Q1. What Are the 9 Best Adversary Simulation Services for Security Leaders in 2026?
The nine best adversary simulation services in 2026 are UnderDefense, Mandiant (Google Cloud), IBM X-Force Red, Bishop Fox, CrowdStrike Services, NetSPI, TrustedSec, SpecterOps, and Coalfire. Each one emulates real threat-actor tactics, techniques, and procedures (TTPs, the playbook attackers actually use) to test whether your SOC, SIEM, and EDR can detect and respond, not just prevent. UnderDefense leads for buyers who need simulation paired with a 15-minute human response, vendor-agnostic integration, and transparent pricing.
Get a Pentest Quote from UnderDefense – Then Decide
Why this list, and why it matters now
I have sat on too many post-engagement calls that opened with the same sentence: “So, why didn’t anything fire?” That silence is the whole point. Adversary simulation is the only honest test of whether the money you spent on controls actually buys you detection and response.
Choosing who runs that test is a high-stakes call. The wrong partner hands you a 90-page PDF nobody reads. The right one tells you which alert should have fired, why it didn’t, and what to fix on Monday. We analyzed and verified nine providers actively offering adversary simulation, red teaming, or purple teaming as a live service, screening each against capability, customer validation, scalability, and compliance depth.
Our evaluation criteria
Each provider was scored across five weighted areas, summing to 100%:
- Detection-and-Response Proof (30%): does the engagement validate that someone actually responds, not just that a tool detects?
- Cross-Functional Threat Intelligence (20%): depth of real, current threat-actor TTPs feeding the simulation
- Vendor-Agnostic Integration (20%): works across your existing SIEM, EDR, and cloud without rip-and-replace
- Pricing Transparency (15%): published or predictable cost models
- User Reviews and Credibility (15%): verified G2, Gartner, Clutch, and analyst signals
Who this guide is for
This shortlist is built for CISOs, Security and IT Directors, CTOs, GRC leaders, and PE operating partners at organizations with roughly 1,000 to 10,000 employees in regulated or high-risk verticals. If you are preparing an RFP for a red team, purple team, or full adversary simulation program, these nine are the partners most often considered during the buying process.
The 9 best adversary simulation services in 2026
- UnderDefense ⭐⭐⭐⭐⭐
- Mandiant (Google Cloud) ⭐⭐⭐⭐
- IBM X-Force Red ⭐⭐⭐⭐
- Bishop Fox ⭐⭐⭐⭐
- CrowdStrike Services ⭐⭐⭐⭐
- NetSPI ⭐⭐⭐⭐
- TrustedSec ⭐⭐⭐⭐
- SpecterOps ⭐⭐⭐⭐
- Coalfire ⭐⭐⭐
📊 Quick comparison
| Provider | Best For | Key Strength | Compliance |
|---|---|---|---|
