Q1: How Much Does DropZone AI Actually Cost in 2026?
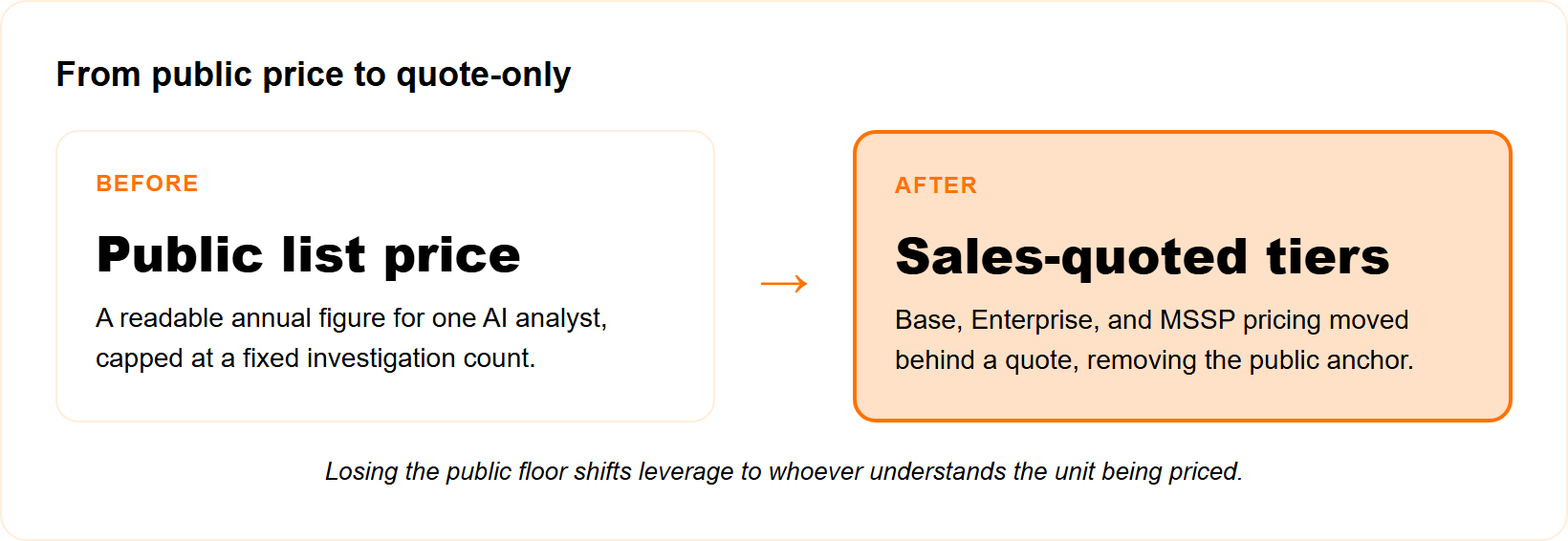
DropZone AI historically started at $36,000 per year for one AI SOC analyst handling up to 4,000 full investigations, roughly $9 per investigation, with unlimited users, 80+ integrations, threat intel, and an 8-hour SLA. It listed near $24,000 in 2024, climbed to $36,000 by 2025, then in 2026 DropZone pulled public prices entirely and moved to sales-quoted Base, Enterprise, and MSSP tiers after its $37M Series B.
