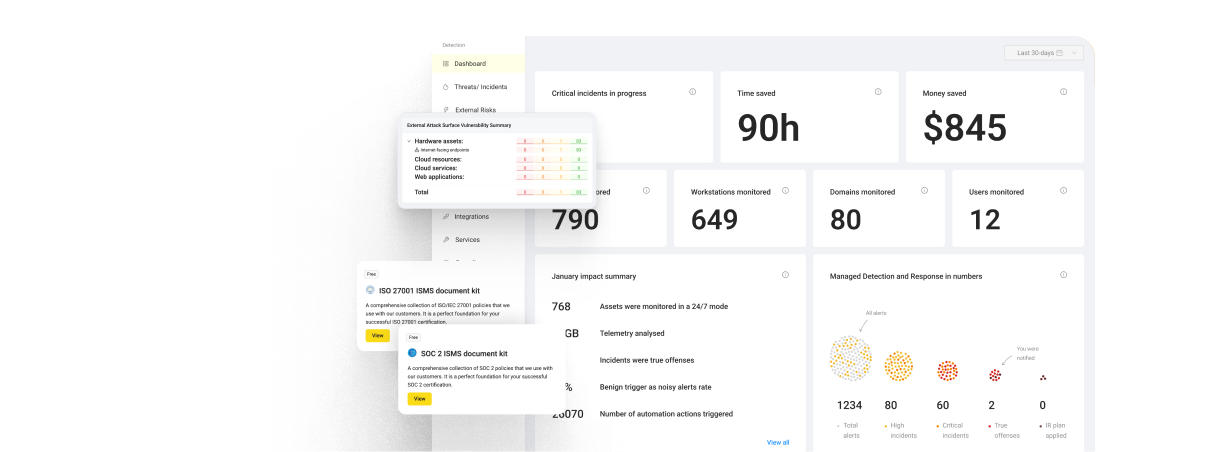
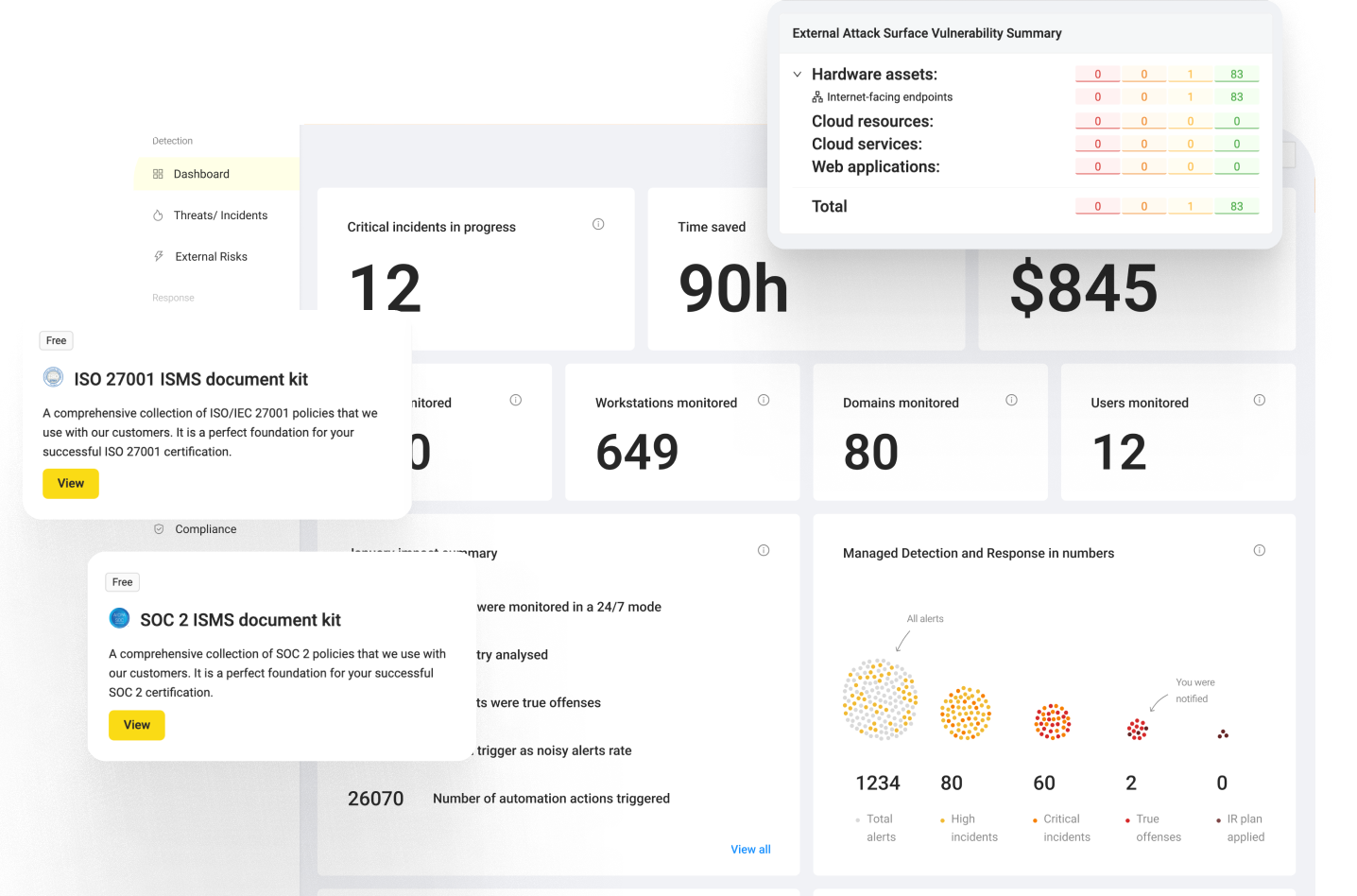
A CISO at a 4,000-person fintech in New York pinged me on a Slack bridge at 2:14 a.m. last quarter. Her EDR was silent. Her SIEM dashboard was green. And yet, a contractor account had just spawned a singleton PowerShell binary, queried Active Directory for Domain Admins, and exfiltrated 2.3 GB to an unfamiliar ASN. By the time the on-call analyst opened the ticket, the agentic attacker chain had already moved laterally to four hosts. That single night told me everything about why signature-based detection is finished. The race is no longer about who has the biggest rule library, but about whose hunters can think, query, and contain at machine speed before the attacker’s AI does it first.
Q1. What is AI threat hunting in 2026, and why has it replaced signature-based detection?
