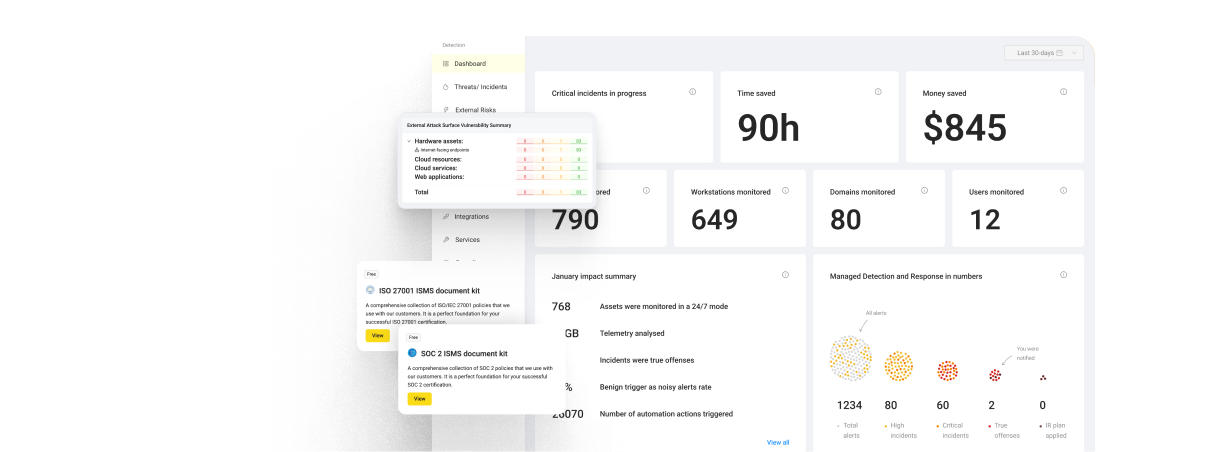
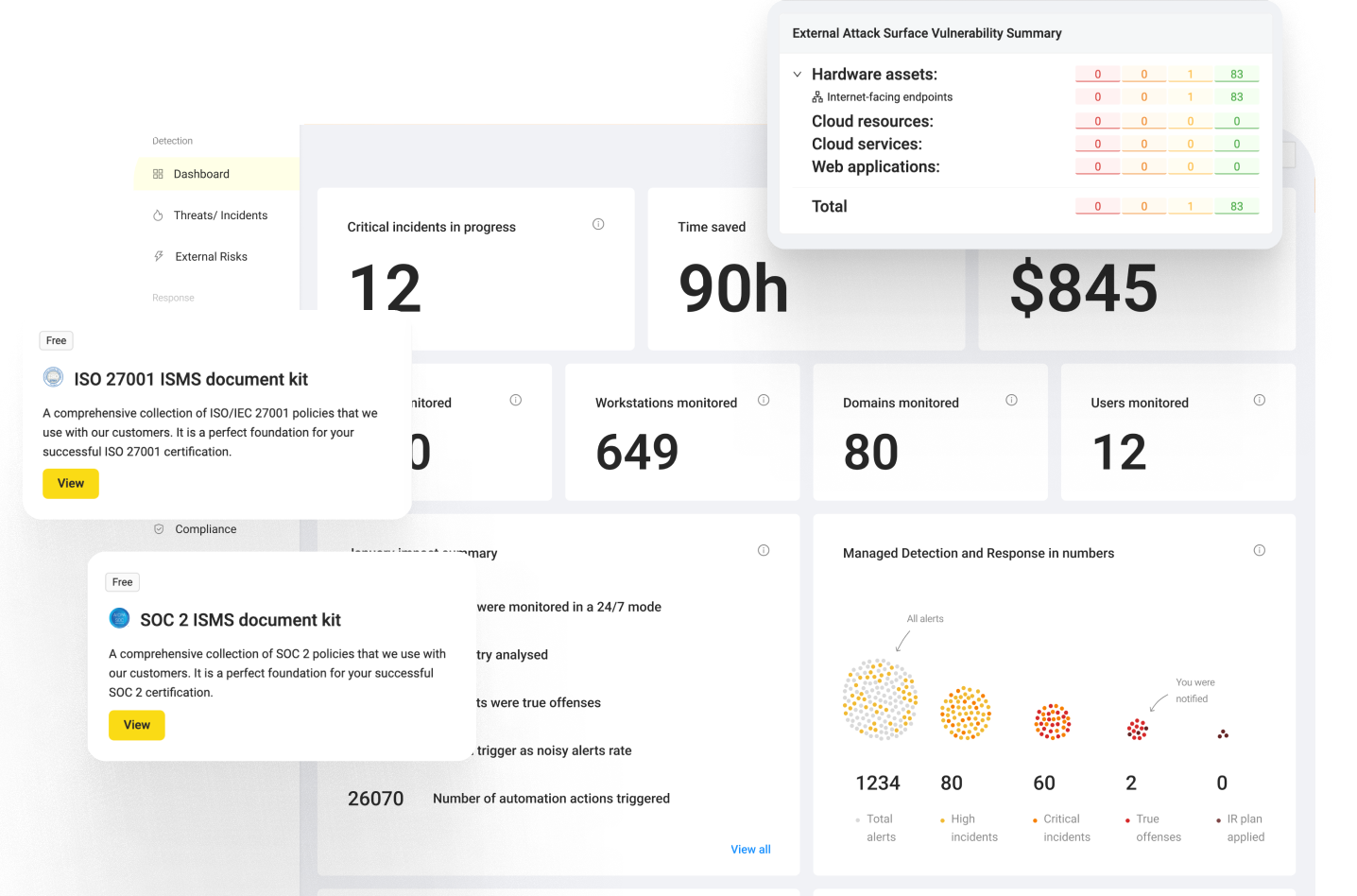
Q1. Why Has the SOC Hit a Wall in 2026, and What Does “AI in Security Operations” Actually Solve?
AI in security operations means using machine learning and agentic AI to automate the mechanical investigation work, querying SIEMs (Security Information and Event Management platforms), pulling logs, correlating signals, and producing a verdict, that a Tier 1 analyst would otherwise drown in. In 2026, the average SOC handles 300 to 400 alerts per analyst per week, and roughly 90% are benign. Meanwhile, attackers using agentic AI compress reconnaissance to exploitation into minutes, which makes manual triage mathematically impossible.
The 2 a.m. Bridge That Started This Article
A CISO at a 4,200-person fintech in New Jersey called me on a Sunday at 2:14 a.m. Her Tier 1 queue had 612 unread alerts from Friday. The on-call engineer, Maya, had been pivoting between Splunk, CrowdStrike, and Okta for four hours on a single suspicious sign-in. By the time we joined the bridge, the user had been logged in for six hours. Nothing was breached. Everyone was exhausted. That is the wall. ⚠️
The Math Most Decks Skip
The 2025 SANS SOC Survey found that 85% of SOCs still trigger primarily on endpoint alerts, while 62% of teams say their organization is not doing enough to retain staff. The 2025 Verizon DBIR reports that nearly 60% of breaches involve a human element, often through stolen or misused credentials. The 2025 IBM Cost of a Data Breach Report shows the global average dropped 9% to USD 4.44 million, and the catalyst was AI-powered defense compressing containment time. The signal is clear. Humans alone cannot read 4,000 alerts before Monday’s exec review.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
What “AI in Security Operations” Actually Means
Strip the marketing layer off, and AI in security operations does four jobs. It enriches alerts (asset, identity, threat intel) without an analyst clicking. It correlates signals across SIEM, EDR (Endpoint Detection and Response), and IdP (Identity Provider) without a human writing the join. It scores intent against MITRE ATT&CK so the verdict is reasoned, not vibes. It writes the case narrative in plain English so a Tier 3 reviewer reads, not types. ✅
Think of it as the Iron Man suit, not the replacement pilot. The human still flies. The suit handles the grunt work. For a deeper view on this trade-off, see our take on whether AI kills or saves your SOC team.