💰 The number you actually came here for
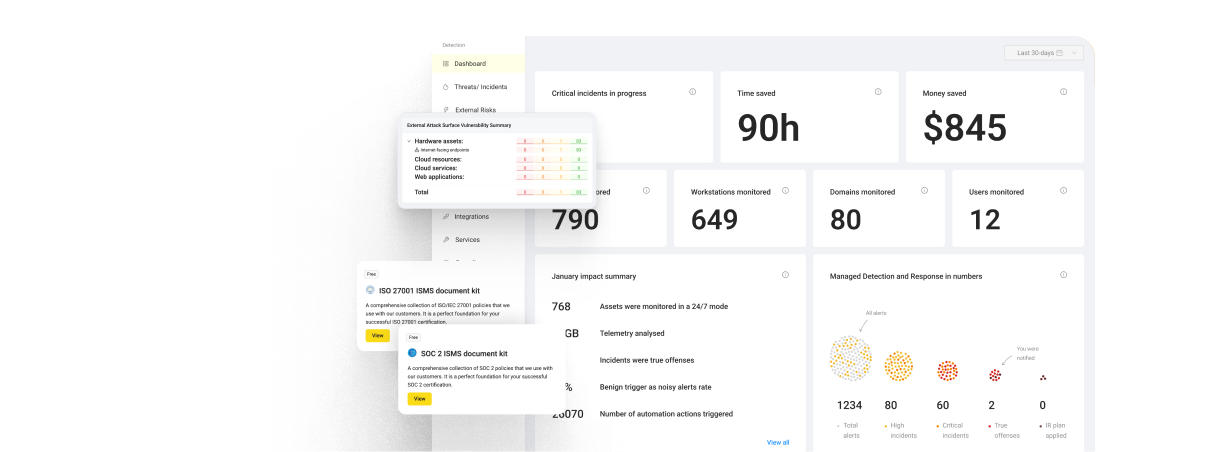
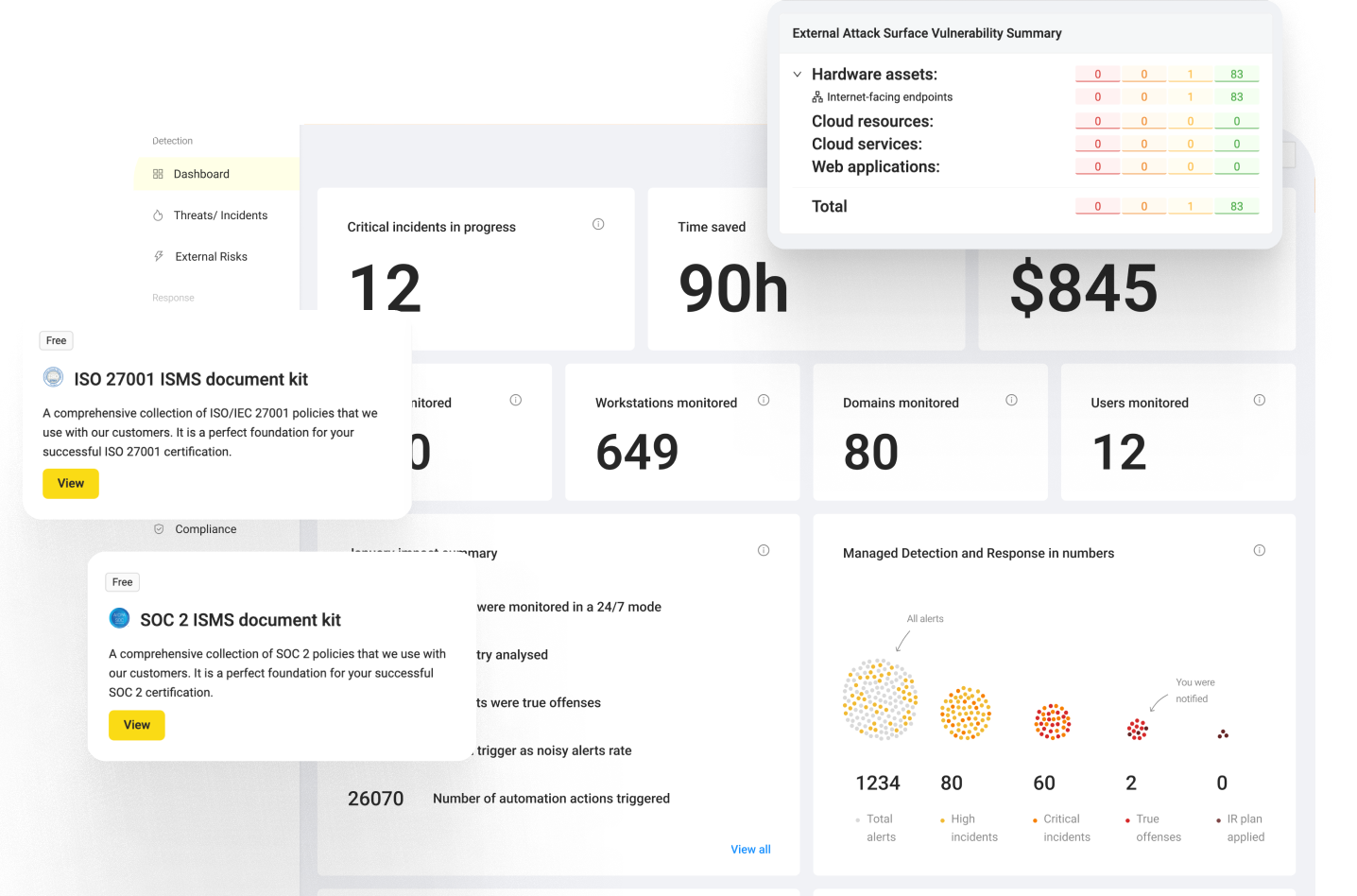
Let me give you the figure before anything else. The published list price was $36,000 a year for a single AI SOC analyst, capped at 4,000 investigations.
That works out to about $9 per investigation. The package bundled unlimited human users, more than 80 integrations, threat intelligence feeds, and an 8-hour service-level agreement on investigations.
I have spoken with Edward Wu, DropZone’s founder, who holds around 30 patents in agentic security. He has been refreshingly honest about agentic AI versus the marketing hype, so I want to match that honesty on price.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
📉 Why the public number quietly disappeared
Here is the part most pricing pages skip. DropZone listed near $24,000 in 2024, then raised the floor to $36,000 by 2025.
In 2026, the public price vanished. After a $37M Series B and a push into the channel, DropZone moved every deal behind a sales quote across Base, Enterprise, and MSSP tiers.
That shift matters for your budget. A private number means you cannot benchmark your quote against a public floor, so your leverage now depends on how well you understand the unit you are buying. This is exactly why we built a transparent MDR pricing model you can read before any call.
⚠️ What a quote-only model changes for you
When pricing goes private, two things happen to a buyer. You lose the public anchor, and the vendor gains room to price by your alert volume and tenancy needs.
That is not automatically bad. It does mean you walk into the call needing your own investigation-volume math, which is exactly what the next section builds, and our 2026 cybersecurity budget playbook walks through that math step by step.