AI threat hunting is the proactive, hypothesis-driven pursuit of adversaries who have already evaded prevention, executed at machine speed by combining LLM-generated hypotheses, behavioral analytics, and MITRE ATT&CK telemetry. Unlike signature detection, it assumes compromise, mines the long tail of singleton events, and contextualizes weak signals across SIEM, EDR, identity, and SaaS logs. In 2026 it is no longer optional. Agentic attackers compress dwell time from a 10-day median to under 60 minutes.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
Hunting versus detection versus incident response
Detection waits for a known-bad pattern to fire. Incident response (IR) reacts after that fire. Hunting sits between them, asking, “What if we already missed something?” The 2025 Verizon DBIR reported a global breach-discovery median that still stretches into double digits, with most intrusions surfaced by external parties, not by internal detection. That number is the scoreboard. Every minute of dwell time is a minute the attacker uses to chain credential theft into lateral movement.
Signature detection works for yesterday’s malware. It breaks for novel TTPs (tactics, techniques, and procedures), supply-chain implants, and identity-based abuse, where the adversary uses your own tools against you. AI threat hunting replaces “match this hash” with “find the service account that authenticated from a new ASN, spawned cmd.exe within 90 seconds, and queried lsass.exe.”
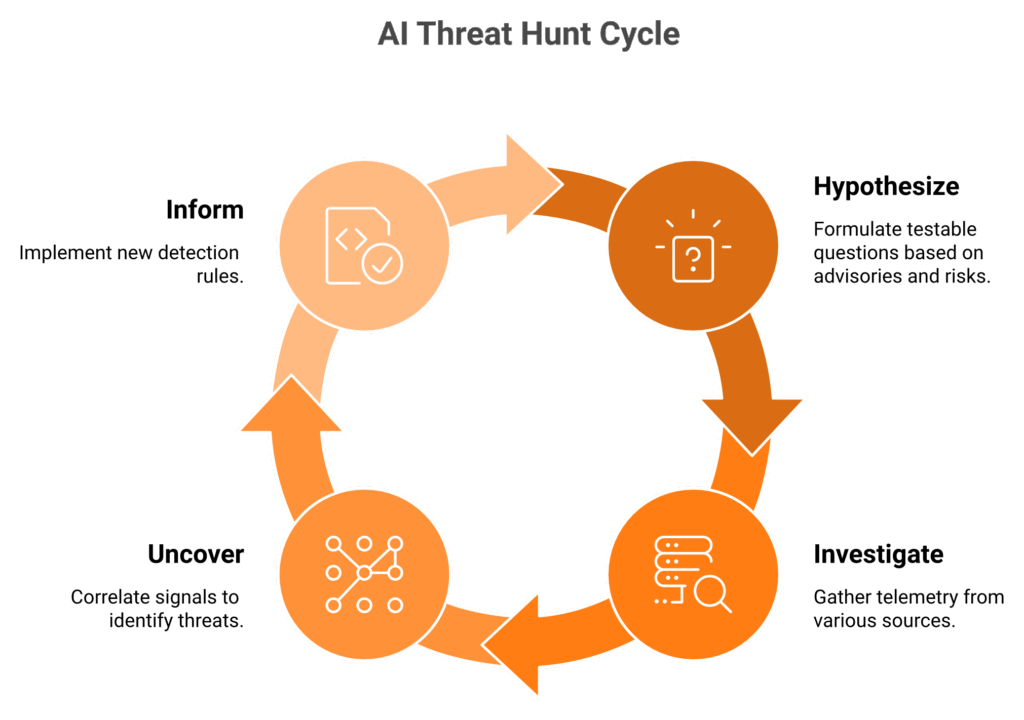
The hunt loop, in plain English
Every modern hunt follows the same four-step loop: Hypothesize, Investigate, Uncover, and Inform. The hypothesis is a testable question grounded in CISA advisories, MITRE ATT&CK technique additions, or your own crown-jewel risk model. The investigation pulls telemetry. The uncovering correlates weak signals into a verdict. The informing writes a new detection rule back into your stack so the same attacker cannot return tomorrow.
A real example: the 2:14 a.m. singleton
Back to that fintech. Long Tail Analysis (LTA) on 30 days of process executions surfaced exactly one host that had ever run that PowerShell binary. The AI agent enriched it in 90 seconds: parent process, identity, ASN, ATT&CK mapping to T1059.001 (Command and Scripting Interpreter: PowerShell). A human Tier-3 analyst confirmed and contained. AI is whatever machines have not done yet, which is why most teams underestimate the SIEM they already own and overpay for new “AI” modules that simply re-skin existing search.
Q2. How has agentic AI on the attacker side collapsed the threat-hunting timeline from days to minutes?
Agentic attackers chain reconnaissance, credential theft, and lateral movement autonomously. They compress the kill chain from days to minutes. Human-speed SOCs running 30-minute triage SLAs cannot keep pace. The defensive answer is not more headcount, but agentic AI that automates mechanical investigation steps so Tier-3 humans spend their hours on judgment, not log surfing. That is exactly how the XZ Utils backdoor was caught, by a human noticing a millisecond SSH delay.
The speed math no SOC can dodge
Mandiant’s 2025 M-Trends reported that internal detection median dwell sits around 10 days globally and stretches further when relying on outside notification. Compare that against an agentic attack chain that reasons, retries, and escalates without a coffee break. Time is the currency of the cloud. Seconds, not hours, decide whether your customer data leaves the perimeter.
A 2023 ACM Computing Surveys analysis of NLP-based intrusion detection found that transformer models outperform legacy rule signatures on novel TTPs by 18 to 22 percent F1 score, but degrade sharply under adversarial prompt injection. Translation for a SOC manager: LLMs catch what your Snort rules miss, until attackers learn to talk to your LLM.
⚠️ Sidebar: the XZ Utils catch and the Zimbra ghost
XZ Utils, the now-famous 2024 supply-chain backdoor, was uncovered by a Postgres engineer who felt a 500-millisecond SSH login lag and refused to ignore it. No SIEM rule fired. No EDR alert. The same is true of the Zimbra Memcache exploit. It never touched the endpoint, evaded EDR completely, and was only catchable through deep behavioral log analysis. Defenders operating at human speed have already lost the race against AI, but humans paired with agentic AI still win the novel ones. Black-box AI alone catches commodity. Humans plus observable AI catch the bespoke.
What this means on Monday morning
Walk into your SOC and instrument three numbers: median time-to-investigate, percentage of dismissed alerts per analyst, and how many of last month’s incidents were surfaced internally versus externally. If “external” leads, you are still on the wrong side of the timeline. Pair every hunter with an AI that does the SIEM querying, identity graph traversal, and ATT&CK mapping. Keep humans on verdict authority. That is the only configuration that moves the dwell-time needle in 2026, and it is the operating model behind our MDR service.
Q3. What does an AI threat investigation platform actually automate, and what should it never automate?
An AI threat investigation platform automates SIEM querying, multi-source correlation, identity graph traversal, ATT&CK mapping, and structured report generation, typically delivering investigative context in under 60 seconds. It should never own final verdict authority on novel attacks. Internal benchmarks across our customer base show AI reaches a correct conclusion in roughly 30 percent of security cases, so Tier-3 and Tier-4 analysts must remain the jury, not the stenographer.