The Open Loop You Need to Hold
Here is the part most vendors will not say on stage. In our experience running MDR (Managed Detection and Response) across 500-plus customer environments, AI on its own returns the right verdict in roughly 30% of security cases. That is not a failure, but an operating constraint. The 70% that needs a Tier 3 human is exactly where most SOCs lose the game. Q4 unpacks why “AI SOC + Human Ally” beats full autonomy on every honest metric.
Q2. What Exactly Is an Agentic AI SOC, and How Is It Different from “AI-Washed” MDR and Legacy MSSPs?
An Agentic AI SOC is a SOC rebuilt around autonomous AI agents that plan and execute multi-step investigations end to end. AI-augmented MDR adds a chat box on top of an old queue. Autonomous SOC runs unsupervised and is rare in production. Agentic sits in the safe middle: AI does the mechanical 80%, a Tier 3 human validates the consequential 20%, and every step is observable.
Three Definitions in Plain English
There is real confusion here, so I want to name it cleanly.
- AI-augmented SOC. Your existing queue plus a GPT summary at the top. The workflow is unchanged. Most legacy MDR sits here.
- Agentic AI SOC. Specialized agents (triage, enrichment, correlation, response) that plan multi-step investigations and act on telemetry within seconds. A human approves the consequential calls.
- Autonomous SOC. No human in the loop. Production deployments are rare, and honest vendors say so.
If you are weighing options across the broader market, our AI SOC red flags guide walks through the patterns that separate hype from delivery.
The Multi-Agent Reference Architecture
A real agentic SOC has four agent classes wired together. ⭐
- A triage agent that reads the raw alert and pulls enrichment.
- An investigation agent that runs SIEM queries, EDR pivots, and IdP lookups in parallel.
- A correlation agent that maps activity to MITRE ATT&CK techniques and scores intent.
- A response agent that contains (revoke session, isolate host, reset credential) under human approval.
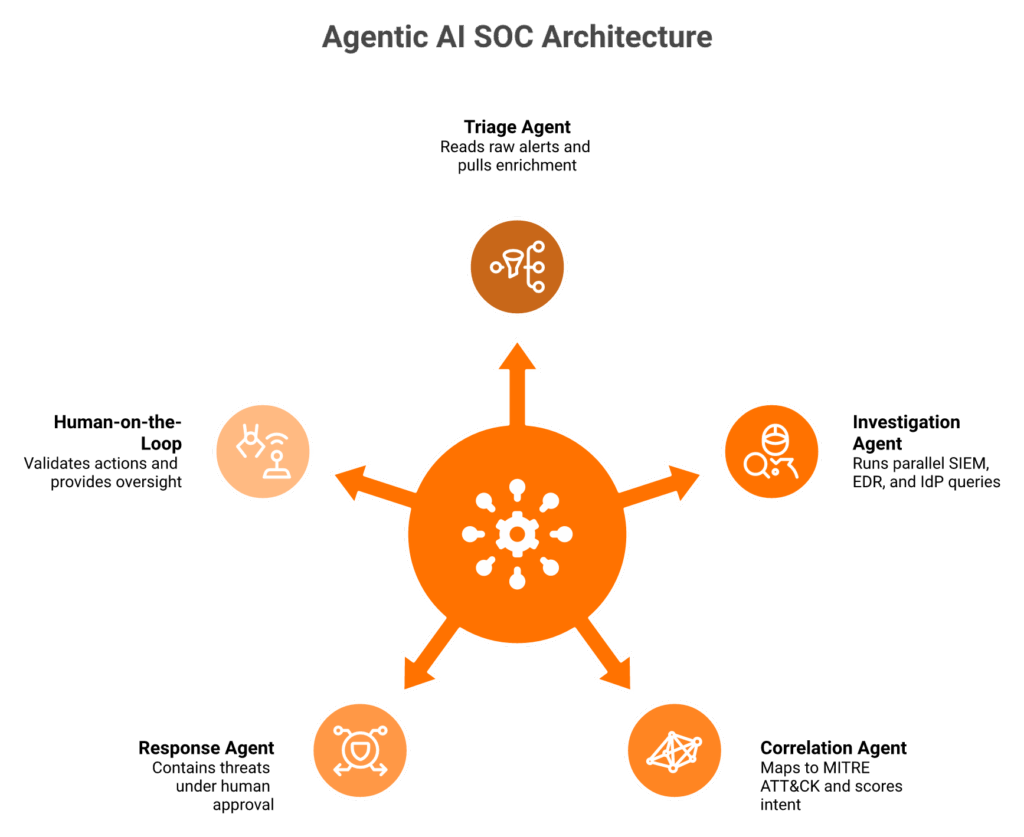
The 2025 SANS SOC Survey notes that 42% of SOCs deploy AI/ML “out of the box” with no tuning, which is exactly the failure mode this architecture is designed to avoid.
How the Market Actually Stacks Up
Position 1 is where I personally think buyers should start, and I will explain why honestly under each.
| Provider | Architecture | Stack Approach | Observability | Honest Limitation |
|---|---|---|---|---|
| UnderDefense Agentic AI SOC | Agentic, multi-agent, human-on-the-loop | BYO SIEM/EDR (Splunk, Sentinel, Chronicle, Elastic) | Every AI and human step audit-logged | Onboarding tuning takes 1 to 3 weeks |
| CrowdStrike Falcon Complete | AI-augmented, endpoint-centric | Falcon endpoint required | Closed analyst console | Limited identity and SaaS visibility |
| Arctic Wolf | Operationalized, “Concierge” model | Proprietary platform (Aurora) | Black-box triage | Re-buy detections you already own |
| ReliaQuest GreyMatter | AI-augmented orchestration | GreyMatter platform required | Customer dashboard, limited query | Lock-in to GreyMatter data model |
The “Rebuilt vs Renamed” Buyer Test
Ask the vendor for a live, multi-step investigation on your telemetry, not a recorded demo. If their “agent” only writes a summary of an alert your analyst already triaged, that is renaming. If it queries the SIEM, pivots to EDR, checks the IdP, and writes a verdict you can reproduce, that is rebuilt. ❌ “AI-washed” decks fail this test in 90 seconds. Our MDR buyers guide includes the full RFP question set.
“The platform itself is straightforward, it pulls in data from all our existing security tools, so we didn’t have to rip and replace anything.”
— Verified User in Marketing and Advertising, UnderDefense G2 – Verified Review
In our experience shipping UnderDefense Agentic AI SOC, the rebuilt approach is what unlocks the 99% noise reduction we measure on customer queues. Renamed product decks do not.