For context, the strongest field benchmark I can point to is our own: customers see an 830% return over three years and 99% noise reduction, numbers I will hold up to scrutiny later in this article.
✅ Where this leaves the practical buyer
DropZone’s move toward quote-only pricing is a legitimate enterprise choice. The honest trade-off is reduced transparency at the exact moment a CISO is trying to defend a brand-new line item to a CFO.
At UnderDefense, we run the opposite play on packaging. We lead with clear, all-inclusive operating-expense pricing you can read upfront, so the conversation starts with scope, not a guessing game over what the quote will be. You can see how that looks on the platform itself at https://underdefense.com/platform/.
That is the spirit of this whole guide: show the number, show the math, and let you decide. So before you request any quote, you need to know what one investigation actually is, and what happens when you run out of them.
Q2: What Do You Get, and What Happens When You Hit the Cap?
One DropZone license covers up to 4,000 full investigations per year, unlimited human users, all alert categories, 80+ integrations, and threat-intel feeds under an 8-hour SLA. Tiers climb from Base to Enterprise (single-tenant isolation) to MSSP (multi-tenant). As you near 4,000 investigations, DropZone sends a grace-window notification and lets you buy capacity packages, with volume discounts for larger commitments.
🧩 You are buying investigations, not seats
Here is the mental model that fixes most budget mistakes. You are not paying per analyst seat. You are paying for investigation capacity.
One investigation is a complete report: a summary, a verdict, and the work log showing how the agent reached it. Related alerts from a single incident collapse into one investigation, so a noisy attack does not drain your count in one burst.