The 30 percent reality
A 2024 Computers & Security study by Tilbury and Flowerday found hybrid human-AI SOCs cut triage time by 40 to 60 percent only when analysts retained veto authority. Full automation backfired, producing higher false-negative rates on novel threats. Plain language for a CISO: the platforms that automate the verdict will eventually miss the breach that ends your career. Supervised autonomy, with a human in the loop on mid-confidence cases, wins.
This is why we treat AI as a context collector, not a jury. The grunt work, querying Splunk or Sentinel, pulling EDR timelines, joining identity logs, and mapping to ATT&CK, gets done in seconds. The judgment, deciding whether a singleton PowerShell event is a red-team test or a real intruder, stays with humans. This division of labor is the basis for our work on SOC automation.
What to automate, what to augment, what to keep human-only
| Hunt-loop step | Automate fully ✅ | Augment with AI 🤝 | Human-only ❌ |
|---|---|---|---|
| SIEM query generation | ✅ | ||
| Multi-source correlation (EDR + identity + SaaS) | ✅ | ||
| ATT&CK technique mapping | ✅ | ||
| Identity graph traversal | ✅ | ||
| Hypothesis generation from advisories | 🤝 | ||
| Triage of mid-confidence alerts | 🤝 | ||
| Structured report drafting | ✅ | ||
| Final verdict on novel TTPs | ❌ | ||
| Customer notification of breach | ❌ | ||
| Detection rule promotion to production | 🤝 |
IBM’s 2023 patent application US20230412620A1 describes exactly this division of labor: an AI agent traverses a knowledge graph across SIEM and EDR data, surfaces context, and hands a structured packet to a human investigator. That blueprint matches what we ship in the UnderDefense Agentic AI SOC platform today, and it is the only design that survives audit.
What customers actually feel
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
“Underdefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense G2 – Verified Review
The Monday move
Walk your hunt loop and label every step Automate, Augment, or Human-Only. If your current vendor automates the verdict and hides the reasoning, you have a black box, not a hunter. Less theater, more throughput. Less black box, more blue team. If you want a deeper read on this tradeoff, our take on whether AI kills or saves your SOC walks through the same logic with data.
Q4. How do you operationalize MITRE ATT&CK + ATLAS automation without drowning in low-value detections?
Treat detection logic as code. Write rules in Python or Sigma, version-control them in Git, and deploy via CI/CD with adversarial test cases. Prioritize ATT&CK techniques weighted by CISA KEV exploitation evidence and your crown-jewel exposure, not matrix-completeness theater. Layer MITRE ATLAS on top to cover prompt injection (AML.T0051) and model evasion against your own AI hunter, because the same LLM that hunts attackers can be hunted.
The Adversary Intelligence Trifecta
I keep three frameworks taped above my desk. The Lockheed Martin Cyber Kill Chain provides strategy. MITRE ATT&CK provides operational vocabulary. The Diamond Model provides analyst methodology for tracking activity threads across campaigns. Together they form the trifecta. Skip any one and your hunt program drifts toward checkbox theater.
A six-step playbook for ATT&CK + ATLAS automation
Step 1: Inventory current ATT&CK coverage honestly
Pull every active detection rule and map it to an ATT&CK technique ID. Most teams discover they have 60+ rules covering Initial Access (TA0001) and three covering Lateral Movement (TA0008). That gap is where attackers live.
Step 2: Score techniques against CISA KEV and your crown jewels
The CISA Known Exploited Vulnerabilities Catalog is the single best prioritization signal in 2026. Cross-reference KEV entries with the ATT&CK techniques they enable, then weight by the systems that hold your customer data, payroll, or production secrets. Stop hunting techniques that do not touch your crown jewels.
Step 3: Convert rules to code
Move from clicking inside a SIEM UI to writing rules in Sigma or Python, stored in Git, and reviewed by pull request. Sworna and Babar’s 2023 ACM survey showed transformer-augmented detection-as-code pipelines outperformed UI-managed rules on novel TTP recall. Code is auditable. Clicks are not. If you are still selecting your data layer, our guide on how to choose a SIEM covers the eight criteria that matter.
Step 4: Build CI/CD with adversarial prompt-injection tests
Every rule that involves an LLM, every hypothesis-generator, and every alert-summarizer, gets a red-team test suite. Inject prompts that try to disable the rule, exfiltrate the system prompt, or force a false negative. CrowdStrike’s 2024 patent application WO2024118143A1 on agentic threat-hunting orchestration explicitly calls out adversarial CI as a deployment gate. If your AI vendor cannot show you their adversarial test suite, that is the answer. Our internal red-team playbooks are also informed by the same principles we apply during penetration testing engagements.
Step 5: Add ATLAS overlay for agentic IDE monitoring
MITRE ATLAS catalogs adversarial-ML techniques, including AML.T0051 prompt injection. In 2026, the new attack surface is your developers’ Claude, Cursor, and Copilot sessions executing tool calls inside production. Banning these tools just creates Shadow AI on personal laptops. Monitor the agent behavior inside corporate boundaries instead. Our MDR for AI coverage is built specifically for this surface.
Step 6: Enable Night-Shift Pattern Detection
Adversaries who study your business hours run their noisy actions between 1 a.m. and 3 a.m. local time, when first-line admins are asleep. A simple time-bucketed anomaly rule across privileged identity actions is one of the highest-yield rules I have ever shipped.
The governance backbone
We treat detection logic as code at UnderDefense for one reason: governance. Auditors will not accept “the AI decided.” They will accept “here is the rule, here is the test that validates it, here is the Git commit, and here is the analyst who reviewed it.” That trail is what turns AI threat hunting from a demo into an audit-ready program, and it is the same trail we hand to clients during compliance services engagements.
What this means on Monday
Open your detection rule repository. If you do not have one, create it before lunch. Map your top 20 rules to ATT&CK technique IDs. Cross-reference with the CISA KEV catalog. Identify the three Lateral Movement techniques you do not currently cover. Write the first rule in Sigma. Commit it. That is the start of detection-as-code, and it is how you stop drowning in low-value detections. If you would like a side-by-side comparison of the platforms that support this workflow, our MDR vendors list 2025 is a good next read.
Q5. How do LLMs generate hunting hypotheses, and how do you stop them from hallucinating threats?
LLMs generate hunt hypotheses by ingesting recent ATT&CK additions, CISA advisories, and your own telemetry baselines, then proposing testable queries. A typical output reads, “Find any service account that authenticated from a new ASN and spawned cmd.exe within 90 seconds.” Hallucination is controlled by retrieval-augmented grounding (RAG), citation-required outputs, prompt-injection test suites, and a measurable bias profile that analysts can tune rather than a black box.