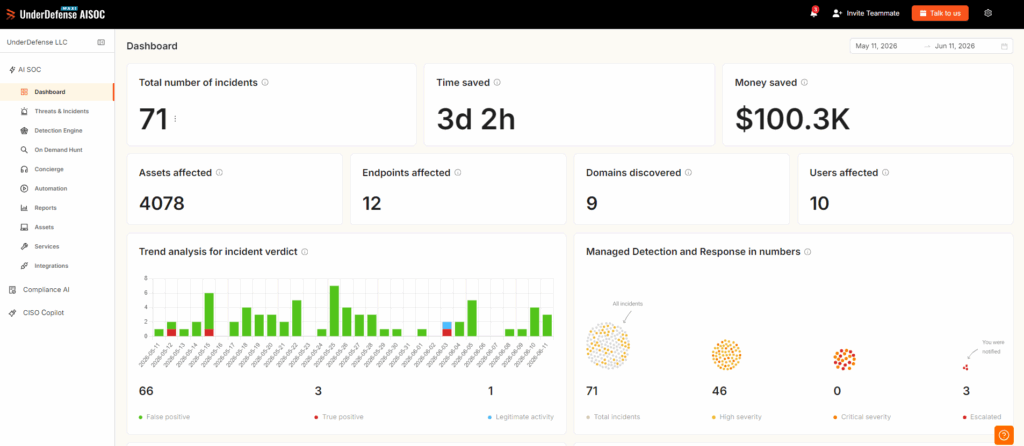
Q3. How Does AI Actually Eliminate Alert Fatigue Across Triage, Investigation, Hunting, and Response?
AI compresses the four SOC workflows. Triage runs under a 2-minute Alert-to-Triage SLA, versus 30 to 60 minutes with human pivots. Investigation uses multi-step agentic queries that replace analyst tab-switching. Hunting uses behavior-anomaly clustering at scale. Response performs autonomous containment in under two minutes (credential wipes, host isolation, ticket creation), with a 15-minute escalation SLA for critical incidents. IBM measures a 55% triage acceleration with AI agents. The lever is not tuning harder, but automating the mechanical 80%.
The Triage Pipeline (Where the 2-Minute SLA Lives)
In our UnderDefense Agentic AI SOC environment, triage is a four-step pipeline. ⏰
- Ingestion. Telemetry lands from SIEM, EDR, and IdP. We tune ingestion to cut volume by 50 to 90%.
- Enrichment. The agent pulls asset owner, user role, threat intel, and recent behavioral baseline.
- Correlation. Signals are mapped to MITRE ATT&CK v15 techniques and scored.
- Verdict. A reasoned narrative is written. False positive closes. True positive escalates.
We hold a 2-minute Alert-to-Triage SLA on critical alerts and a 15-minute escalation SLA for confirmed criticals. That is the benchmark to hit. Commoditized SOC partners often run 30 to 60 minutes on the same alert class. For deeper context, see our breakdown of SLA in cybersecurity.
Investigation: Multi-Step Agents Beat Tab-Switching
The mechanical part of investigation is “did this user really do this.” A good agent runs five to seven queries in parallel. It checks Okta sign-in geo, EDR process tree, DLP (Data Loss Prevention) flags, and recent ticket history. It returns one paragraph with citations to the underlying queries. A human still owns the verdict on consequential cases.
“Now when we get an alert, we know it’s something worth looking into. Their SOC team is responsive and knows their stuff. When they escalate something, they include the context we need to understand the issue quickly.”
— Verified User in Marketing and Advertising, UnderDefense G2 – Verified Review
Hunting and Response: Where Speed Becomes Currency
Hunting at scale is behavior-anomaly clustering. The agent groups identities by typical access pattern and surfaces drift (new SaaS, new geography, new admin grant). Mandiant M-Trends 2025 documents median dwell time continuing to fall, which is exactly what behavior-led hunting compresses.
Response is where most vendors stall. We perform autonomous containment in under two minutes for high-confidence incidents: credential wipe, session revoke, host isolation, and ticket creation. ✅ Then we ping the user directly in Slack, Teams, or SMS. “Did you just run this command from a Frankfurt IP?” That is what we call breaking the fourth wall. It closes the context gap that stalls every SOAR (Security Orchestration, Automation, and Response) playbook. Our case study on reducing MTTR to 9 minutes shows the same pattern in production.
Synthetic Transactions: Prove the Pipeline Is Alive
Working with global enterprises, the failure mode I see most is silent pipelines. A log source dies, no one notices, and three weeks later the pen test produces zero alerts. The fix is synthetic transactions. Run an automated eventcreate (or equivalent) every five minutes per data source. Alert if the event does not appear in the SIEM in under two minutes. It is unglamorous, and it is the difference between a working SOC and a dashboard. ⚠️
“Underdefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection. It also solved our problem of having separate security tools that didn’t work well together.”
— Inga M., CEO, UnderDefense G2 – Verified Review
Q4. Where Does AI Break Down, and Why Is the “AI SOC + Human Ally” Model Safer Than Full Autonomy?
Operational data shows AI returns the correct verdict in roughly 30% of security cases unaided. Full SOC autonomy is a high-stakes dice roll. The safer pattern is AI SOC + Human Ally. AI handles the mechanical 80%. A Tier 3 analyst validates the consequential 20%. Every step is observable. A measurably biased model you can correct beats an “unbiased” model you cannot inspect.
The Contrarian Claim: Bias Is a Feature
Most vendor decks promise unbiased AI. I think that is the wrong frame, and I might be wrong here, but hear me out. An unbiased model is unmeasurable, which makes it unmanageable. A measurably biased model tells you what it weighs and where it errs. You can correct it. You can audit it. You can defend it to a board. Less theater, more throughput. Less black box, more blue team.
The 30% Ceiling and the Silent Pen Test
A 2025 ACM Computing Surveys review of alert fatigue in SOCs concluded that the bottleneck is investigation capacity, not alert volume tuning. That matches what we see. AI alone is right about 30% of the time on consequential cases. A major prospect ran a full red-team exercise with lateral movement against their incumbent MDR last year. The result was zero alerts. ❌ Their “AI” had been a checkbox. The pen test exposed it. The fix was not more AI, but AI plus a Tier 3 human reviewing every consequential branch. A focused penetration testing engagement often surfaces the same gap.