Why is one investigation priced like real work? Because it is real work. DropZone fires more than 100 distinct language-model calls to investigate a single alert, which is why this is metered like compute, not like a flat SaaS seat.
🪜 The tier ladder: Base, Enterprise, MSSP
The tiers map to how isolated your environment needs to be. That isolation question is usually a compliance question in disguise, and our compliance services can tell you which tenancy your auditor will actually demand.
| Tier | Tenancy | Best fit |
|---|---|---|
| Base | Shared | Lean teams starting with one AI analyst |
| Enterprise | Single-tenant isolation | Regulated orgs needing data separation |
| MSSP | Multi-tenant | Providers serving many client environments |
If your auditor cares about data residency or tenant separation, you are likely an Enterprise buyer, and that step-up carries cost. Map your tenancy need before the sales call so you are not upsold into isolation you do not require.
⏰ What happens when you hit 4,000
This is the question buyers forget to ask. As you approach the cap, DropZone sends a grace-window notification rather than cutting you off mid-incident.
You then buy additional capacity packages, with volume discounts available for larger commitments. The risk to model is simple: if your real alert volume runs hot, overage becomes a recurring line, not a one-time top-up.
✅ Your Monday-morning task
Do one thing before you request a quote. Pull your last 90 days of alert data and estimate how many would become full investigations.
If that number sits comfortably under 4,000, the base tier is honest value. If it routinely spikes past it, model the overage now, because that is where a clean-looking quote gets expensive.
This is where our approach differs in unit of value. The UnderDefense Agentic AI SOC prices the outcome, managed detection plus human response, with a 2-minute Alert-to-Triage SLA and 15-minute escalation for critical incidents, so you are not rationing a counter to stay under a cap. You can see the live workflow at https://underdefense.com/platform/, and our full MDR service wraps human response around every verdict. The point is not that capped pricing is wrong, but that you should know exactly which model you are signing.
Q3: Why Does Agentic AI Cost More Than a Standard SaaS Subscription?
Agentic AI costs more than ordinary SaaS because each investigation burns real compute. DropZone fires 100+ language-model calls to investigate one alert, and agents generate roughly 450% more network traffic than a human doing the same task. You rent autonomous labor that consumes tokens, bandwidth, and orchestration overhead, which is why these line items never appeared in last year’s budget and why a CFO needs the unit economics spelled out.
💸 Why this line item never existed before
I hear the same thing on calls with finance-minded CISOs. These costs were never in anyone’s budget, so they feel alarming by default.
That reaction is fair. A standard SaaS tool charges you for access to software. An agentic SOC charges you for autonomous labor that thinks, and thinking costs tokens.
My current read, and I have watched real token bills, is that the sticker shock comes from a category mismatch. You are comparing a worker’s wage to a software subscription, and those are not the same line.
🔢 The token tax and the network tax

Here is the mechanism in plain numbers. To investigate one alert, DropZone’s system makes over 100 distinct language-model invocations, each consuming tokens.
Then there is traffic. One study found that an agent generates about 450% more network traffic than a human performing the same task, so your bandwidth demand signal climbs too.
The danger is runaway consumption. As one practitioner put it, an agent going awry could consume a year of token budget in a week, and managers are already telling teams these tokens are getting too expensive, ease up a bit. Our take on this is in our breakdown of AI SOC red flags.
⚠️ The $24,000 single-agent cautionary tale
This is not theoretical. In one observed environment, a single misbehaving agent ran up almost $24,000 in token spend, fully visible inside the monitoring view.
That visibility is the lesson, not the horror story. You can only control what you can see, so any agentic spend you approve must come with per-agent cost observability built in.
I might be slightly conservative here, but I would not sign an agentic contract without the ability to watch token burn per agent, in near real time.
💰 How to brief the board without the panic
Reframe the number for your CFO. This is the cost of work that a human analyst would otherwise do, slower and at a higher fully-loaded salary.
