investigation, and containment. Automating detection alone moves the needle by 15 to 25 percent.
-
Streaming analytics cut detection latency by 30 to 50 percent.
-
Auto-enrichment and ChatOps cut triage by 85 to 95 percent.
-
Agentic correlation cuts investigation by 70 to 90 percent.
-
Pre-approved playbooks cut containment by 60 to 80 percent.
In our experience onboarding mid-market enterprises, Year 1 typically lands at 40 to 55 percent reduction. The 80 percent number shows up in Year 2 or Year 3, after Detection-as-Code is in place, after ingestion is tuned, and after response playbooks are battle-tested. Anyone promising 80 percent in 90 days is selling a deck. For the metric definitions and SLA frameworks behind these numbers, see our breakdown of SOC metrics, including MTTD and MTTR.
3. How do we tell real Agentic AI from "AI-washed" MDR?
We use a five-test rubric. Real Agentic AI shows the agent’s investigation reasoning, version-controls detection rules, executes autonomous containment under SLA, publishes adversarial-evasion test results, and operates on top of the customer’s existing SIEM and EDR rather than forcing rip-and-replace. AI-washed MDRs fail at least three of those tests. Ask any vendor to walk through one real customer investigation transcript end to end. Black-box providers will refuse. Ask whether their detection rules live in Git with peer review. Most cannot answer. We built MAXI to pass all five tests, with full reasoning transparency and 250-plus integrations on the WarRoom platform. For the longer red-flag list, our piece on AI SOC red flags is the practitioner cheat sheet.
4. What is the build-vs-buy economics of an AI SOC in 2026?
Building in-house typically costs $2.5M to $4.5M in Year 1. That covers 24/7 staffing of 8 to 12 FTEs, SIEM/SOAR/EDR licenses, integration labor, and detection engineering, before any AI tooling. Buying a managed agentic-AI service compresses that to $400K to $900K with a faster MTTR floor. The decision pivots on three variables: alert volume, regulatory deployment constraints, and whether you have the drivers for the engines you already own. Most enterprises we audit have already bought Splunk, Sentinel, and Falcon but lack the dedicated detection engineers to operate them. Cutting SIEM data volume by 50 to 90 percent through ingestion tuning often funds the entire managed service from existing budget. Run the line items through our SOC cost calculator before scoping a pilot.
5. How does autonomous response align with NIST SP 800-61?
We map autonomous response cleanly to the NIST SP 800-61 incident response lifecycle. AI handles Detection and Analysis (alert triage, log enrichment, IOC lookup) and most of Containment (endpoint isolation, session kill, IP block, account disable). Humans own Eradication, Recovery, and Post-Incident Activity. The governance line is reversibility. If an action is reversible in under five minutes, automate it. Account lockouts, session kills, and endpoint isolation qualify. Domain controller reboots, mass password rotations, and perimeter firewall changes do not. This single test prevents the worst autonomous-response failure mode, which is an AI that takes a confident but wrong action against business-critical infrastructure at 3 a.m. on a Saturday. Our incident response team owns this concierge model end to end, and our IR plan template codifies the same split.
6. What does the SOC Automation Maturity Model look like, and where do most enterprises sit?
We use a five-level model.
-
Level 0 Manual: analysts triage every alert.
-
Level 1 Scripted: basic SOAR playbooks.
-
Level 2 Augmented: AI enrichment plus human triage.
-
Level 3 Agentic-Assisted: AI investigates, humans decide.
-
Level 4 Autonomous-Bounded: AI investigates and contains within reversibility limits, humans govern.
Most enterprises sit at Level 1.5. The Level 2 to Level 3 jump delivers the headline 60 to 80 percent MTTR drop for routine cases. Three diagnostic questions reveal your level. Can you answer MTTR by phase? What percentage of alerts close without a human keystroke? At 2 a.m., who decides containment on a credential-misuse alert? If you are stuck at Level 1, the path forward is detection engineering, not more tools. Our SOC automation CISO checklist covers the next steps.
7. What governance guardrails do we need when AI agents make security decisions?
We enforce four guardrails:
-
An immutable audit log of every agentic action, mapped to SEC 8-K Item 1.05’s four-business-day disclosure clock.
-
A reversibility-based kill-switch policy, tested quarterly.
-
An AI-agent monitoring layer that watches Copilot, Cursor, Claude, and any MCP server connected to production data.
-
A Shadow AI policy that monitors rather than bans personal-device LLM usage.
Banning ChatGPT does not stop usage. It removes visibility, the worst outcome for a CISO accountable under EU NIS2 Article 21 and GDPR Article 33. Visibility first, controls second. Production environments now run autonomous agents with credentials, network access, and decision authority. Most MDR detection content has zero rules for them. Our dedicated MDR for AI service is built for exactly this gap.
8. What should we do on Monday morning to start reducing MTTR this quarter?
Run a 90-day plan in three windows.
-
Days 1 to 30: baseline alert volume per source, MTTR split by phase, and percentage of alerts that close without human action. Sit in on a 2 a.m. shift handover. The data lies less than the dashboards do.
-
Days 31 to 60: audit your Microsoft 365 E5 entitlements. Most enterprises pay for E5 and use under 40 percent of the security features. Defender for Identity, Defender for Cloud Apps, Purview Insider Risk, and Conditional Access policies are already in your contract. In the same window, migrate one detection rule set to a Detection-as-Code pipeline.
-
Days 61 to 90: run a Silent Pen Test against your current MDR with full lateral movement, then scope a 60-to-90-day Agentic AI SOC pilot against the gaps.
Our MDR for Microsoft 365 service is built around this exact entitlement audit.