The Human Ally Handoff Design
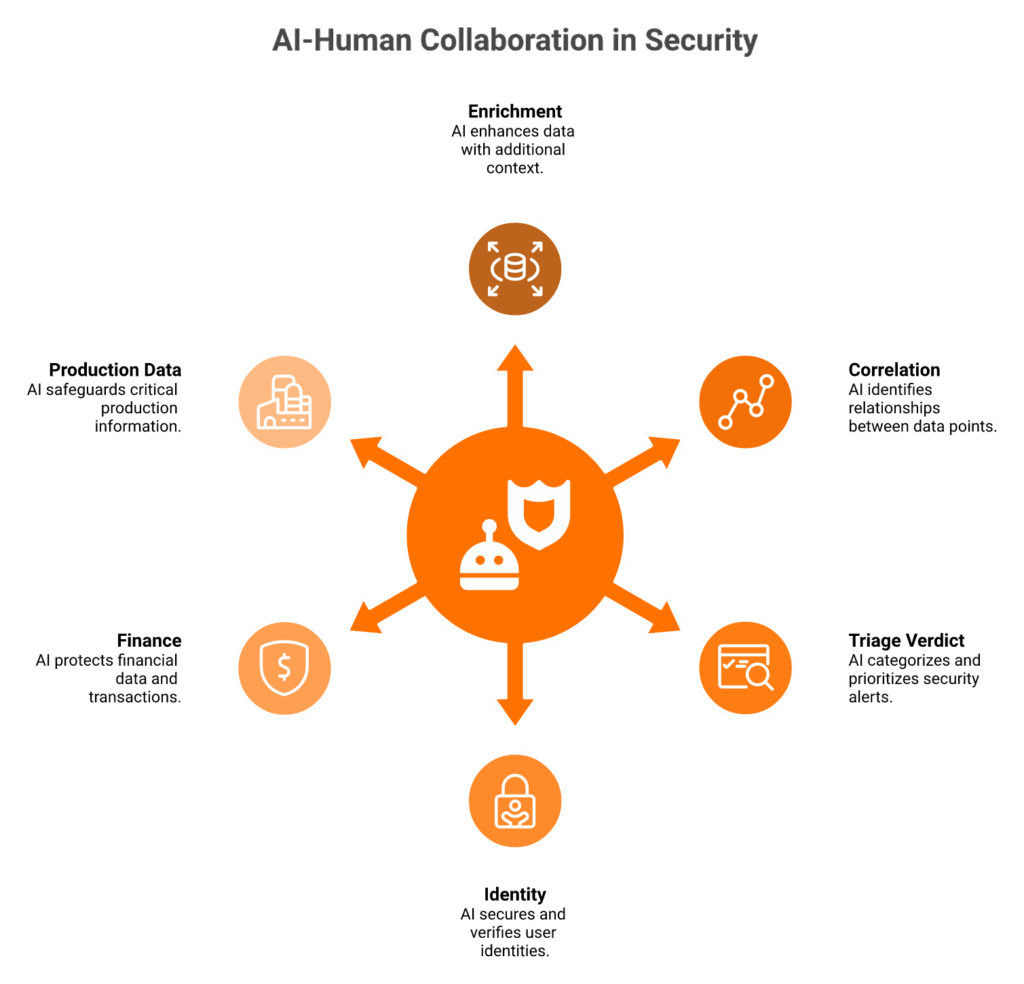
Working across 500-plus customer environments, the design that actually scales looks like this.
- AI handles enrichment, correlation, and the mechanical 80% of triage.
- A Tier 3 analyst validates the consequential 20%, anything touching identity, finance, or production data.
- Every action, by AI or human, is logged, time-stamped, and replayable.
- The customer can audit any case, any time. No dashboards behind a login wall.
This is the philosophy baked into the WarRoom platform, where every investigative step (AI or human) is observable in a single, replayable view.
“The reports from their platform give us clear evidence of our security controls and incident response capabilities. When auditors or clients ask questions about our security posture, we can pull up exactly what they need to see.”
— Verified User in Marketing and Advertising, UnderDefense G2 – Verified Review
What We Got Wrong (and What We Learned)
I will be honest. Early in UnderDefense Agentic AI SOC’s life, we leaned too hard on automation for low-confidence verdicts. We closed a handful of cases the AI scored “benign” that a human would have flagged. Nothing breached, but the pattern was a warning. We rebuilt the confidence threshold, added human-on-the-loop for any case touching privileged identity, and shipped the audit trail by default. ScienceDirect’s 2025 review of agentic AI in cybersecurity reaches a similar conclusion. Autonomy is not the goal. Observable, correctable agency is. For a tactical view of how this maps onto a working SOC, see our piece on SOC automation.
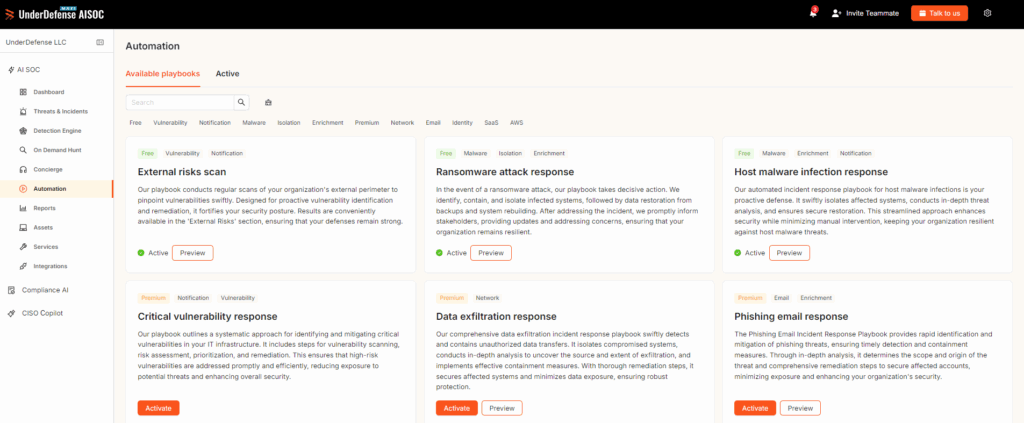
If a vendor cannot show you the cases their AI got wrong, walk away. The honest ones will. That is the test. ✅
Q5. How Should You Stage AI Adoption, A Crawl, Walk, Run Maturity Framework with Concrete KPIs?
Crawl (Initial to Managed): get SIEM in place, kill 50% of low-value telemetry, and track mean alerts per analyst per shift. Walk (Defined): adopt detection-as-code in Git, pilot one agentic triage agent, and track Mean Time to Contain (MTTC) and false-positive rate. Run (Quantitatively Managed to Optimizing): autonomous containment for two playbooks with human-on-the-loop, and track MTTR-to-contain plus dollar savings per quarter. Most enterprises sit at Walk. The next move is Run, not autonomy.