State it as labor replacement with a measurable throughput. That single reframe turns a scary token line into a defensible headcount-avoidance argument, which is the language a board actually rewards, and our SOC cost calculator puts real figures behind it.
The structural trade-off of pure usage-metered pricing is uncertainty: your bill moves with your incident volume, which is the one variable you do not control. At UnderDefense, we built the UnderDefense Agentic AI SOC on flat operating-expense pricing that bundles the agent labor and the human response into one predictable number, so the Tokenomics Shock never lands on your quarter. The aim is a SOC budget you can defend in advance, rather than reconcile in arrears.
Q4: What’s the Real Total Cost of Ownership Beyond the Sticker Price?
DropZone’s base price is the floor. True total cost adds overage packages past 4,000 investigations, external metering from the third-party SIEM, EDR, and threat-intel tools each investigation queries, and a tenancy step-up for Enterprise or MSSP. Model it as base license plus overage plus external tool metering plus tenancy. The easy-to-miss layer is external metering, which scales with how aggressively the agent investigates.
🧾 The sticker price is the floor, not the ceiling
The single most common budgeting error I see is treating the license fee as the full cost. It is the starting line.
An agentic SOC does not work alone. Every investigation queries your other tools, and those tools often charge by query, ingestion, or API call, so a busier agent quietly inflates bills you do not control.
From what surfaces when you actually run these systems, the external metering layer is the one that ambushes finance at renewal, because nobody modeled it on day one.
💸 The four cost layers, named
Build your budget as a stack, rather than a single number. Here is the full picture for an honest total cost of ownership, and our managed SIEM pricing guide shows how those tool-side costs stack up.
| Cost layer | What triggers it | How to estimate it |
|---|---|---|
| Base license | The annual subscription floor | Published or quoted tier price |
| Overage | Investigations past your 4,000 cap | 90-day alert volume projected forward |
| External tool metering | Agent querying your SIEM, EDR, threat intel | Per-query/ingestion rates times expected volume |
| Tenancy step-up | Enterprise isolation or MSSP multi-tenancy | Delta between Base and the tier you need |
The trap line is external metering, because it scales with how aggressively the agent investigates. As one practitioner warned, a year of budgeted token capacity can be consumed in a week when an agent goes awry, and the same dynamic hits your connected tools.
✅ The line you take into procurement
Carry one sentence into the negotiation. Ask the vendor to model your total cost across all four layers at your projected investigation volume, in writing.
If they can only quote the base license, you do not yet have a real number. A vendor who can model the full stack is showing you respect, and that is the partner you want. If you would rather talk it through, you can always contact us.
⚖️ Where the trade-off actually lands
Usage-metered tools give you precision and the freedom to start small. The permanent structural trade-off is that your bill follows your incident volume, plus the metering of every tool the agent touches.
At UnderDefense, we made a deliberate architectural choice to soften that. The UnderDefense Agentic AI SOC integrates with your existing customer-owned SIEM and EDR, so you keep your data and avoid vendor lock-in, and we bundle SOAR automation and incident response into one operating-expense figure rather than layering metered add-ons. You can see how that consolidation works at https://underdefense.com/platform/. Predictable total cost is the goal, so your renewal holds no surprises.
Q5: DropZone AI vs Competitors, How Does the Pricing Stack Up?