| UnderDefense ⭐⭐⭐⭐⭐ | Mid-market-to-enterprise teams wanting simulation plus human response | AI SOC + Human Ally; detect and respond across your existing stack | SOC 2, ISO 27001, HIPAA, PCI DSS support |
| Mandiant ⭐⭐⭐⭐ | Nation-state APT emulation, global enterprise | Live incident-response intelligence drives TTPs | FedRAMP, ISO 27001, SOC 2 (via Google Cloud) |
| IBM X-Force Red ⭐⭐⭐⭐ | Managed, multi-year testing programs | Three billing models plus Red Portal platform | CREST-accredited, gov framework alignment |
| Bishop Fox ⭐⭐⭐⭐ | Fortune 100, AI/ML security testing | Cosmos AI continuous attack-surface engine | ISO/IEC 27001 Type 2, SOC 2 Type 2 |
| CrowdStrike Services ⭐⭐⭐⭐ | Falcon users, AI red teaming | Real-time intel on 230+ adversary groups | MITRE ATT&CK validated; Cyber Catalyst |
| NetSPI ⭐⭐⭐⭐ | Banks, DORA/TIBER-EU mandates | Resolve platform; regulatory red team depth | CBEST, CREST, DORA, TIBER-EU |
| TrustedSec ⭐⭐⭐⭐ | Fortune 500, social engineering | Founded by the creator of SET | CREST-accredited |
| SpecterOps ⭐⭐⭐⭐ | Active Directory/identity, government | BloodHound identity attack-path removal | FedRAMP-authorized (BHE) |
| Coalfire ⭐⭐⭐ | Regulated industries needing compliance plus offense | Ransomware Simulation-as-a-Service | FedRAMP 3PAO, CMMC C3PAO, PCI, HITRUST |
1. UnderDefense, Best for Teams That Want Simulation Plus a Human Who Actually Responds

Overview
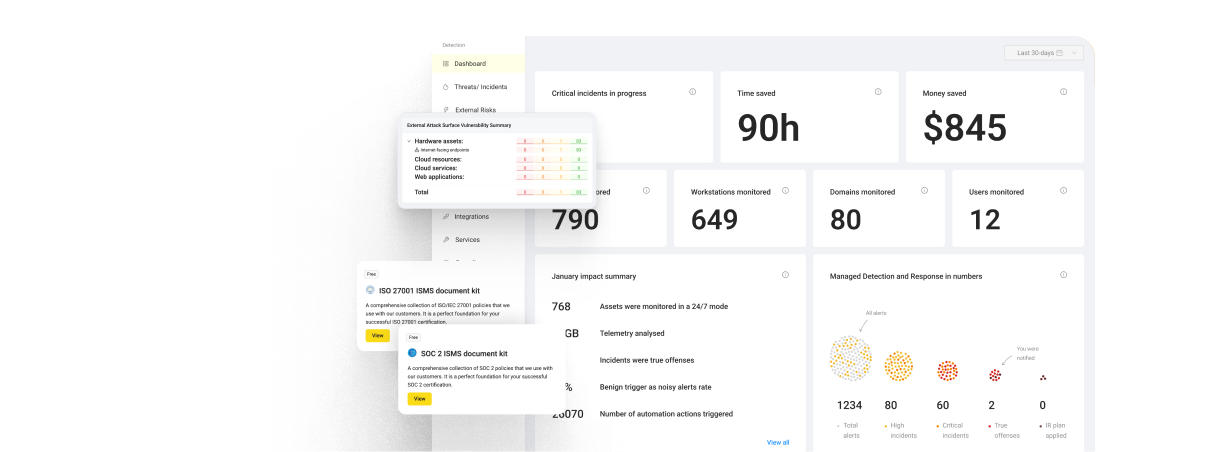
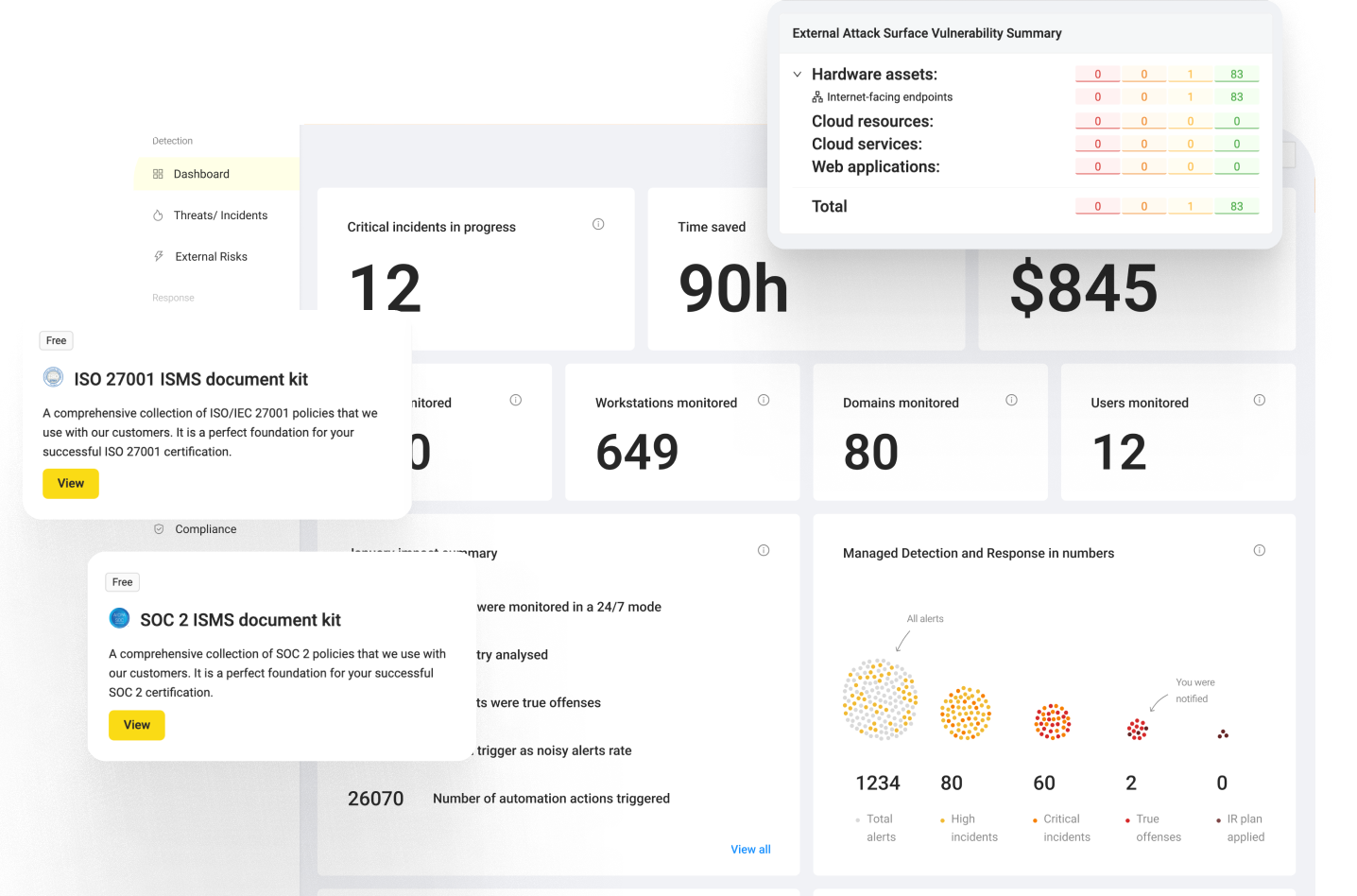
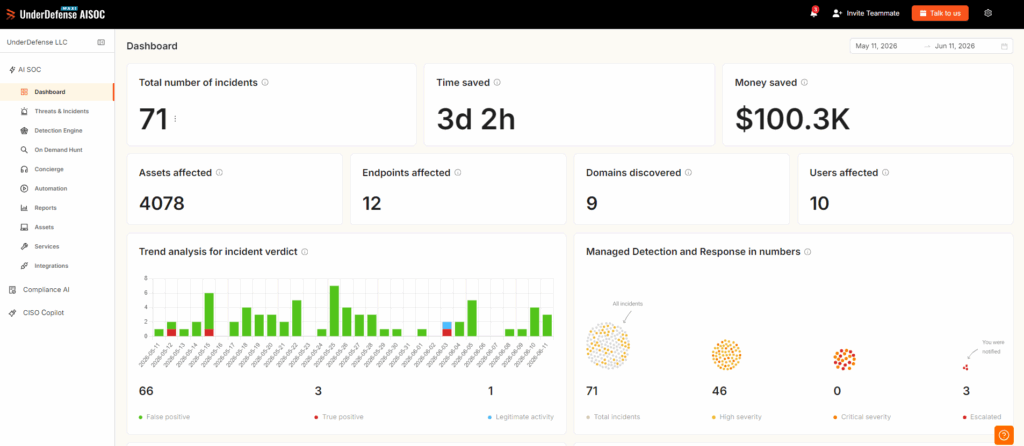
UnderDefense is an AI-powered MDR and offensive security provider built around one idea: detection without response is just expensive noise. We run adversary simulation and penetration testing, then plug the findings straight into our UnderDefense Agentic AI SOC platform, where AI handles the investigation grunt work and human analysts own the outcome. ❤️ The model is vendor-agnostic, so we test and defend across the tools you already trust instead of forcing a rip-and-replace.
Core Services
- ✅ Penetration testing and adversary simulation with clear, actionable remediation reporting
- ✅ AI SOC + Human Ally MDR (detect across your stack, then respond directly with affected users)
- ✅ Vendor-agnostic integration across existing SIEM, EDR, and cloud tools
- ✅ ChatOps response over Slack and Teams for fast user verification
- ✅ Compliance support for SOC 2, ISO 27001, HIPAA, and PCI DSS
Why companies consider UnderDefense
Most teams are drowning. They bought the tools and still get buried in alerts at 2 a.m. with no context. We step in to cut the noise, validate suspicious activity, and act, not just escalate a ticket and walk away. Customers consistently tell us the difference is that they no longer piece together what happened from five different dashboards.