The Three-Stage Framework with KPIs
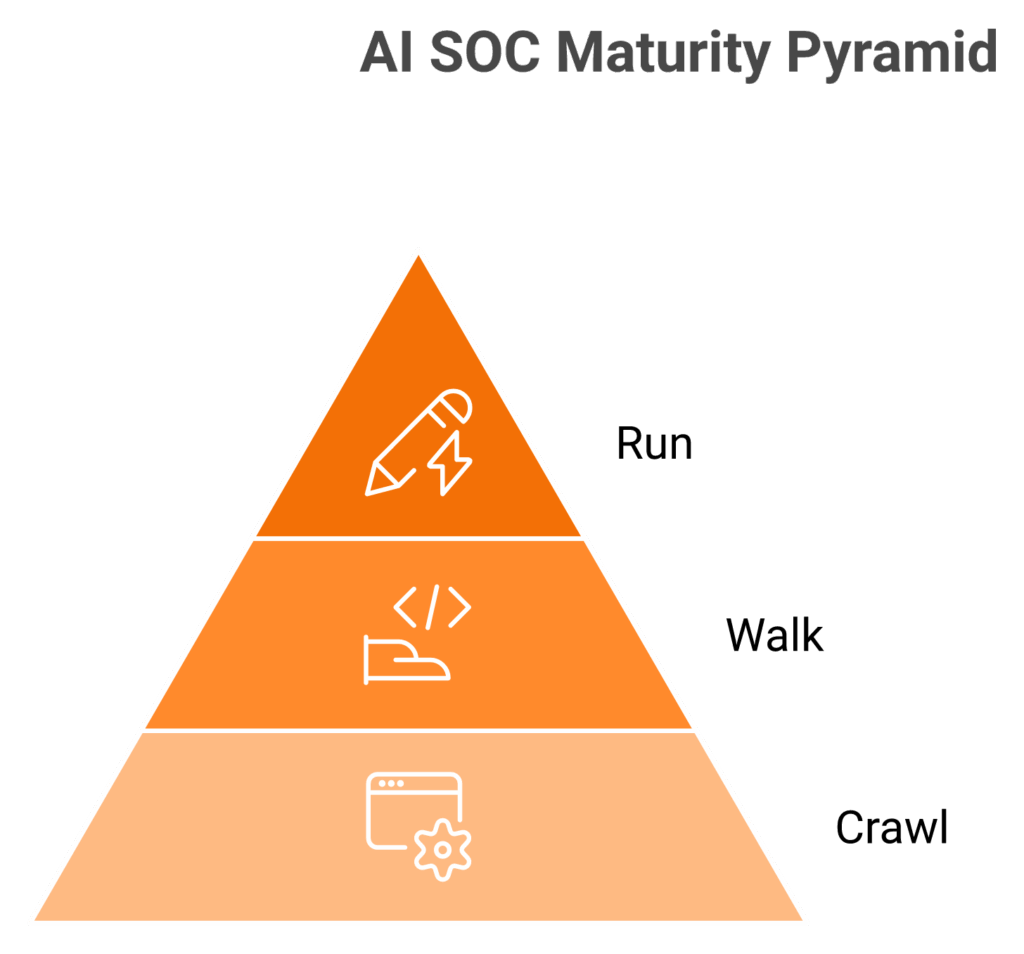
I draw this from the CMMI-style Alarm Processing Maturity Curve and the practical reality of running 500-plus customer SOCs. Here is the table I hand to CISOs on day one. ⭐
| Stage | What Good Looks Like | Primary KPI | Secondary KPI |
|---|---|---|---|
| Crawl | SIEM live, ingestion tuned, top 20 use cases mapped to MITRE ATT&CK | Alerts per analyst per shift (target under 60) | Telemetry volume cut 50% |
| Walk | Detection-as-code in Git, one agentic triage agent in production | MTTC (target under 15 minutes) | False-positive rate (under 10%) |
| Run | Two autonomous response playbooks, human-on-the-loop, full audit trail | MTTR-to-contain (under 5 minutes) | USD saved per quarter on toil |
The 2025 SANS SOC Survey confirms most SOCs report MTTD and MTTR without containment-specific tracking, which masks the real bottleneck. For a deeper view of which numbers matter, see our breakdown of SOC metrics like MTTD and MTTR.
Diagnostics: How to Tell Where You Actually Are
If your analysts paste alerts into Slack to ask “is this real,” you are at Crawl. If you have detection rules in Git but no PR (Pull Request) review, you are early Walk. If you can autonomously isolate a host but cannot show the audit log to your auditor, you are stuck between Walk and Run. ⚠️
NIST CSF 2.0 reframes this neatly under the Govern function. You cannot improve what you cannot measure or own. Teams scoping resourcing at this stage often weigh outsourced versus in-house SOC models against budget reality.
F3EAD as the Operational Loop
F3EAD (Find, Fix, Finish, Exploit, Analyze, and Disseminate) is the loop I recommend at Walk and Run. Find and Fix are AI-led. Finish is human approved. Exploit and Analyze feed detection-as-code back into Git. Disseminate is the briefing your CISO gives the board next quarter.
The “Ferrari in the SOC” Paradox
A prospect last year admitted they had been tuning Carbon Black for four years and never finished. They owned a Ferrari and never left first gear. ❌ This is the paradox. Enterprises buy Splunk Enterprise Security or Microsoft Sentinel, then run 12% of the features. Detection-as-code plus agentic AI is what gets the rest of the engine running. We have seen the same pattern in roughly 60% of the customer queues we audit. Many of these stalls trace back to cybersecurity technical debt that never got paid down.
Audit M365 E5 Before Buying Anything New
Before you buy a new AI SOC point tool, audit your Microsoft 365 E5 entitlements. Most enterprises already own Defender for Endpoint, Defender for Cloud Apps, Sentinel, Purview DLP, and Entra ID Protection. That is 12-plus security and logging capabilities that are paid for and unused. 💰 Microsoft’s own technical documentation lists the included features by SKU. Run that audit first. It often funds the next two stages of maturity without a new contract. Our MDR for Microsoft 365 practice is built around exactly this entitlement-first approach.
“It’s reassuring to know they’re always watching for threats, and it doesn’t cost a fortune. The platform works really well with our other security tools, which makes things much simpler.”
— Serhii B., CISO, UnderDefense G2 – Verified Review
Q6. Why Is Detection-Engineering-as-Code the 75% ROI Lever Most CISOs Underprice?
Forrester data on AI-driven SOCs shows the largest single ROI line is not Tier 1 triage. It is a 75% reduction in detection-engineering hours when rules are written like software. Treat detection logic as code. Use Python or Sigma, version it in Git, peer-review via Pull Request, and deploy through CI/CD with synthetic-transaction tests. AI agents then propose, test, and tune rules at machine speed while engineers approve the merge.
The Hidden ROI Line
Most ROI decks lead with “55% triage acceleration.” That is real, but it is not the biggest number. Forrester’s 2025 Total Economic Impact study on AI-augmented SOC platforms found detection-engineering hours fell by roughly 75% once rules were authored as code and tuned by AI. That is the line that funds the program. Our SOC cost calculator lets you model that line against your own headcount.
What Detection-as-Code Actually Looks Like
Here is the minimum viable pipeline. Any team running 1,000-plus endpoints can stand this up in a quarter. ✅
- Author rules in Sigma (open standard) or Python for richer logic.
- Store every rule in Git with a clear naming convention and MITRE ATT&CK mapping.
- Require Pull Request review by a second detection engineer.
- Run CI tests on every PR using historic telemetry plus synthetic events.
- Deploy through CI/CD to Splunk, Sentinel, Chronicle, or Elastic.
- Track rule efficacy (true positive rate, false positive rate, and time to fire) per rule.
The Sigma project, maintained on GitHub since 2017, gives you portable rule syntax across SIEMs without lock-in. Teams pairing this with our managed SIEM service typically reach Walk maturity inside a quarter.
AI-Proposed Rules with Human Approval
This is where agentic AI earns its keep. The agent reads new IOCs (Indicators of Compromise) and TTPs (Tactics, Techniques, and Procedures) from MITRE ATT&CK updates and threat intel feeds. It proposes a Sigma rule. It runs the rule against the last 30 days of customer telemetry. It reports the false-positive rate. The human engineer approves or rejects the merge. ⏰
In our experience shipping UnderDefense Agentic AI SOC, this loop turns a four-hour rule-writing task into a 20-minute approval task.
Synthetic Transactions: The Test Harness That Saves You
The unglamorous discipline is the synthetic test harness. For every data source, run an automated event every five minutes. A failed login from a known test IP. A whoami command on a canary host. Alert if the rule does not fire in under two minutes. ⚠️ This is how you catch silent pipeline failures before the pen test does. A focused penetration testing engagement is the right second-line check on this.