How RAG-grounded hypothesis generation actually works
The naive way to use an LLM in a SOC is to ask it, “What threats should we hunt today?” and trust the output. That path is how false positives and made-up CVE numbers end up in incident tickets. The grounded way is different. We feed the model three streams: recent CISA advisories, this week’s MITRE ATT&CK technique updates, and the customer’s own 30-day telemetry baseline. The model is then forced to cite the exact log row, advisory paragraph, or rule ID it used to reach each hypothesis.
A 2023 ACM Computing Surveys analysis by Sworna and Babar tested transformer-based detectors on novel TTPs (tactics, techniques, and procedures), and found 18 to 22 percent better F1 score over signature rules, but only when grounding data was present. Without grounding, accuracy collapsed. Our broader perspective on this is in our piece on AI in cybersecurity.
✅ The four guardrails we ship in production
- Retrieval-augmented grounding. Every hypothesis cites a specific log row, advisory, or rule.
- Citation-required outputs. No source, no hypothesis. The model returns “I do not know” instead of inventing.
- Prompt-injection test suites. Every release runs a red-team prompt set in CI, blocking deploys that fail.
- Measurable bias profile. Analysts can see and tune the model’s preference between “more recall” and “more precision.”
A 2023 arXiv paper by Ban and colleagues showed graph-based alert correlation reduced ticket volume by over 70 percent compared with flat SIEM correlation. That is the engine behind a grounded hypothesis. Stop scoring single alerts. Score graphs.
⚠️ What we got wrong the first time
I will tell on us. Our first version of the UnderDefense Agentic AI SOC platform hypothesis generator was ungrounded. We saw roughly 30 percent accuracy in real customer environments, which is exactly what internal benchmarks across the security industry consistently show for naive LLM-only verdicts. That number embarrassed the team. We rebuilt with retrieval grounding, citation-required prompts, and an analyst-tunable bias dial. Accuracy on validated hypotheses jumped, and analysts finally trusted the output.
Bias is a feature, not a bug. A measurable, biased model that an analyst can tune beats an “unbiased” black box that nobody can audit. If your AI vendor cannot show you the bias dials, you are renting opinions, not running detection. Our running list of AI SOC red flags covers the other warning signs.
The $300k accidental discovery
One of our mid-market customers ran our grounded hunter for 90 days. The hypothesis engine flagged an anomalous after-hours payroll login pattern. It did not look like malware. Most malware-only hunting rules would have skipped it. A Tier-3 analyst pulled the thread and uncovered an internal payroll fraud scheme that had been running for months. The recovered funds paid for the entire MDR service contract several times over. That is what a grounded hunter buys you. Not just speed. Accidental discoveries that change the ROI conversation with your CFO.
Q6. What does a self-healing SOC architecture look like, and how does it satisfy SOC 2, NIS2, and SEC Item 1.05?
A self-healing SOC ingests vendor-agnostic telemetry into a tuned data layer (Splunk, Sentinel, or Chronicle), runs LLM-driven hypotheses against ATT&CK and ATLAS, executes graph-based correlation, and triggers autonomous containment such as credential wipes, password resets, and forced logouts within a 2-minute Alert-to-Triage window with a 15-minute escalation for critical incidents. Closed-loop feedback writes lessons back into detection-as-code. The same investigative trail doubles as auditable evidence for SOC 2 Type II, NIS2 24-hour reporting, and SEC Item 1.05 / 8-K disclosure.
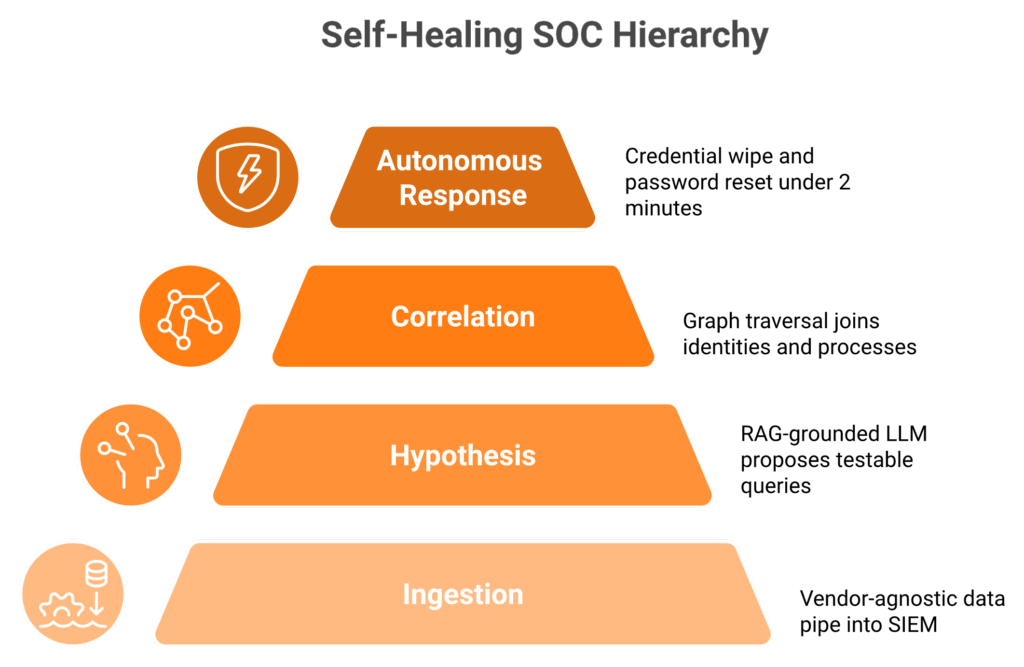
⏰ The four architectural layers
Layer 1: Ingestion (data ownership stays with you)
Pipe logs from EDR, identity, SaaS, and cloud into your existing SIEM. Do not let the MDR force a proprietary swap. We tune ingestion at this layer, dropping known-noisy events to cut SIEM volume by 50 to 90 percent without losing visibility. If you are still selecting your data layer, our SIEM buyers guide covers what to look for.
Layer 2: Hypothesis (grounded LLM proposals)
The same RAG-grounded hypothesis engine from Q5 runs continuously, scoring proposals against ATT&CK techniques and ATLAS adversarial-ML methods.
Layer 3: Correlation (graphs, not lists)
Alerts become nodes. Identities, hosts, and processes become edges. Graph traversal surfaces attack chains that flat lists hide. Ban and colleagues’ 2023 graph-correlation study reported greater than 70 percent ticket reduction using exactly this approach.