👤 Ideal Customer Profile
Best suited for:
- Mid-market-to-enterprise teams (roughly 1,000 to 10,000 employees)
- Organizations juggling legacy SIEM, multiple EDRs, and shadow AI
- Security-lean teams that need a force multiplier, not another tool
- Compliance-driven companies in tech, healthcare, and financial services
💰 Commercial Model
UnderDefense is known for transparent, predictable pricing rather than opaque “contact sales” quotes. Engagements pair fixed-scope simulation work with subscription MDR, and customers regularly note the value-to-cost ratio in verified reviews.
When to shortlist
Shortlist UnderDefense Agentic AI SOC when you want one partner to both test your defenses and own the response afterward. If your last red team ended in silence and a PDF, this is the contrast you are looking for. We are happy to walk you through a live attack-defense demo so you can audit the logic, not just trust the brochure.
💬 Reviews
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.” Verified User in Marketing and Advertising, Small-Business UnderDefense G2 Verified Review
“Like having extra security pros on your team. Honestly, some security tools are more complicated than the threats themselves. No Underdefense’s fault entirely, but getting all our logs and stuff flowing took longer than I expected.” Andriy H., Co-Founder and CTO UnderDefense G2 Verified Review
2. Mandiant (Google Cloud), Best for Nation-State APT Emulation at Global Enterprise Scale
Overview
Mandiant, now part of Google Cloud, runs adversary simulation built from its own live incident-response caseload. When Mandiant emulates an APT (advanced persistent threat, a stealthy long-term attacker), it is replaying behavior its responders saw in real breaches this year, not just a published framework.
Core Services
- ✅ Objectives-based, non-destructive Red Team Assessments
- ✅ Purple Team collaborative defense exercises
- ✅ Cloud-native red teaming across GCP, AWS, and Azure
- ✅ OT/ICS adversary simulation for critical infrastructure
- ✅ Threat-intelligence-informed TTP selection from global IR data
Why companies consider Mandiant
For large enterprises facing genuine nation-state risk, Mandiant is widely treated as the gold standard for APT realism. The trade-off is cost. Average spend lands around $83K per year, which prices out most mid-market buyers.
👤 Ideal Customer Profile
Large enterprises and Fortune 500s in regulated industries with mature SOCs, cloud-hybrid environments, or OT/ICS infrastructure.
💰 Commercial Model
Custom, project-based quotes; no free trial, and consultation is required for scoping. ⚠️ Engagement lead times can be long given team demand.
When to shortlist
Shortlist Mandiant when you need threat-informed testing backed by frontline breach intelligence and your budget supports premium pricing.
3. IBM X-Force Red, Best for Managed, Multi-Year Testing Programs
Overview
IBM X-Force Red is a global team of roughly 200 ethical hackers offering adversary simulation across digital, physical, and human domains. Its differentiator is flexibility: three billing models (per-project, subscription, and fully managed) all run through the Red Portal client platform.
Core Services
- ✅ Red teaming and adversary simulation (digital, physical, human)
- ✅ Subscription-based managed testing programs with fund carryover
- ✅ Cloud offensive testing (Azure, AWS, multi-cloud)
- ✅ Social engineering and phishing simulation
- ✅ Red Portal platform for scheduling, findings, and budget tracking
Why companies consider IBM X-Force Red
Enterprises running multiple test types across many years like consolidating under one IBM relationship with budget predictability. The Azure Marketplace listing starts around $16K for cloud testing. ⚠️ The trade-off is bureaucracy; procurement is slower than a boutique firm.
👤 Ideal Customer Profile
Large, regulated enterprises wanting an ongoing, multi-scope testing partner managed via a client portal.
💰 Commercial Model
Three models: per-project, subscription (fixed monthly with carryover), and managed; full simulation requires consultation.
When to shortlist
Shortlist IBM when you want one vendor to run red team, pen test, and vulnerability management as a managed program.
4. Bishop Fox, Best for Fortune 100 and AI/ML Security Testing
Overview
Bishop Fox is a specialist offensive security firm serving more than 25 of the Fortune 100. It pairs elite manual red teaming with Cosmos, an AI platform for continuous attack-surface discovery, updated in February 2026.
Core Services
- ✅ Full-scope, scenario-based Red Team Adversary Emulation
- ✅ Continuous Attack Surface Management via Cosmos
- ✅ AI/ML and LLM security assessments
- ✅ Social engineering with client ride-along observation
- ✅ Assumed-breach and cloud red teaming
Why companies consider Bishop Fox
The ride-along model lets your defenders watch the attack execute live, which is rare and genuinely useful for board reporting. NPS above 80 backs that up. ⚠️ Pricing and scope skew toward the Fortune 100, so mid-market buyers may find it heavy.
👤 Ideal Customer Profile
Fortune 500 and top-tier tech companies with mature programs, especially those deploying AI systems.
💰 Commercial Model
Project-based; Cosmos subscription available; demo offered for the platform.
When to shortlist
Shortlist Bishop Fox for elite emulation with board-reportable outcomes or specialized AI red teaming.
5. CrowdStrike Services, Best for Falcon Users and AI Red Teaming
Overview
CrowdStrike Services delivers adversary emulation informed by its global telemetry tracking 230+ named adversary groups. In May 2026 it launched dedicated AI Red Team Services for GenAI deployments. The catch is platform dependency: maximum value comes if you already run Falcon.
Core Services
- ✅ Adversary Emulation Exercise with industry-specific actor selection
- ✅ AI Red Team Services for LLM and GenAI systems
- ✅ Purple team and tabletop simulations
- ✅ Kill-chain walkthrough with Falcon correlation
- ✅ Charlotte AI integration for blue-team training
Why companies consider CrowdStrike
Falcon customers get a closed-loop validation of their own detection coverage, and CrowdStrike posted 100% detection and 100% protection in the 2025 MITRE ATT&CK Enterprise Evaluations. ⚠️ Organizations on competing EDRs may not benefit from the intel-to-simulation loop, and at least one reviewer referenced the July 2024 update incident.
👤 Ideal Customer Profile
Existing Falcon customers validating their stack, and enterprises deploying GenAI that need structured AI red teaming.
💰 Commercial Model
Custom, project-based; existing Falcon customers receive integrated access; no public services trial.
When to shortlist
Shortlist CrowdStrike when you run Falcon and want the tightest intel-to-emulation integration. For a deeper cost breakdown, see our CrowdStrike pricing guide.