Anonymized Customer Snapshot
We took an anonymized pre-and-post snapshot from one mid-market customer queue earlier this year. Before detection-as-code: 4,200 weekly alerts, 38 detection rules, and no version control. After: 410 weekly alerts (90% noise reduction), 142 rules in Git, and 75% fewer hours spent on rule maintenance. The savings funded the entire MDR contract. 💸
“We used to be swamped with alerts, but now we can swiftly identify and address actual vulnerabilities, optimizing our response time.”
— Darina I., Customer Success Manager, UnderDefense G2 – Verified Review
The Splunk Detection Engineering Maturity Matrix puts most enterprises at level 1 or 2 of 5. Level 4 (CI/CD, peer review, and metrics) is where the 75% number lives.
Q7. What Does Adversarial AI Mean for Detection, and How Do You Secure the SOC’s Own AI Agents?
Attackers run agentic AI for recon, exploit selection, and lateral movement in minutes. They will target your defender AI next. Two jobs follow. One, shift detection toward identity-centric and behavior-centric signals (impossible-travel, OAuth-grant abuse, and AI-agent API calls) keyed to MITRE ATT&CK’s 2025 AI techniques. Two, govern your own AI agents. Scope service accounts narrowly, log every prompt and action, and red-team for prompt injection and model poisoning.
Bottom Line: Attackers Are Agentic Too
Mandiant M-Trends 2025 reports continued compression of dwell time and notes attackers using AI for phishing and reconnaissance at scale. The blast radius shifts from human operator speed to machine speed. ❌ For a deeper dive on this shift, see our piece on AI in cybersecurity.
The New TTPs to Detect
Three attacker patterns matter most for 2026 SOCs.
- Prompt injection against customer-facing chatbots and internal copilots.
- Deepfake business email compromise (BEC), including voice clones on finance approval calls.
- AI-agent API abuse, where stolen OAuth tokens drive Claude, Cursor, or Copilot in production.
OWASP’s 2025 LLM Top 10 lists prompt injection as risk number one and excessive agency as number six. Both map to detectable telemetry: failed tool calls, anomalous prompt patterns, and service accounts using new endpoints. Our guide to business email compromise covers the human-side controls that pair with these detections.
Detection Examples You Can Ship This Quarter
Three concrete rules I would write tomorrow. ⭐
- Alert on any AI service account (Copilot, Claude, or Cursor) calling a SaaS API outside its baseline.
- Alert on OAuth grant from a corporate identity to a non-allowlisted AI app within 60 seconds of sign-in.
- Alert on prompt content containing known jailbreak strings using regex plus an LLM classifier.
Map all three to MITRE ATT&CK. The 2025 update added explicit AI/ML techniques under T1648 and the new “Resource Development” sub-techniques.
Securing Your Defender AI
Here is the part most vendors skip. Your AI SOC is itself an attack surface. Treat it that way. ⚠️
- Scope every AI service account with least privilege RBAC (Role-Based Access Control).
- Log every prompt, every tool call, and every output to immutable storage.
- Run prompt-injection red teams quarterly against your own agents.
- Require human-on-the-loop for any agent action touching identity, finance, or production data.
- Monitor for model drift and unexplained verdict changes.
This governance discipline is built into the WarRoom platform, where every AI and human action is observable in a single, replayable view.
“Honestly, some security tools are more complicated than the threats themselves. Underdefense isn’t just about catching bad stuff, they give proactive tips too.”
— Andriy H., CTO at Contora Inc., UnderDefense G2 – Verified Review
AI Agent Governance: The TAM Legacy MDR Misses
Banning ChatGPT, Claude, or Cursor does not work. It just pushes them to personal devices. Shadow AI is a CISO blind spot, not a control. The honest move is to monitor what AI agents do in production. CISA’s 2025 advisories on AI risk explicitly call out agent-driven activity in enterprise environments. Working across global enterprises, my read is this is the next 18 to 24 months of MDR scope. Legacy providers are not built for it. Our MDR for AI practice exists for exactly this gap.
Q8. Vendor-Agnostic AI SOC vs. Proprietary-SIEM MDR, How Do You Avoid Tool Lock-In and Meet NIS2/SEC Disclosure Rules?
Most MDR providers force you onto a proprietary SIEM. That means re-buying detections you already wrote and surrendering your business logic. A vendor-agnostic AI SOC sits as a unified layer on top of Splunk, Sentinel, Chronicle, or Elastic. It preserves your detection IP and M365 E5 entitlements. It also makes regulatory evidence (SEC 8-K Item 1.05, NIS2 Article 23 reporting, SOC 2 Type II, and GDPR Article 33) auditable end-to-end because every action is logged in your tenant.
The Lock-In Tax
When a provider’s MDR only works on its own SIEM, three costs follow. First, you re-buy detection rules you already authored. Second, your data lives in their tenant, not yours. Third, switching costs explode at renewal. ❌ Our analysis of why businesses switch providers walks through the typical exit story.
“Anything you want to look at or changes you need to make in the product must go through their engineering team. As an MSP, this is a horrible way to do business for us.”
— Matt C., Manager, Cybersecurity Services, Arctic Wolf – G2 Verified Review
“Log collectors show working, however when asked to provide logs for an investigation no logs could be provided. Analysts provide little context.”
— CISO, Manufacturing (USD 3B to 10B), Arctic Wolf – Gartner Verified Review
How the MDR Market Stacks Up on Lock-In
| Provider | Stack Approach | Data Ownership | Deployment Options | Lock-In Risk |
|---|---|---|---|---|
| UnderDefense Agentic AI SOC | BYO SIEM/EDR (250-plus integrations) | Customer tenant | SaaS, hybrid, on-prem, or sovereign | ✅ Low |
| CrowdStrike Falcon Complete | Falcon required | Vendor cloud | SaaS only | ⚠️ Medium |
| Arctic Wolf | Aurora platform required | Vendor cloud | SaaS only | ❌ High |
| ReliaQuest GreyMatter | GreyMatter required | Vendor cloud | SaaS only | ❌ High |
| Expel | BYO stack | Customer tenant | SaaS | ✅ Low |
Forrester’s 2025 Wave on MDR rates BYO-stack architectures higher on flexibility and total cost of ownership. Our MDR buyers guide includes a side-by-side scorecard you can hand to procurement.
Deployment Sovereignty for NIS2 and GDPR
For Fortune 1000 buyers in the EU, telemetry residency is not optional. NIS2 Article 21 mandates risk-management measures that include supply-chain control. Article 23 sets 24-hour early-warning and 72-hour incident notification windows. GDPR Article 33 requires breach notification within 72 hours. If your AI SOC ships your logs to a US-only cloud, your DPO is already drafting an exception. We deploy UnderDefense Agentic AI SOC on-prem, hybrid, or in-region for exactly this reason. Teams running EU regulated workloads should also review our compliance services.
Standards Mapping: Where AI SOC Evidence Lives
| Requirement | Evidence the AI SOC Must Produce |
|---|---|
| NIST CSF 2.0 (Detect, Respond) | Time-stamped detection and response logs per case |
| MITRE ATT&CK | Technique mapping per detection rule |
| NIS2 Art. 23 | 24-hour early warning, and 72-hour incident report |
| SEC Form 8-K Item 1.05 | Materiality determination evidence within 4 business days |
| SOC 2 Type II | Continuous monitoring controls and audit trail |
| GDPR Art. 33 | Breach notification timeline and scope |
The SEC’s cyber-disclosure rule is the one that catches public-company CISOs off-guard. The 4-business-day materiality clock starts when you decide an incident is material, not when you contain it. Your AI SOC must produce that timeline cleanly. ⏰ Our incident response playbooks are built around exactly this clock.