Layer 4: Autonomous response (within two minutes)
For high-confidence chains, the UnderDefense Agentic AI SOC platform executes credential wipes, password resets, forced logouts, and host isolation autonomously. Microsoft’s 2022 patent US11418524B2 describes the behavioral baselining that makes safe autonomous credential action possible. IBM’s 2024 Cost of a Data Breach Report pegged AI plus automation at $2.22 million in average breach cost savings. ⏰ ⚡
Closed-loop feedback and compliance evidence
Every action writes back into detection-as-code, so the next attempt is blocked at Layer 1. The audit trail is the compliance artifact. Your auditor stops asking, “How do you know your SOC works?” because every step, hypothesis, query, verdict, and action, has a Git commit and a timestamp. This is the same trail we hand to clients during compliance services engagements.
| Framework | Citation | Audit artifact each layer emits |
|---|---|---|
| SOC 2 Type II | TSP CC7.2, CC7.3 | Continuous monitoring evidence and analyst attestation |
| ISO/IEC 27001:2022 | A.8.16, A.5.25 | Detection rule version history and incident logs |
| EU NIS2 Directive | Art. 23 (24-hour reporting) | Timestamped containment and customer notice trail |
| SEC Item 1.05 / 8-K | 17 CFR §229.106 | Materiality determination memo and 4-day disclosure log |
| HIPAA / PCI DSS | 45 CFR §164.308 / Req. 10 | Immutable log retention and forensic chain of custody |
The customer voice
“Their adherence to SLAs gives me confidence in our infrastructure’s protection. As the Information Security Director, it lets me focus on strategy, knowing the day-to-day security is managed effectively.”
— Oleg K., Director Information Security UnderDefense G2 – Verified Review
“They’ve also made our audit process much less painful. The reports from their platform give us clear evidence of our security controls and incident response capabilities.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
We built UnderDefense Agentic AI SOC as a layer above your existing SIEM for one reason. Your business logic and institutional memory live in those Splunk and Sentinel queries. Ripping them out to fit a vendor’s proprietary platform burns three years of tuning, and breaks every audit trail that pointed there. Less theater, more throughput. Less black box, more blue team.
Q7. Which adversarial ML risks target the hunter’s own AI, and how do you defend against prompt injection and model poisoning?
The same AI that hunts attackers can be hunted. MITRE ATLAS catalogs prompt injection (AML.T0051), model evasion, training-data poisoning, and inference-time exfiltration as real, indexed adversarial techniques. Defenses include input sanitization, system-prompt isolation, output validation against ground-truth telemetry, red-team CI tests for adversarial prompts, and monitoring agentic IDEs (Claude, Cursor, Copilot) for unauthorized tool calls inside corporate boundaries.
⚠️ The new question your AI vendor cannot dodge
Situation. Your AI hunter now sits inside the kill chain. It reads logs, queries identity systems, and executes containment. Complication. ATLAS techniques have become real, with documented prompt-injection cases targeting LLM-driven security tools in the last 18 months. Question. Who hunts your hunter? Answer. A layered defense, applied to the AI in the same way you defend any production service. Our MDR for AI coverage is built specifically for this surface.
A 2023 ACM Computing Surveys review by Sworna and Babar found transformer-based detectors degrade sharply under adversarial prompt injection, even when they outperform signatures on novel TTPs. The same model that wins on Monday loses on Friday if its prompt boundary is permeable.
✅ The five-point defense list
- Input sanitization. Strip embedded instructions from log fields, ticket descriptions, and email subjects before they reach the model.
- System-prompt isolation. The system prompt is read-only at runtime. User inputs never modify it. Out-of-band tests confirm.
- Output validation against ground-truth telemetry. If the model claims a host is compromised, an independent query must confirm the IOC (indicator of compromise) before any containment action fires.
- Red-team CI tests for adversarial prompts. Every release runs a curated injection suite. A failure blocks deployment.
- Agentic IDE monitoring. Claude, Cursor, and Copilot inside developer workstations now execute tool calls against production. Monitor those calls in the SIEM the same way you monitor RDP sessions.
If you want to pressure-test these defenses against a real adversary, our penetration testing team will run the prompt-injection suite against your stack.
Banning AI tools just creates Shadow AI
I keep hearing CISOs ask whether to block ChatGPT at the proxy. My honest answer: blocking is a visibility tax, not a control. Users move to personal devices, and you lose every signal. The better play is to allow corporate AI use under monitored boundaries, log every prompt and tool call, and apply the same DLP (data loss prevention) controls you already use for email. Our take on the broader trend is in conversational SOCs.
A quiet dashboard is not safety. It usually means your detection logic cannot see the new attack surface yet. Pen tests against agentic environments routinely produce zero alerts on first run. That silence should terrify you, not comfort you. Ship the ATLAS overlay before your next red-team engagement, and watch the dashboard wake up.
Q8. AI threat investigation platform comparison: which vendor wins for vendor-agnostic, autonomous-response SOC operations?
Legacy MDRs (Arctic Wolf, ReliaQuest) often force a proprietary SIEM and forward alerts for the customer to fix. A vendor-agnostic AI SOC like the UnderDefense Agentic AI SOC platform sits on top of Splunk, Sentinel, or Chronicle, executes autonomous containment in under two minutes, and exposes every AI investigative step for audit. Score every platform on agentic autonomy, containment authority, ingestion model, ATLAS coverage, transparency, ingestion-tuning economics, human-in-the-loop veto, and second-grade SLAs.
The 2026 platform shortlist
- UnderDefense Agentic AI SOC. Vendor-agnostic AI SOC layered on top of your existing SIEM, autonomous containment under two minutes, full investigative-step transparency, and transparent endpoint pricing.
- CrowdStrike Charlotte AI / Falcon Complete. Strong endpoint telemetry and agentic patent depth (WO2024118143A1), but tightly coupled to the Falcon stack.
- ReliaQuest GreyMatter. Solid open-XDR posture, but heavier customer lift on tuning and remediation.
- Arctic Wolf Aurora. Concierge-style delivery, criticized in peer reviews for proprietary platform lock-in and remediation gaps.
- Stellar Cyber Open XDR. Open data layer, good for SIEM consolidation, lighter on autonomous response.
For a deeper rundown of the field, see our MDR vendors list 2025.
✅ The eight-criterion rubric
| Criterion | Weight | What “good” looks like |
|---|---|---|
| Agentic autonomy depth | 15% | Multi-step investigation without human prompt |
| Autonomous containment authority | 15% | Credential wipe, password reset, host isolation under 2 min |
| Vendor-agnostic ingestion | 15% | Works on top of Splunk, Sentinel, and Chronicle without rip-and-replace |
| MITRE ATLAS coverage | 10% | Documented prompt-injection and model-evasion detection |
| Transparency of AI reasoning | 15% | Every step observable, exportable, and audit-ready |
| Ingestion-tuning economics | 10% | 50 to 90 percent SIEM volume reduction without coverage loss |
| Human-in-the-loop veto | 10% | Mid-confidence cases route to analyst, never auto-close |
| Second-grade SLA | 10% | Detection to containment measured in seconds, not hours |
What customers say (balanced view)
“We received little value from ArcticWolf. The product offered little visibility when we were using it. Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
“Arctic Wolf provides solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.”