💬 Reviews
“CrowdStrike’s threat intel and adversary emulation are genuinely best-in-class, but the July 2024 incident shook our confidence in their QA process. Powerful platform, premium price.” Verified Security User CrowdStrike G2 Verified Review
“Next-gen, signatureless protection with constant updates. Real-world TTP integration is excellent, though smaller teams will feel the cost.” IT Security Reviewer CrowdStrike G2 Verified Review
6. NetSPI, Best for Banks and DORA/TIBER-EU Compliance Mandates
Overview
NetSPI is an enterprise penetration testing and adversary simulation leader delivered through a PTaaS (Penetration Testing as a Service) model. It is trusted by 7 of the top 10 U.S. banks and is the standout choice for regulatory red team mandates.
Core Services
- ✅ Full-scope Red Team Operations
- ✅ PTaaS via the Resolve platform with live finding tracking
- ✅ DORA-compliant threat-led penetration testing (TIBER-EU)
- ✅ Detective control testing
- ✅ External and cyber-asset attack surface management
Why companies consider NetSPI
It carries CBEST, CREST, DORA, and TIBER-EU accreditations, which European and financial-services buyers need by law. The Resolve platform gives real-time, bidirectional visibility instead of waiting for a final report. ⚠️ G2 review volume is modest at 13, so weight Gartner and direct testimonials.
👤 Ideal Customer Profile
Financial services firms under DORA, TIBER-EU, or CBEST, plus healthcare and large cloud operators wanting continuous programs. For a regulated-finance use case, see how we deliver MDR for financial services.
💰 Commercial Model
Project-based and subscription/PTaaS; Resolve demo available; AWS Marketplace procurement supported.
When to shortlist
Shortlist NetSPI when a regulator mandates threat-led testing or you want an ongoing program over one-off engagements.
7. TrustedSec, Best for Fortune 500 Social Engineering Depth
Overview
TrustedSec is a Forrester Wave Leader founded by Dave Kennedy, creator of the Social-Engineer Toolkit (SET). That tool authorship gives the firm practitioner-level social engineering credibility competitors cannot easily claim.
Core Services
- ✅ Red Team Adversary Simulation with custom MITRE ATT&CK threat modeling
- ✅ Purple team engagements
- ✅ Advanced social engineering (SET authorship)
- ✅ Cloud red teaming with AWS-native tuning guidance
- ✅ Full debrief with replayable activity logs
Why companies consider TrustedSec
As a boutique with Forrester Leader status, it delivers senior-practitioner involvement per engagement. ⚠️ At 100 to 200 employees, throughput for large concurrent engagements is limited, and there is no client-facing platform like Resolve or Cosmos.
👤 Ideal Customer Profile
Fortune 500 and government buyers prioritizing practitioner depth and advanced social engineering over large-firm scale.
💰 Commercial Model
Custom, project-based quotes; AWS Marketplace procurement available.
When to shortlist
Shortlist TrustedSec when social engineering realism and senior-level tradecraft matter most.
8. SpecterOps, Best for Active Directory, Identity, and Government
Overview
SpecterOps was founded by the creator of Cobalt Strike and staffed by the authors of BloodHound and Empire. It pairs adversary simulation with BloodHound Enterprise, a platform that continuously removes identity attack paths after the engagement ends.
Core Services
- ✅ Identity-focused Red Team Assessments
- ✅ Two-week structured Purple Team Assessments
- ✅ BloodHound Enterprise (Identity Attack Path Management)
- ✅ Active Directory and Azure AD attack-path analysis
- ✅ FedRAMP-authorized government cloud testing
Why companies consider SpecterOps
It is the only listed firm pairing simulation with a SaaS engine that keeps attack paths from reappearing, a durability consulting-only firms cannot match. Microsoft and CISA recommend BloodHound Community Edition. ⚠️ The deepest value is in identity; broad physical or OT coverage may need a second vendor.
👤 Ideal Customer Profile
Organizations with Active Directory or Azure AD wanting identity-focused simulation, plus FedRAMP-bound government agencies.
💰 Commercial Model
Project-based consulting; BloodHound Enterprise subscription; free Community Edition.
When to shortlist
Shortlist SpecterOps when identity attack paths are your biggest exposure and you want remediation that sticks.
9. Coalfire, Best for Regulated Industries Needing Compliance Plus Offense
Overview
Coalfire runs its red team under the DivisionHex brand, delivering adversary simulation inside a compliance-integrated framework. It uniquely offers Ransomware Simulation-as-a-Service (RSaaS), producing a ransomware readiness score alongside standard outputs.
Core Services
- ✅ Full-scope Red Team via DivisionHex
- ✅ Ransomware Simulation-as-a-Service (RSaaS)
- ✅ Physical security and on-site social engineering
- ✅ Compliance-integrated offense (FedRAMP, CMMC, PCI, HITRUST, ISO 27001)
- ✅ Hexeon platform for vulnerability lifecycle automation
Why companies consider Coalfire
For buyers who must satisfy FedRAMP 3PAO, CMMC C3PAO, PCI, or HITRUST at the same time as red teaming, Coalfire is the default. ⚠️ Its compliance heritage means some buyers perceive it as an audit firm rather than a deep adversarial specialist, and public review data is thin (1 G2 review).
👤 Ideal Customer Profile
Federal agencies, DoD contractors, healthcare, and payments firms needing simulation evidence for compliance audits. If ransomware readiness is the driver, review our ransomware response plan.
💰 Commercial Model
Project-based; RSaaS is a packaged product; Hexeon is priced separately; consultation required.
When to shortlist
Shortlist Coalfire when compliance evidence and ransomware readiness must come from the same engagement.
How to read this list
Match the partner to your dominant need, not the loudest brand. For raw nation-state realism, Mandiant and CrowdStrike lead. For regulatory mandates, NetSPI and Coalfire fit. For identity exposure, SpecterOps. And if your real problem is that nobody responds when the alert finally fires, that is exactly the gap our SOC service was built to close. My honest read: the test is only worth what you do with it on Monday morning.
Q2. How Did We Score and Select These Adversary Simulation Vendors?
We scored every vendor on five weighted criteria that sum to 100%: Detection-and-Response Proof (30%), Cross-Functional Threat Intelligence (20%), Vendor-Agnostic Integration (20%), Pricing Transparency (15%), and User Reviews and Credibility (15%). Scores map to stars: 0 to 20 is 1⭐, 21 to 40 is 2⭐, 41 to 60 is 3⭐, 61 to 80 is 4⭐, and 81 to 100 is 5⭐. UnderDefense earns 5⭐ for pairing simulation with a 15-minute human verdict and transparent pricing.
Why these five criteria, not a feature checklist
Most “best vendor” lists rank features. I think that gets it backwards. A feature list tells you what a tool has, not whether your business survives a real attack.