“Our IT team was overwhelmed by the sheer volume of security alerts and doesn’t have the resources for 24/7 monitoring.”
— Andriy H., Co-Founder and CTO, UnderDefense G2 – Verified Review
Working across 500-plus customer environments, what I have noticed is the providers who promise “transparency” rarely show their work. Ask any vendor for a live, replayable case audit on a recorded incident. The honest ones will. That is the test.
Q9. How Do You Measure AI SOC ROI in Numbers Your CFO and Board Will Actually Accept?
AI SOC ROI lands on three lines. One, breach-cost avoidance: IBM 2025 shows AI and automation users save roughly USD 1.9 million per breach and contain incidents 80 days faster. Two, operating leverage: 99% noise reduction and 50 to 90% ingestion savings free 1.5 to 3 FTEs (Full-Time Equivalents). Three, compliance acceleration: SOC 2, ISO 27001, and NIS2 evidence collection automated. One UnderDefense customer’s MDR paid for itself in three months by catching a USD 300,000 payroll-fraud scheme that malware-focused tools missed.
The Three-Line ROI Formula
Most ROI decks try to be clever. CFOs do not want clever. They want three lines on a page. ⭐
| ROI Line | Metric | Source |
|---|---|---|
| Breach-cost avoidance | USD per avoided incident, and days faster to contain | IBM CODB 2025 |
| Operating leverage | FTEs freed, ingestion cost cut, and alerts per analyst | Forrester TEI 2025 |
| Compliance acceleration | Audit hours saved, and evidence-collection automation | SANS SOC Survey 2025 |
Hand the CFO this table on the first page. Every other slide supports one of the three lines. The 2026 cybersecurity budget playbook shows how to wire these three lines into your annual ask.
The Breach-Cost Math
The 2025 IBM Cost of a Data Breach report shows organizations using extensive AI and automation contained breaches 80 days faster and saved an average of USD 1.9 million per incident. Forrester’s 2025 Total Economic Impact analysis on AI-augmented SOC platforms reports a 193% three-year ROI and roughly 60% breach-risk reduction for a USD 6.5 million net benefit at a composite enterprise. Pair these with your own annualized loss expectancy. The board math gets short fast. 💰 Our SOC cost calculator turns those benchmarks into your own numbers.
Operating Leverage: Where Hours Become Dollars
The toil penalty is real. The 2025 SANS SOC Survey notes that 81% of teams report higher workloads after adding complex tools, not lower. AI automation has to target the mechanical 80% (enrichment, correlation, and ticketing). When we tune ingestion 50 to 90% on customer SIEMs, the savings often fully fund the MDR contract. ⏰ One mid-market customer freed 2.4 FTEs of Tier 1 work in the first quarter and reallocated them to detection engineering. Our SIEM and SOC case study where a customer avoided a $650K loss shows the same lever in production.
Compliance Acceleration
Auditors do not pay for tools. They pay for evidence. An AI SOC with full audit trails compresses SOC 2 Type II, ISO 27001 Annex A.16, and NIS2 Article 23 reporting from manual screenshot collection to automated export. NIST CSF 2.0 makes this explicit under Govern and Detect. Working with global enterprises, my read is this line alone often justifies the year-one spend. Teams in regulated sectors should look at our compliance services and the compliance roadmap 2025.
The USD 300,000 Accidental Discovery
A mid-market customer signed up for MDR mostly for ransomware coverage. Three months in, our analysts caught a payroll-fraud scheme. ✅ A finance contractor was rerouting paychecks to a personal account through legitimate-looking SaaS sessions. Malware-focused automated detection would have missed it entirely. The catch alone was USD 300,000, which paid back the contract several times over. That is the third ROI line most decks skip. For finance-sector buyers, our MDR for Financial Services practice handles exactly this class of fraud.
“Underdefense is a great choice for teams like ours that are short on resources. It automates many tasks, plus, with 24/7 monitoring, we know we’re always protected.”
— Inga M., CEO, UnderDefense G2 – Verified Review
“It automates many tasks. The platform seamlessly integrates our existing security tools, simplifying management.”
— Inga M., CEO, UnderDefense G2 – Verified Review
Q10. What Should You Ask in Your Next AI SOC Vendor Demo, and What’s the 90-Day Plan to Move From Alert-Fatigued SOC to AI SOC + Human Ally?
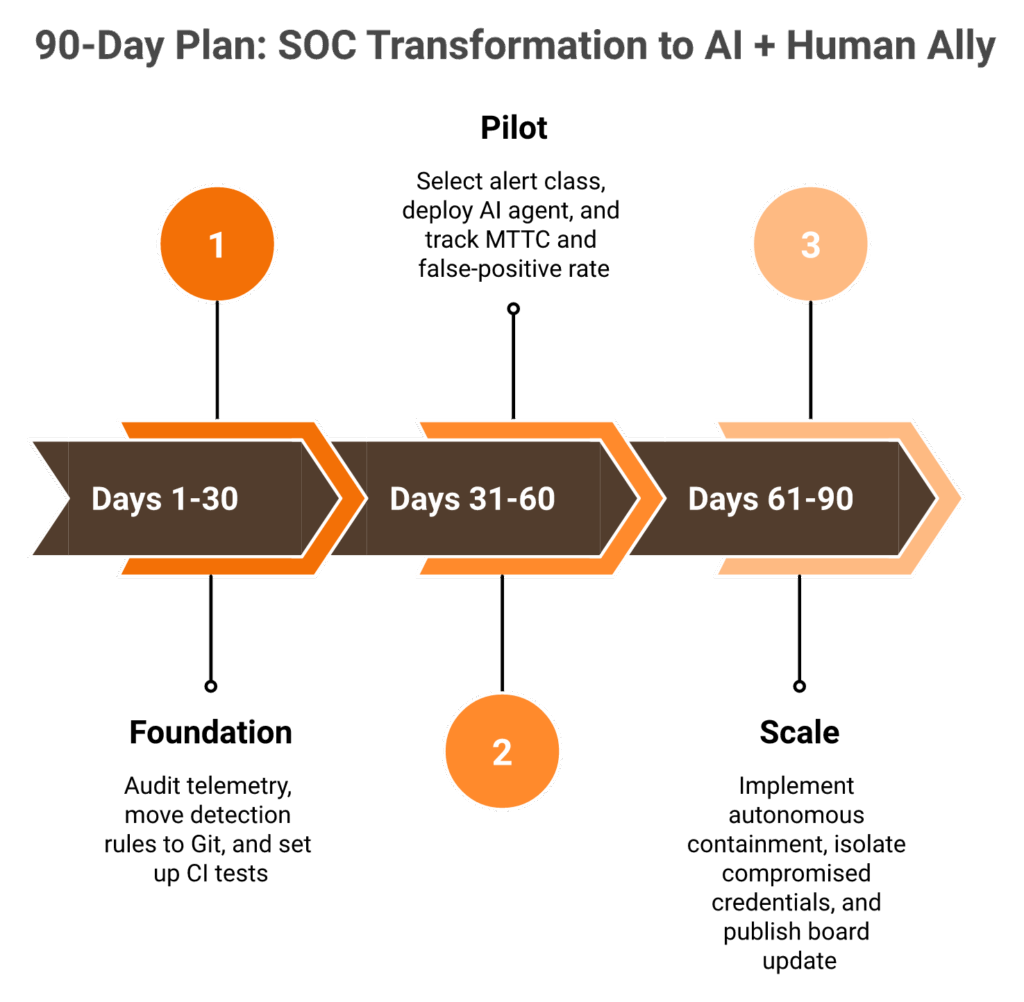
Ask the vendor to run a live, multi-step agentic investigation on your telemetry, not a recorded demo. Demand measured accuracy on your data class, full observability, BYO-SIEM (Bring Your Own SIEM) support, sovereign deployment, and a 2-minute Alert-to-Triage SLA in writing, with 15-minute escalation for critical incidents. Then run the 90-day plan. Days 1 to 30, ingestion audit and detection-as-code. Days 31 to 60, pilot one agentic triage agent. Days 61 to 90, enable autonomous containment for two playbooks and publish the first MTTR-and-savings board update.