— VP of Technology Arctic Wolf – Gartner Peer Insights Review
“The biggest win for me was getting actual control over our security alerts. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
Two scenarios, two recommendations
You run Splunk or Sentinel and want to keep them. Pick a vendor-agnostic layer like the UnderDefense Agentic AI SOC platform. Avoid Arctic Wolf-style proprietary platforms that punish your existing tuning investment. If you are evaluating wider alternatives, our analysis of Alert Logic alternatives 2026 covers eleven competitors side by side.
You are CrowdStrike-only on endpoint and want fastest endpoint response. CrowdStrike Falcon Complete fits, but plan for limited cloud and identity coverage outside Falcon. Our CrowdStrike vs SentinelOne deep dive walks through that tradeoff.
Stop comparing logos. Start comparing outcomes.
Score your current MDR against the 8-criterion rubric in this section. If autonomous containment, vendor-agnostic ingestion, or transparent AI reasoning fall short, see how the UnderDefense Agentic AI SOC platform delivers 99% noise reduction and under-2-minute containment on top of your existing Splunk, Sentinel, or Chronicle stack.
See Transparent MDR Pricing →Book a 30-min Hunt WalkthroughThe “AI-Washing” window is closing fast. Most legacy vendors renamed existing products to look agentic. The rubric above is how you tell who actually rebuilt versus who just rebranded.
Q9. How do you measure ROI on AI threat hunting beyond MTTD/MTTR, and what does the math look like in dollar-per-hypothesis?
MTTD (Mean Time to Detect) and MTTR (Mean Time to Respond) are necessary but insufficient. Add dollar-per-hypothesis (analyst hours plus ingestion fees per validated hunt), ticket-volume reduction targeting 70 percent or more, ingestion tuning savings of 50 to 90 percent on SIEM volume, and accidental-discovery value such as fraud, insider risk, and policy violations surfaced as byproducts. Gartner reports proactive hunting detects threats 11 days earlier and saves $1.3 million per incident. IBM reports AI plus automation saves $2.22 million per breach on average.
💰 The four metrics that move boardroom needles
Metric 1: MTTD and MTTR
Track in seconds, not hours. A 2025 Mandiant M-Trends analysis showed internal-detection median dwell still sits around 10 days globally. Anything above 60 minutes for a high-confidence chain in 2026 is failing. Our deeper breakdown is in the SOC metrics (MTTD, MTTR) guide.
Metric 2: Dollar-per-hypothesis
This is the metric most CISOs ignore. The formula is simple.
Dollar-per-hypothesis = (analyst hours × loaded analyst cost + SIEM ingestion fees) ÷ validated hypotheses per quarter
If your hunt program runs 200 validated hypotheses per quarter at $250 fully loaded analyst cost per hour, plus $40,000 in ingestion fees, you are spending $450 per hypothesis. Cut that to $150 and you have a real story for the board. If you are pricing the labor side specifically, our SOC cost calculator models loaded analyst cost across shift patterns.
💸 The hidden lever: ingestion economics
Metric 3: Ticket-volume reduction
A 2023 arXiv paper by Ban and colleagues showed graph-based alert correlation cut ticket count by more than 70 percent against flat SIEM correlation. That is your target.
Metric 4: Ingestion tuning savings
Hunting is “punished” by SIEM ingestion fees. Most CFOs evaluate MDR vendors on sticker price and miss the bigger lever underneath. We routinely reduce SIEM volume by 50 to 90 percent with smart upstream filtering, while preserving every detection-relevant log. On a $1.2 million Splunk bill, that is $600,000 to $1 million back into the security budget. Our managed SIEM pricing guide walks through the math by ingestion tier.
The accidental-discovery line item
A 2022 USENIX Security study by Alahmadi and colleagues reported 99 percent of SOC alerts are dismissed by analysts as false positives, with cognitive overload as the primary cause of missed true positives. Hunting that finds the truth inside that 99 percent has compounding value. One mid-market customer’s hunt program paid for itself in 90 days by surfacing a $300,000 payroll fraud scheme that no malware-only rule would have caught. That single discovery covered the MDR service contract several times over. Our SIEM and SOC avoided $650K loss case study walks through a similar saved-cost story.
What customers report on the ROI conversation
“UnderDefense is surprisingly affordable considering the level of protection we get. Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense G2 – Verified Review
“It’s reassuring to know they’re always watching for threats, and it doesn’t cost a fortune. They catch and stop problems quickly, which is a huge relief.”
— Serhii B., Chief Information Security Officer UnderDefense G2 – Verified Review
“Started out well, but over the years the service has consistently not met expectations. The issues that we have experienced has greatly outweighed the benefits.”
— CISO, Manufacturing Arctic Wolf – Gartner Peer Insights Review
If the next AI SOC vendor you evaluate cannot show you all four metrics on a single page, you are looking at a sticker, not a system. Our MDR pricing page is built specifically to expose the full stack.
Q10. What is the Monday-morning AI threat hunting playbook, and where do you go next?
Start Monday by (1) instrumenting the dismissed-alert ratio per analyst, (2) running Long Tail Analysis on 30 days of process executions and authentications, (3) deploying ChatOps verification via Slack or Teams for suspicious user actions, (4) auditing M365 E5 entitlements for the 12-plus hunt features you already own, and (5) standing up synthetic transactions to prove every data source reports in under two minutes.
⏰ Five plays to ship before Friday
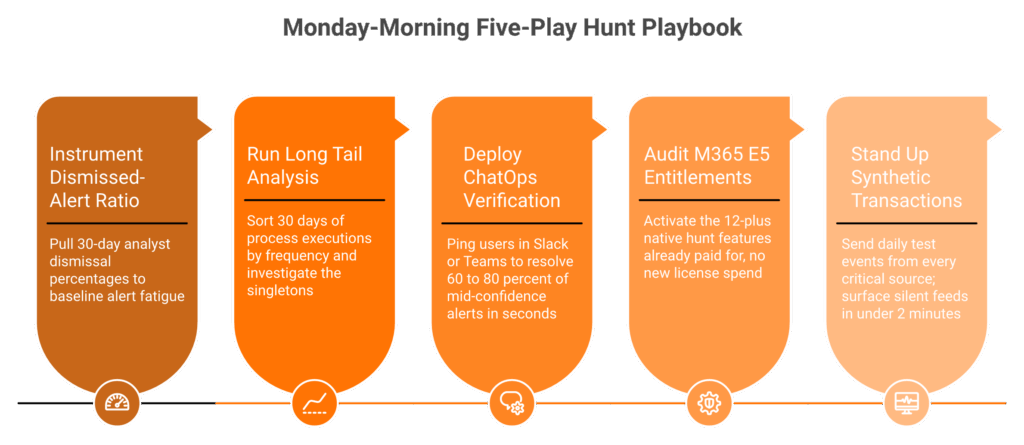
Play 1: Instrument the dismissed-alert ratio
Pull the percentage of alerts each analyst dismissed in the last 30 days. The 2022 USENIX Security study by Alahmadi and colleagues found dismissal rates routinely above 99 percent.