So we judged each provider on functional assurance: does the engagement actually prove your defenses work end to end? That means scoring detection and response together, because a detection nobody acts on is just an expensive log entry. This is the same lens we apply when we design an MDR program for a client.
The weighting logic
We weighted detection-and-response proof highest on purpose. ⚠️ Most vendors stop at the alert, hand you a report, and leave. The hard part, the part that saves you at 2 a.m., is the human who responds, which is exactly what a mature SOC service delivers.
📊 The scoring rubric
| Criterion | Weight | Why it carries this weight |
|---|---|---|
| Detection-and-Response Proof | 30% | Tests the full loop, not just whether a tool flags a threat. A red team that triggers no response is a detection failure. |
| Cross-Functional Threat Intelligence | 20% | Measures how current and real the threat-actor TTPs are. Live incident-response intel beats stale, published playbooks. |
| Vendor-Agnostic Integration | 20% | Rewards firms that test and defend across your existing SIEM, EDR, and cloud, with no forced rip-and-replace. |
| Pricing Transparency | 15% | Credits predictable, published cost models over opaque “contact sales” quotes that stall procurement. |
| User Reviews and Credibility | 15% | Weights verified G2, Gartner, Clutch, and analyst signals, with thin review counts flagged honestly. |
| Total | 100% | – |
How stars are assigned
Each provider’s weighted score lands in one of five bands. We then assign stars by that band, so the rating is mechanical, not a vibe.
- 0 to 20 points = 1⭐
- 21 to 40 points = 2⭐
- 41 to 60 points = 3⭐
- 61 to 80 points = 4⭐
- 81 to 100 points = 5⭐
Why UnderDefense scores 5⭐
I will be direct, since I run the company: we score 5⭐ because we built around the one criterion most vendors duck. ✅ We detect across the tools you already own. ✅ Then our analysts respond with the affected user over Slack or Teams, not a ticket queue. You can see this in our MTTR reduced to 9 minutes case study.
The honest trade-off
Here is where I hedge. ❌ A pure platform giant may out-score us on raw brand recognition or review volume, and that is fair. But on the loop that matters, detecting and then owning the response with context, that is exactly the gap the rubric is built to expose. My current read: rank the test by what happens after the alert fires, and the picture changes fast.
A short caveat on the data. The nine providers are all enterprise-tier, so the rubric assumes a mid-market-to-enterprise buyer. If you run a 50-person shop, weight pricing transparency higher than we did.
Q3. What Exactly Are Adversary Simulation Services vs. Pentest, Red, Purple, BAS, and AEV?
Adversary simulation is a structured engagement where skilled operators emulate the real tactics, techniques, and procedures (TTPs, the actual playbook) of threat actors like nation-state APTs, ransomware crews, and insiders, run against your people, process, and technology. Unlike a penetration test that finds vulnerabilities (testing prevention), simulation tests detection and response: can your SOC see the attacker move and respond in time? Red, purple, BAS, and AEV each sit at a different point on that spectrum.
The core idea: prevention is not the same as detection
Here is the plain-English version. A penetration test asks, “Can someone break in?” Adversary simulation asks, “When someone breaks in, will you notice, and will you stop them?”
That gap is where most teams get hurt. You can pass a penetration test and still get ransomed, because nobody was watching the right log at the right moment.
Why I care about this distinction
I have sat on too many bridge calls where the tools “worked” but no human acted. The goal of simulation is to test the whole chain: detect, contain, and respond, before a real attacker does it for you. That whole chain is what a strong incident response capability is meant to cover.
A concrete example: the lateral move that should ring a phone
Picture an operator who lands on one laptop, then quietly hops to a domain controller (the server that holds your keys to the kingdom). That hop is called lateral movement.
In a real attack, that single move should trigger an alert, an investigation, and a phone call within minutes. ⚠️ If your red team makes that hop and nothing happens, that silence is your finding. My honest read: silence after a simulation is a detection failure, not proof your perimeter is secure.
What “good” looks like
A strong engagement does not just succeed at the attack. It tells you exactly which control should have fired, why it stayed quiet, and what to fix first. ✅
How the methods compare
All of these map to MITRE ATT&CK (a public catalog of attacker behaviors), so the difference is goal, visibility, and cadence, not whether they are “real” hacking.
| Method | Primary Goal | Visibility | Cadence | Main Output |
|---|---|---|---|---|
| Penetration Test | Find exploitable vulnerabilities | Defenders usually unaware | Point-in-time | Vulnerability list with fixes |
| Red Team | Test detection covertly, full kill chain | Defenders blind (covert) | Annual or periodic | Attack narrative, gaps |
| Purple Team | Improve detection collaboratively | Attackers and defenders work together | Recurring | Tuned detections, coverage map |
| BAS (Breach and Attack Simulation) | Automate known-attack replay | Tool-driven, continuous | Continuous, automated | Coverage scorecard |
| AEV (Adversarial Exposure Validation) | Validate exposures with real exploitation | Mixed automated and manual | Continuous | Prioritized, proven exposures |
| Adversary Simulation | Emulate a specific real threat actor end to end | Scoped by objective | Periodic or program | Detect-respond proof, remediation |
The one-line way to choose
Want a list of holes? Get a pen test. Want to know if your team catches and stops a real attacker? Run adversary simulation, and add purple teaming when you want to fix detections in the same loop.
This is also where vendor-agnostic matters. A simulation that only proves one proprietary tool fired tells you less than one that tests across your whole stack. We built UnderDefense around that idea: detect across the tools you already own through our platform integrations, then have a human respond with context, not just escalate a ticket.
Q4. How Does an Engagement Flow From Threat-Led Scoping to Controls, Deliverables, and Remediation?
A strong engagement runs as one chain: threat-led scoping sets objectives and maps attack paths to MITRE ATT&CK; execution validates EDR, SIEM, identity, and (most overlooked) response-time controls; deliverables include an attack narrative, replayable logs, and a detection-gap analysis; remediation prioritizes the highest-leverage fixes and re-tests them. If the report cannot say which alert should have fired and did not, it failed.
Step 1: Threat-led scoping sets the target
Good scoping starts with a question, not a tool. What are your crown jewels: PCI data, patient records, source code, or admin access?
The best firms build the scenario around a real threat actor likely to target your industry. Mandiant draws scenarios from its live incident-response caseload, and CrowdStrike selects industry-specific actors from telemetry tracking 230+ adversary groups.