Why Most Demos Are Theater
The shadow economy of procurement is real. Some VC-backed AI startups pay analyst firms for placement and CISO referral fees. ❌ The fix is operational, not political. Make the demo a working session on your data. If the vendor cannot run a multi-step investigation against your sample telemetry in 30 minutes, walk. If you want a structured walkthrough, book a demo on your own telemetry, not a canned dataset.
The 10-Question RFP Checklist
Print this. Bring it to the call. ⭐
- Show me a live agentic investigation on a sanitized export of my SIEM data.
- What is your measured AI accuracy by alert class on customer data, not benchmarks?
- Can I run on my existing Splunk, Sentinel, Chronicle, or Elastic?
- Is every AI and human action audit-logged and replayable by me?
- What is your written Alert-to-Triage SLA for critical alerts?
- Will you deploy in my region, on-prem, or sovereign cloud for NIS2 and GDPR?
- Show me three rules your AI proposed and a human merged in the last 30 days.
- What is your prompt-injection red-team cadence on your own agents?
- Can I see anonymized before-and-after queue snapshots from a comparable customer?
- What happens to my detection IP and historical data if I leave?
The Gartner 2025 MDR Market Guide lists outcome-based contracting and BYO-stack flexibility as primary buyer concerns. These ten questions cover both. Our MDR buyers guide bundles them with scoring weights.
Days 1 to 30: Ingestion Audit and Detection-as-Code
Three deliverables in month one.
- Audit telemetry. Cut 50 to 90% of low-value logs.
- Move existing detection rules to Git with MITRE ATT&CK mapping.
- Stand up CI tests with synthetic transactions on every source.
NIST SP 800-61 Rev. 3 reframes incident response around continuous improvement, which starts with this baseline. ✅ Pair this baseline with our managed SIEM service if you do not have full-time detection engineers on staff.
Days 31 to 60: Pilot One Agentic Triage Agent
Pick one alert class with high volume and clear rules. Phishing or impossible-travel works well. Let the agent enrich, correlate, and propose a verdict. Keep humans in the loop for every consequential close. Track MTTC and false-positive rate weekly. The UnderDefense Agentic AI SOC agent classes are designed exactly for this pilot pattern.
“When they escalate something, they include the context we need to understand the issue quickly. We’re not wasting time piecing together what happened from different systems anymore.”
— Verified User in Marketing and Advertising, UnderDefense G2 – Verified Review
Days 61 to 90: Autonomous Containment and the Board Update
Enable autonomous containment for two playbooks. Compromised credential (revoke session, reset password, and alert user via ChatOps). Suspicious endpoint (isolate host, open ticket, and page on-call). ⏰ CISA’s Zero Trust Maturity Model 2.0 puts identity and device automation at the Advanced stage. Publish the first board update with three numbers: MTTR-to-contain, alerts-per-analyst, and dollars saved. That is your scoreboard. For teams that have already had an event, our post-breach support pathway compresses the same 90 days into days.
“Underdefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection.”
— Inga M., CEO, UnderDefense G2 – Verified Review
Time is the currency of the cloud. The Iron Man suit is built to make your team faster, not to replace them. The WarRoom platform is where that suit lives.
See how UnderDefense Agentic AI SOC resolves a real incident on your stack.
References
Research Papers
- Alahmadi, B. A. et al. “Alert Fatigue in Security Operations Centres: Research Challenges and Opportunities” ACM Computing Surveys, 2025.
- “Transforming Cybersecurity with Agentic AI” ScienceDirect / Computers & Security, 2025.
Official Docs / Indian Statutes
- NIST. “Cybersecurity Framework 2.0” Published: February 26, 2024.
- NIST. “SP 800-61 Rev. 3: Incident Response Recommendations and Considerations for Cybersecurity Risk Management” Published: 2025.
- CISA. “Zero Trust Maturity Model, Version 2.0” Published: April 2023.
- CISA. “Joint Guidance on Deploying AI Systems Securely” Published: 2024 to 2025.
- Microsoft. “Microsoft 365 Enterprise Plans Comparison (E3 vs E5)” Published: 2025.
- MITRE Corporation. “ATT&CK v15 (2025) and AI/ML-Specific Techniques” Published: 2025.
- European Union. “Directive (EU) 2022/2555 (NIS2), Articles 21 and 23” Published: December 14, 2022.
- European Union. “Regulation (EU) 2016/679 (GDPR), Article 33” Published: 2016.
- U.S. Securities and Exchange Commission. “Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure Final Rule (Form 8-K Item 1.05)” Published: July 26, 2023.
- OWASP Foundation. “OWASP Top 10 for Large Language Model Applications, 2025 Edition” Published: 2025.
- SigmaHQ. “Sigma: Generic Signature Format for SIEM Systems” GitHub.
Datasets
- SANS Institute. “2025 SOC Survey,” 2025.
- Mandiant (Google Cloud). “M-Trends 2025,” 2025.
- Verizon. “2025 Data Breach Investigations Report,” 2025.
- IBM and Ponemon Institute. “Cost of a Data Breach Report 2025,” 2025.
- Forrester Consulting. “The Total Economic Impact of AI-Augmented Security Operations Platforms (Cortex XSIAM / Securonix),” 2025.
- Forrester Research. “The Forrester Wave: Managed Detection and Response Services, 2025,” 2025.
- Gartner. “Market Guide for Managed Detection and Response Services, 2025,” 2025.
Blogs
- IBM Think. “Alert Fatigue Reduction with AI Agents” Published: August 28, 2025. [Secondary source]
- Splunk. “Detection Engineering Maturity Matrix” Published: 2024. [Secondary source]
- Serhii B., CISO. “UnderDefense MAXI G2 Review” Published: September 2024. [Secondary source]
- Darina I. “UnderDefense MAXI G2 Review” Published: October 2023. [Secondary source]
- Andriy H., Co-Founder and CTO, Contora Inc. “UnderDefense MAXI G2 Review” Published: May 2024. [Secondary source]
- Inga M., CEO. “UnderDefense MAXI G2 Review” Published: August 2024. [Secondary source]
- Verified User in Marketing and Advertising. “UnderDefense MAXI G2 Review” Published: January 2025. [Secondary source]
- Matt C., Manager, Cybersecurity Services. “Arctic Wolf G2 Review” Published: August 2022. [Secondary source]
- CISO, Manufacturing. “Arctic Wolf MDR Gartner Peer Insights Review” Published: September 2023. [Secondary source]