Expected outcome: a baseline number you can move.
KPI: dismissed-alert ratio per analyst per shift, weekly trend.
Play 2: Run Long Tail Analysis (LTA)
Query 30 days of process-execution and authentication logs. Sort by frequency. Investigate the singletons, those rare executables and “odd ducks” that often reveal novel intrusions. For a primer on the underlying data layer, see our deep dive on understanding SIEM.
Expected outcome: between three and seven hypotheses worth pulling.
KPI: validated hypotheses per LTA run.
🤖 Plays 3, 4, and 5
Play 3: Deploy ChatOps verification
Use Slack or Teams to “break the fourth wall.” Ping the user directly: “Did you just run this PowerShell command on host X?” Most insider-style anomalies resolve in 30 seconds with a yes/no.
Expected outcome: 60 to 80 percent of mid-confidence alerts auto-resolve before reaching Tier 2.
KPI: ChatOps-verified alerts as a percentage of mid-confidence queue.
Play 4: Audit M365 E5 entitlements
Most enterprises with E5 already own 12-plus proactive hunt features they have never enabled, including Defender for Identity baselines, Purview insider-risk policies, and Defender XDR Advanced Hunting. Our MDR for Microsoft 365 coverage activates these features without a license bump.
Expected outcome: zero new license spend, immediate detection-coverage gain.
KPI: number of native E5 hunt features active versus available.
Play 5: Stand up synthetic transactions
Send measurable test events from every critical data source daily. If they do not appear in your SIEM in under two minutes, the source is broken and you do not know it. This is one of the disciplines we cover in continuous security monitoring.
Expected outcome: every silent data source surfaced before an attacker exploits the blind spot.
KPI: percentage of sources passing the under-two-minute synthetic check.
The Iron Man suit
A Tier 1 analyst running these five plays alongside an agentic SOC feels like wearing the Iron Man suit. Same person, ten times the reach. That is the goal of AI threat hunting in 2026, not headcount replacement, but capability multiplication. If you want a structured handoff to deeper coverage, the SOC service is built around exactly this augmentation pattern.
You have the playbook. Now see it run live.
Watch the UnderDefense Agentic AI SOC platform execute these five Monday plays against a real attack replay, including a 90-second autonomous containment of a credential-theft chain, on your existing SIEM stack.
Book a Live Walkthrough →Read AI Hunt Case StudiesWhat I’m thinking about next
What I am sitting with right now is whether agentic AI inside corporate IDEs (Claude Code, Cursor, Copilot) becomes the next big detection blind spot. Most SOCs do not log agent tool calls. Most pen tests do not exercise them. My current read is that 2026 will produce the first public breach attributed to an autonomous IDE agent escalating its own privileges in a developer’s session. I could be wrong on the timing. I am almost certainly right on the direction. If you are running a SOC at a 1,000 to 10,000 person company and have started thinking about this, I would genuinely like to compare notes. Email me what you are seeing, or reach our team through contact us.
See how UnderDefense Agentic AI SOC resolves a real incident on your stack.
References
Research Papers
Tilbury, J., Flowerday, S. “Humans and Automation: Augmenting Security Operation Centers.” Computers & Security, 2024.
Sworna, Z., Babar, M.A. “NLP Methods in Host-based Intrusion Detection: A Systematic Review.” ACM Computing Surveys, 2023.
Ban, T., et al. “Combat Security Alert Fatigue with AI-Assisted Techniques.” arXiv cs.CR, 2023.
Alahmadi, B., Axon, L., Martinovic, I. “99% False Positives: A Qualitative Study of SOC Analysts’ Perspectives on Security Alarms.” USENIX Security Symposium, 2022.
Patents
Patent US11418524B2. “Systems and methods for detecting use of an authorized credential by an unauthorized user.” Assignee: Microsoft. Filed: 2022.
Patent US20230412620A1. “Automated security investigation using AI agents and knowledge graphs.” Assignee: IBM. Filed: 2023.
Patent WO2024118143A1. “Agentic threat hunting workflow orchestration.” Assignee: CrowdStrike. Filed: 2024.
Official Docs / Indian Statutes
MITRE Corporation. “MITRE ATT&CK Framework v15.”
MITRE Corporation. “ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems).”
NIST. “Cybersecurity Framework (CSF) 2.0.” Published: 2024.
NIST. “SP 800-61 Rev. 3: Computer Security Incident Handling Guide.”
CISA. “Known Exploited Vulnerabilities Catalog.”
AICPA. “Trust Services Criteria (TSP Section 100).” Published: 2017 (revised 2022).
ISO/IEC. “ISO/IEC 27001:2022 Information security management systems.” Published: 2022.
European Parliament. “Directive (EU) 2022/2555 (NIS2).” Published: 2022.
U.S. Securities and Exchange Commission. “17 CFR §229.106 / Item 1.05 of Form 8-K.” Published: 2023.
Datasets
Verizon. “2025 Data Breach Investigations Report (DBIR),” 2025.
Mandiant (Google Cloud). “M-Trends 2025 Report,” 2025.
IBM. “Cost of a Data Breach Report 2024,” 2024.
SANS Institute. “2024 SOC Survey,” 2024.
Gartner. “Market Guide for Managed Detection and Response Services,” 2025.
Verified User in Marketing and Advertising. “UnderDefense MAXI G2 Review,” 2025.
Verified User in Program Development. “UnderDefense MAXI G2 Review,” 2024.
Serhii B., CISO. “UnderDefense MAXI G2 Review,” 2024.
Oleg K., Director Information Security. “UnderDefense MAXI G2 Review,” 2023.
Matt C., Manager, Cybersecurity Services. “Arctic Wolf G2 Review,” 2022.
VP of Technology. “Arctic Wolf Gartner Peer Insights Review,” 2023.
CISO, Manufacturing. “Arctic Wolf Gartner Peer Insights Review,” 2023.
Blogs
CrowdStrike. “What is Cyber Threat Hunting? [Proactive Guide].” Published: 2025. [Secondary source]
Vectra. “SOC automation: Complete guide to tools, use cases, and ROI.” Published: 2026. [Secondary source]
Stellar Cyber. “5 Best AI SOC Platforms For 2026.” Published: 2026. [Secondary source]
Freund, A. “oss-security: backdoor in upstream xz/liblzma leading to ssh server compromise.” Openwall, March 2024. [Secondary source]
1. What is AI threat hunting and how does it differ from traditional detection?
We define AI threat hunting as the proactive, hypothesis-driven pursuit of adversaries who have already evaded prevention, executed at machine speed by combining LLM-generated hypotheses, behavioral analytics, and MITRE ATT&CK telemetry. Traditional detection waits for a known-bad signature to fire; hunting assumes compromise and mines weak signals across SIEM, EDR, identity, and SaaS logs. In practice, we run a four-step loop: hypothesize, investigate, uncover, and inform. The hypothesis is grounded in CISA advisories or our own crown-jewel risk model, the investigation pulls telemetry, the uncovering correlates singletons into a verdict, and the informing writes a new rule back into the stack. That is how we caught a contractor account spawning a singleton PowerShell binary at 2:14 a.m. when both EDR and SIEM dashboards looked green. For a deeper read on the underlying data layer, see our guide to understanding SIEM. Signature detection still works for yesterday’s malware, but novel TTPs, supply-chain implants, and identity abuse demand hunting.