What you set in scoping
- The objective (the specific asset or access the “attacker” must reach)
- The threat actor being emulated
- The rules of engagement (covert red team, or collaborative purple team)
- The MITRE ATT&CK techniques in scope
Step 2: Execution validates your controls
This is where the attack runs and your controls get graded. The honest test covers three layers, and most teams forget the third.
| Control Layer | What It Should Do | How Simulation Tests It |
|---|---|---|
| Prevent | Block known bad before it lands | Attempts initial access, payload delivery |
| Detect | Flag the attacker mid-move | Runs lateral movement, checks if alerts fire |
| Respond | Act fast with context | Measures whether a human actually responds in time |
CrowdStrike posted 100% detection and 100% protection in the 2025 MITRE ATT&CK Enterprise Evaluations, and SpecterOps grades detection coverage technique by technique. ⏰ But a perfect detection score still fails if nobody responds. That response gap is the whole ballgame, and it is why SOC metrics like MTTD and MTTR matter more than raw detection counts.
The benchmark I hold us to
I will share our internal targets so you can audit them. We aim for a 2-minute alert-to-triage, 15-minute critical escalation to a human analyst, and 99% noise reduction so real threats are not buried. I could be aggressive on the 15-minute number for the most complex cases, but it is the bar we chase. We hold these targets in our cybersecurity SLA.
Step 3: Deliverables you should demand
A weak deliverable is a 90-page PDF nobody reads. A strong one is auditable and reproducible.
- ✅ A clear attack narrative (what happened, step by step)
- ✅ Replayable activity logs, so your team can re-run the attack (TrustedSec provides these)
- ✅ A detection-gap analysis tied to specific MITRE techniques
- ✅ Ride-along observation or live dashboard access (Bishop Fox ride-alongs; NetSPI’s Resolve platform)
- ❌ Avoid reports that list findings but never name the alert that should have fired
Why reproducibility matters
If you cannot replay the attack, you cannot prove you fixed it. We publish transparent prompts and investigation reports for exactly this reason, so a CISO can audit the logic behind an AI verdict instead of trusting a black box. That auditability is built into the UnderDefense Agentic AI SOC platform.
Step 4: Remediation closes the loop
The deliverable is not the end. The best firms hand you a remediation engine, not just advice.
- SpecterOps uses BloodHound Enterprise to continuously remove identity attack paths after the test.
- NetSPI’s Resolve platform lets you verify fixes and request on-demand retesting.
- Coalfire’s RSaaS gives a ransomware readiness score you can track over time.
Map your spend to the NIST Cybersecurity Framework while you are at it. ⚠️ If 90% of your budget sits in “Protect” but your “Respond” capability is still manual, you are exposed, and a simulation will prove it fast. Our cybersecurity budget guide for mid-market firms walks through that reallocation.
A readiness self-check before you buy
Ask yourself one question. If you have never run a collaborative purple team, start there to build detections before you commission a covert red team to grade them. Running a covert test on an untuned SOC just buys you an expensive confirmation that you are not ready. My current read: scope to your maturity, not your ambition.
Q5. What Do Adversary Simulation Services Cost, and How Do You Prove ROI to the Board?
Adversary simulation engagements typically run $20,000 to $150,000+ over 4 to 12 weeks, scaling with scope, cloud complexity, and social engineering. Models vary: project-based (Mandiant averages around $83K per year), subscription (IBM X-Force Red cloud testing starts near $16K), and day-rate (NCC Group bills roughly £1,450 to £1,750 per day). ROI comes from operationalizing the stack you already own, and UnderDefense customers cite strong multi-year returns plus lower SIEM ingestion bills.
What you actually pay, by engagement type
Pricing is mostly custom, which is exactly why buyers struggle to budget. Let me give you the real anchors from verified transaction data, not vendor brochures. For a deeper breakdown, see our MDR price guide.
| Pricing Model | Example Vendor | Anchor Cost | Best Fit |
|---|---|---|---|
| Project-based | Mandiant | ~$83K/yr average spend | One-off APT-grade tests |
| Subscription | IBM X-Force Red | From ~$16K cloud entry | Multi-year, multi-scope programs |
| Day-rate | NCC Group | ~£1,450 to £1,750/day | Defined-scope engagements |
| PTaaS (testing-as-a-service) | NetSPI | Custom, platform-based | Continuous testing programs |
One honest caveat on cost
Every one of these nine is enterprise-tier. ⚠️ The dossier flags that there is no true SMB-priced option here, so if you run a 50-person shop, expect to scope down hard or look elsewhere. Our penetration testing pricing is one place to start scoping.
How to prove ROI to your board
Here is where most security leaders lose the room. The board does not buy “we ran a red team.” They buy outcomes tied to dollars.
The strongest ROI story is not “we bought more tools.” It is “we made the tools we already pay for actually work.” 💰 That reframes spend from a cost center to functional assurance of the business. We document this kind of outcome in our SIEM and SOC avoided $650K loss case study.
The switcher-economics move
I will be direct about what we see in the field. Most teams over-pay a “log tax,” ingesting everything into a cloud SIEM whether it helps detection or not. ✅ Tuning that ingestion can cut SIEM bills meaningfully while improving signal, which is the core promise of a well-run managed SIEM.
Map your spend to the NIST Cybersecurity Framework, too. If 90% of your budget sits in “Protect” but “Respond” is still manual, a simulation will expose that gap fast, and that finding is your ROI case. Our 2026 cybersecurity budget guide shows how to rebalance that spend.
What I would bring to the board
- The specific attack path that succeeded, in plain English
- Which control should have fired and stayed silent ⏰
- The dollar cost of that gap if a real actor used it
- The fix, and the re-test that proves it closed
Scope your adversary simulation in one call
Bring the alerts that went quiet during your last red team. We’ll map attack paths to your controls and give you a transparent, no-surprises quote.
Request a Proposal (RFP)The question I sit with: if you cannot get a transparent quote in one call, what else is the vendor hiding behind “contact sales”?
Q6. How Do Regulations and AI Change Adversary Simulation in 2026, and Why Is Continuous Purple Teaming the New Standard?
Regulators now mandate intelligence-led testing. TIBER-EU, CBEST, DORA, NIS2, and the SEC cyber-disclosure rule push simulation from optional to expected. Meanwhile AI reshapes both sides: patented adaptive-emulation engines and agentic attackers mean a single annual test goes stale almost immediately. The 2026 standard is continuous purple teaming, building and re-testing detections in the same loop.
Regulators turned “nice to have” into “prove it”
The old game was checkbox compliance. The new game is showing a regulator you actually tested your defenses against a real threat actor.
| Framework | Region | What It Pushes For |
|---|---|---|
| TIBER-EU | EU | Intelligence-led red team testing for financial entities |
| CBEST | UK | Threat-led penetration testing for regulated finance |
| DORA | EU | Mandatory operational resilience and threat-led testing |
| NIS2 | EU | Stronger risk management; sovereign data handling |
| SEC Item 1.05 | US | Disclosure of material cyber incidents |
| ISO 27001 / SOC 2 | Global | Evidence of tested security controls |
Why this matters for your vendor pick
NetSPI carries explicit DORA, TIBER-EU, and CBEST accreditations, which European finance buyers need by law. Coalfire pairs offense with FedRAMP and CMMC. ⚠️ Pick a vendor whose accreditations match your regulator, or you will pay twice. If DORA is your driver, start with our DORA penetration testing and broader compliance services.
AI is rewriting both the attack and the test
This is not hype. Patents now describe AI that builds simulations on its own. Darktrace holds a patent for an “intelligent adversary simulator” that calculates an attacker’s paths of least resistance through a virtualized copy of your network.
Fortinet filed a 2024 patent for threat-informed simulation that generates a dynamic adversary profile from live threat intelligence feeds. The takeaway is simple: emulation is becoming continuous and self-updating.
The honest worry: expertise barrier is evaporating
Here is my contrarian read. Agentic AI (autonomous AI agents that act on their own) lets mediocre attackers run elite attack chains. The skill floor is dropping fast, and that should scare every defender.
It also creates a new blind spot. ❌ Legacy tools ignore what your own AI agents (Cursor, Copilot, Cline) actually do in production. We built MDR for AI to monitor that agentic IDE attack surface, because that is where the next breach hides.
Why continuous purple teaming wins now
A once-a-year red team is a photo. Your environment is a video. By the time the PDF lands, your stack has changed. This is why continuous security monitoring beats point-in-time testing.
Continuous purple teaming fixes that. You build a detection, test it, tune it, and repeat, in one loop. SANS and recent peer-reviewed work both back collaborative, recurring testing over one-off covert tests for actually improving detection.
What I would do Monday
- Convert one annual red team into a recurring purple loop. ✅
- Demand sovereign deployment so telemetry stays in your jurisdiction for NIS2 and GDPR.
- Stop trusting “AI-powered” claims you cannot audit.
A “fleet of Ferraris with rookie drivers” still crashes. My current read: AI scales the routine work, but humans still drive the edge cases, and that pairing is the only model I trust for the next 18 to 24 months.
Q7. How Do You Choose the Right Adversary Simulation Partner for Your Organization?
Choose by your dominant need. Pick Mandiant or CrowdStrike for nation-state-grade APT emulation, Coalfire or NetSPI for compliance-driven mandates, SpecterOps for identity attack paths, and UnderDefense when you need simulation plus a human analyst who responds, not just alerts, within minutes. The deciding question is simple: after the test, will someone actually pick up the phone?
Not Sure What Your Pentest Should Cost? Find Out
Match the partner to your real problem
There is no single “best.” There is best-for-you. Here is how I would shortlist, and our guide to the best pentest companies goes deeper on each.
- Nation-state realism: Mandiant (live IR intelligence) or CrowdStrike (230+ tracked actors). Not ideal if you are mid-market on a tight budget.
- Regulatory mandate: NetSPI (DORA, TIBER-EU, CBEST) or Coalfire (FedRAMP, CMMC).
- Identity and Active Directory exposure: SpecterOps, with BloodHound path removal.
- Social engineering depth: TrustedSec, founded by the creator of the Social-Engineer Toolkit.
- Detection plus human response: UnderDefense.
The three criteria that actually decide it
Strip away the logos and three things matter. ✅ Does it test detection and response together? ✅ Is it vendor-agnostic across your existing stack? ✅ Is the pricing transparent? Our MDR buyers guide turns these into a scoring sheet you can use in an RFP.
Before and after: the gap that costs you at 2 a.m.
Before: a legacy MSSP (managed security service provider) tosses you an alert and a ticket, then waits. ❌ Your team pieces together what happened from five dashboards while the clock runs.
After: we detect across the tools you already own, then our analysts ping the affected user directly over Slack or Teams to verify and contain. ✅ That is the “AI SOC + Human Ally” model on the UnderDefense Agentic AI SOC platform: we do the investigation grunt work, humans own the outcome.
What real teams say
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools.” Verified User in Marketing and Advertising, Small-Business UnderDefense G2 Verified Review
“UnderDefense Agentic AI SOC integrates well with our systems, specifically with our SIEM, Splunk. Honestly, so far, I haven’t identified any major dislikes.” Oleg K., Director of Information Security UnderDefense G2 Verified Review
The one question I would ask every finalist
Run the test, then watch what happens next. Tell us where your last simulation went quiet, and let’s figure out together why nobody got the call. That silence is the whole conversation, and it is the one I most want to have with you.
1. What are adversary simulation services, and how do they differ from a penetration test?
Adversary simulation services are structured engagements where skilled operators emulate the real tactics, techniques, and procedures (TTPs) of threat actors like nation-state APTs, ransomware crews, and insiders against your people, process, and technology. The goal is different from a penetration test in one critical way. A penetration test asks, “Can someone break in?” It finds and lists exploitable vulnerabilities, testing your prevention controls. Adversary simulation asks a harder question: “When someone breaks in, will you notice, and will you stop them in time?” That gap is where most teams get hurt. We have seen organizations pass a clean pen test and still get ransomed, because nobody was watching the right log at the right moment. Simulation tests the full chain, detect, contain, and respond, not just the perimeter. In practice, if a red team moves laterally to a domain controller and nothing fires, that silence is your finding. We build our managed detection and response service around closing exactly that detect-and-respond gap, and our penetration testing services handle the vulnerability discovery side. Choosing between them depends on whether you need a list of holes or proof your team catches a live attacker.
2. How much do adversary simulation services cost in 2026?
Adversary simulation engagements typically run $20,000 to $150,000 or more, spread across 4 to 12 weeks, scaling with scope, cloud complexity, and the depth of social engineering involved. Pricing is mostly custom, which is exactly why buyers struggle to budget. We anchor estimates to verified transaction data rather than vendor brochures. There are three common models:
-
Project-based: Mandiant averages around $83K per year for one-off APT-grade tests.
-
Subscription: IBM X-Force Red cloud testing starts near $16K for multi-year, multi-scope programs.
-
Day-rate: NCC Group bills roughly £1,450 to £1,750 per day for defined-scope work.
One honest caveat: every major provider in this space is enterprise-tier. If you run a 50-person shop, expect to scope down hard or look elsewhere. The real budgeting move is reframing the spend. The strongest case is not “we bought more tools,” but “we made the tools we already pay for actually work.” Our MDR price guide breaks down predictable cost models, and our pentest pricing page gives transparent anchors so you avoid the “contact sales” black box.