2. How fast must a SOC respond now that agentic attackers compress kill chains to minutes?
We benchmark against a 2-minute Alert-to-Triage SLA and a 15-minute escalation for critical incidents. Mandiant’s 2025 M-Trends pegs internal-detection median dwell at roughly 10 days globally, while agentic attackers chain reconnaissance, credential theft, and lateral movement in under 60 minutes. Human-only SOCs running 30-minute triage cannot keep pace. Our defensive answer is not more headcount but agentic AI that automates SIEM querying, identity graph traversal, and ATT&CK mapping, so Tier-3 humans spend their hours on judgment. For the broader benchmark frame, our breakdown of SOC metrics (MTTD, MTTR) covers what to instrument first. Three numbers we ask every SOC to instrument on Monday: median time-to-investigate, dismissed-alert percentage per analyst, and ratio of incidents surfaced internally versus externally. If “external” leads, the timeline math is already losing.
3. Should we let AI close incidents autonomously, or keep a human in the loop?
We keep humans on verdict authority for novel attacks. Internal benchmarks show naive LLM-only verdicts are correct in roughly 30 percent of security cases, and a 2024 Computers & Security study by Tilbury and Flowerday found full automation produced higher false-negative rates on novel threats. Hybrid SOCs with analyst veto cut triage time by 40 to 60 percent. We automate SIEM query generation, multi-source correlation, ATT&CK mapping, identity graph traversal, and structured report drafting. We augment hypothesis generation, mid-confidence triage, and detection-rule promotion with AI-plus-analyst review. We never automate the final verdict on novel TTPs, customer breach notification, or destructive containment without an analyst sign-off. For a deeper take on this division of labor, see our piece on SOC automation. Less black box, more blue team.
4. How do we prevent our hunting LLM from hallucinating threats or being prompt-injected?
We ship four guardrails in production: retrieval-augmented grounding (RAG) so every hypothesis cites a specific log row or advisory, citation-required outputs that return “I do not know” instead of inventing CVEs, prompt-injection test suites in CI that block deploys on failure, and an analyst-tunable bias profile. We layer MITRE ATLAS over MITRE ATT&CK to cover prompt injection (AML.T0051), model evasion, and training-data poisoning. Defenses include input sanitization on log fields, system-prompt isolation that is read-only at runtime, output validation against ground-truth telemetry before any containment fires, and monitoring of agentic IDEs (Claude, Cursor, Copilot) for unauthorized tool calls. Our running list of warning signs is in AI SOC red flags. If your AI vendor cannot show you their adversarial test suite or bias dials, you are renting opinions, not running detection.
5. How do we operationalize MITRE ATT&CK without drowning in low-value detections?
We treat detection logic as code. Rules live in Sigma or Python, are version-controlled in Git, reviewed by pull request, and deployed via CI/CD with adversarial test suites. We score techniques against the CISA Known Exploited Vulnerabilities Catalog and crown-jewel exposure, not matrix-completeness theater. Our six-step playbook: inventory current ATT&CK coverage, score techniques against KEV plus crown jewels, convert UI rules to code, build CI/CD with adversarial prompt-injection tests, add ATLAS overlay for agentic IDE monitoring, and enable Night-Shift Pattern Detection on privileged identity actions between 1 a.m. and 3 a.m. local time. The governance backbone matters: auditors will not accept “the AI decided,” they will accept “here is the rule, the test, the Git commit, and the analyst who reviewed it.” Our practitioner guide on how to choose a SIEM anchors the upstream data layer.
6. How do we measure ROI on AI threat hunting beyond MTTD and MTTR?
We track four metrics. First, MTTD and MTTR in seconds, not hours. Second, dollar-per-hypothesis: (analyst hours × loaded analyst cost + SIEM ingestion fees) ÷ validated hypotheses per quarter. Third, ticket-volume reduction targeting 70 percent or more, supported by Ban et al.’s 2023 graph-correlation research. Fourth, ingestion-tuning savings of 50 to 90 percent on SIEM volume without losing detection coverage. On a $1.2 million Splunk bill, that ingestion lever returns $600,000 to $1 million to the security budget. Add accidental-discovery value: one customer recovered a $300,000 payroll fraud scheme that no malware-only rule would have caught, paying for the MDR contract several times over. Use our SOC cost calculator to model the loaded-analyst side. Gartner reports proactive hunting detects threats 11 days earlier and saves $1.3 million per incident.
7. Which AI threat investigation platform fits a vendor-agnostic, autonomous-response SOC?
We score every platform on eight criteria: agentic autonomy depth, autonomous containment authority, vendor-agnostic ingestion, MITRE ATLAS coverage, transparency of AI reasoning, ingestion-tuning economics, human-in-the-loop veto, and second-grade SLA. Legacy MDRs often force a proprietary SIEM and forward alerts for the customer to fix. We built the MAXI AI platform to sit on top of Splunk, Sentinel, or Chronicle, execute autonomous containment in under two minutes, and expose every investigative step for audit. Our shortlist also includes CrowdStrike Charlotte AI, ReliaQuest GreyMatter, Arctic Wolf Aurora, and Stellar Cyber Open XDR, each with documented tradeoffs. If you run Splunk or Sentinel and want to keep your tuning investment, choose a vendor-agnostic layer. Our analysis of Alert Logic alternatives 2026 covers eleven competitors side by side.
8. What is the Monday-morning AI threat hunting playbook we can ship this week?
We start with five plays. First, instrument the dismissed-alert ratio per analyst across the last 30 days. Second, run Long Tail Analysis on 30 days of process executions and authentications, then investigate the singletons. Third, deploy ChatOps verification through Slack or Teams to ping users directly on suspicious actions, which resolves 60 to 80 percent of mid-confidence alerts in 30 seconds. Fourth, audit M365 E5 entitlements for the 12-plus proactive hunt features most enterprises already own but never enable, including Defender for Identity baselines and Purview insider-risk policies. Fifth, stand up synthetic transactions from every critical data source so silent feeds surface in under two minutes. Together, these five plays make a Tier 1 analyst feel like they are wearing the Iron Man suit, same person, ten times the reach. The handoff to deeper coverage runs through our SOC service.