3. Who are the best adversary simulation providers in 2026?
There is no single “best,” only best-for-your-dominant-need. We analyzed and verified nine providers actively offering adversary simulation, red teaming, or purple teaming as a live service. Here is how we would shortlist by need:
-
Nation-state realism: Mandiant (live incident-response intelligence) or CrowdStrike (telemetry on 230+ tracked actors).
-
Regulatory mandates: NetSPI (DORA, TIBER-EU, CBEST) or Coalfire (FedRAMP, CMMC).
-
Identity and Active Directory exposure: SpecterOps, with BloodHound attack-path removal.
-
Social engineering depth: TrustedSec, founded by the creator of the Social-Engineer Toolkit.
-
Detection plus human response: UnderDefense.
The deciding question is simple: after the test, will someone actually pick up the phone? Many engagements end in a 90-page PDF and silence. The right partner tells you which alert should have fired, why it didn’t, and what to fix on Monday. We built UnderDefense for teams that want simulation paired with a human analyst who responds within minutes, not just alerts. Our guide to the best pentest companies compares vendors in more depth to help you match a partner to your exposure.
4. What is the difference between red teaming, purple teaming, BAS, and AEV?
All of these map to MITRE ATT&CK, so the real differences are goal, visibility, and cadence, not whether they are “real” hacking.
-
Red Team: Tests detection covertly across the full kill chain. Defenders are blind. Run annually or periodically. Output is an attack narrative and gaps.
-
Purple Team: Attackers and defenders collaborate to improve detection in real time. Recurring. Output is tuned detections and a coverage map.
-
BAS (Breach and Attack Simulation): Tool-driven, continuous automated replay of known attacks. Output is a coverage scorecard.
-
AEV (Adversarial Exposure Validation): Mixed automated and manual validation of exposures with real exploitation. Output is prioritized, proven exposures.
-
Adversary Simulation: Emulates a specific real threat actor end to end, scoped by objective. Output is detect-respond proof plus remediation.
Our practical advice: if you have never run a collaborative purple team, start there to build detections before commissioning a covert red team to grade them. Running a covert test on an untuned SOC just buys you expensive confirmation that you are not ready. This is why we emphasize continuous security monitoring over one-off tests, scope to your maturity, not your ambition.
5. How does an adversary simulation engagement actually flow from start to finish?
A strong engagement runs as one chain: threat-led scoping, execution, deliverables, and remediation. If the final report cannot say which alert should have fired and did not, it failed.
-
Step 1, Threat-led scoping: Start with a question, not a tool. What are your crown jewels: PCI data, patient records, source code, or admin access? Set the objective, the threat actor being emulated, the rules of engagement, and the in-scope MITRE techniques.
-
Step 2, Execution: The attack runs and three control layers get graded, prevent, detect, and respond. Most teams forget the third. A perfect detection score still fails if no human responds.
-
Step 3, Deliverables: Demand a clear attack narrative, replayable activity logs, and a detection-gap analysis tied to specific MITRE techniques. Avoid reports that list findings but never name the silent alert.
-
Step 4, Remediation: The best firms hand you a remediation engine and a re-test, not just advice.
We hold ourselves to a 2-minute alert-to-triage and a 15-minute critical escalation to a human analyst, which we document in our cybersecurity SLA. Reproducibility matters: if you cannot replay the attack, you cannot prove you fixed it.
6. How do we prove the ROI of adversary simulation to our board?
The board does not buy “we ran a red team.” They buy outcomes tied to dollars. Here is where most security leaders lose the room, and how we would win it back. The strongest ROI story is not “we bought more tools.” It is “we made the tools we already pay for actually work.” That reframes spend from a cost center into functional assurance of the business. We would bring four things to the board:
-
The specific attack path that succeeded, in plain English.
-
Which control should have fired and stayed silent.
-
The dollar cost of that gap if a real actor had used it.
-
The fix, and the re-test that proves it closed.
There is also a switcher-economics angle. Most teams over-pay a “log tax,” ingesting everything into a cloud SIEM whether it helps detection or not. Tuning that ingestion can cut bills meaningfully while improving signal, which is the core promise of a well-run managed SIEM. Map your spend to the NIST Cybersecurity Framework. If 90% sits in “Protect” but “Respond” is still manual, our 2026 cybersecurity budget guide shows how to rebalance, and that gap finding is your ROI case.
7. Which regulations require adversary simulation or threat-led testing?
Regulators have turned “nice to have” into “prove it.” The new game is showing a regulator that you actually tested your defenses against a real threat actor, not just ticked a checkbox. The frameworks driving this in 2026 include:
-
TIBER-EU (EU): Intelligence-led red team testing for financial entities.
-
CBEST (UK): Threat-led penetration testing for regulated finance.
-
DORA (EU): Mandatory operational resilience and threat-led testing.
-
NIS2 (EU): Stronger risk management and sovereign data handling.
-
SEC Item 1.05 (US): Disclosure of material cyber incidents.
-
ISO 27001 / SOC 2 (Global): Evidence of tested security controls.
The key vendor-selection rule: pick a partner whose accreditations match your regulator, or you will pay twice. NetSPI carries DORA, TIBER-EU, and CBEST accreditations; Coalfire pairs offense with FedRAMP and CMMC. If DORA is your driver, our DORA penetration testing service is built for exactly that mandate, and our broader compliance services help you turn test evidence into audit-ready proof.
8. How is AI changing adversary simulation, and why is continuous purple teaming the new standard?
AI is rewriting both the attack and the test. Patents now describe AI that builds simulations on its own; Darktrace holds a patent for an “intelligent adversary simulator,” and Fortinet filed one for threat-informed simulation driven by live intelligence feeds. Emulation is becoming continuous and self-updating. Here is our contrarian worry. Agentic AI, meaning autonomous agents that act on their own, lets mediocre attackers run elite attack chains. The skill floor is dropping fast, and that should concern every defender. It also creates a new blind spot: legacy tools ignore what your own AI agents like Cursor, Copilot, and Cline actually do in production. This is why a once-a-year red team no longer holds. It is a photo, but your environment is a video. By the time the PDF lands, your stack has changed. Continuous purple teaming fixes that, you build a detection, test it, tune it, and repeat in one loop. A “fleet of Ferraris with rookie drivers” still crashes, so AI scales the routine work while humans drive the edge cases. We extended this thinking into MDR for AI to monitor the agentic attack surface where the next breach hides.