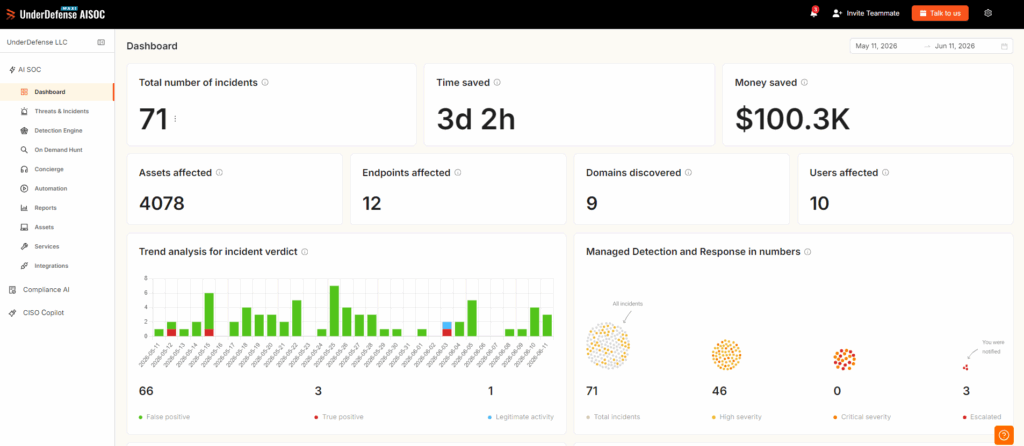
DropZone’s roughly $36K flat entry undercuts much of the agentic cohort: Torq starts near $60K, while MixMode and Exabeam bulk tiers run past $100K; Prophet Security, 7AI, Daylight, and Kai trend toward custom enterprise quotes. Pricing models differ more than the prices. DropZone meters investigations, traditional MDR charges per endpoint or flat, and many stop at escalating an alert rather than resolving it.
💰 The prices, side by side
Let me put the numbers in one place. Sticker price is where most buyers start, so here is the honest spread across the category, and our MDR pricing page lays out our own figures in full.
| # | Provider | Entry price | Pricing model | Who acts on the alert |
|---|---|---|---|---|
| 1.1 | UnderDefense | $11 to $15 per endpoint/month | Flat, all-inclusive OPEX | AI plus human analyst responds |
| 1.2 | DropZone AI | ~$36K/year | Per-investigation cap | AI investigates, you respond |
| 1.3 | Prophet Security | Custom quote | Enterprise contract | AI triage, you respond |
| 1.4 | 7AI | Custom quote | Enterprise contract | AI triage, you respond |
| 1.5 | Torq | ~$60K/year | Platform plus usage | Automation, you respond |
| 1.6 | MixMode / Exabeam | $100K+ | Bulk platform tiers | Detection, you respond |
⚖️ Why the model matters more than the sticker
Here is the wedge most comparison posts miss. A low sticker price means little when you still own every response action yourself.
Many vendors reduce false positives, then hand you the event to action. As one practitioner put it, all you do is send me an event and I still have to take action on it. That gap between detection and resolution is the real cost, which is why our MDR service wraps human response around every verdict. If you are weighing options, our MDR buyers guide walks through the questions that surface this gap.
✅ Where this leaves your shortlist
My read, after sitting on both sides of these deals, is that the cheapest sticker rarely wins on cost per resolved incident. You pay the difference later, in your own team’s hours, a dynamic we break down further in our MDR price guide.
This is the column we built UnderDefense to fill. We price flat per endpoint, so the bill does not swing with your incident volume, and our analysts communicate directly with affected users to resolve the alerts that other tools simply escalate back. The structural trade-off of detect-only models is that the response work stays on your plate, and that work is where lean teams quietly drown.
Q6: Is a Fully Autonomous SOC Worth Paying For, or a Marketing Lie?
A fully autonomous SOC is not yet real, and paying as though it were is a budgeting mistake. Letting software quarantine users with zero human oversight stays technically and operationally unsafe. You still need humans as generals directing the AI foot soldiers. The value worth paying for is eliminating whole classes of manual work; speeding up the same overloaded analysts just produces the same noise, faster.
🤖 The lights-out pitch, and why I push back
Every other deck now promises a self-driving SOC. I have run security operations for two decades, and I will tell you plainly where that promise breaks.
It is still technically impossible to fully replace a SOC from Tier 1 to Tier 3 with software. The real-world risk of a piece of software quarantining users with no human oversight is the part the marketing skips, and we flag exactly these patterns in our rundown of AI SOC red flags.
The standard read gets this backwards. Full autonomy is sold as the goal, when the safer and more useful design keeps a human in the loop on consequential actions.
🧒 The teenager problem
Here is the analogy I keep coming back to. Agents are like teenagers. They are supremely intelligent, but they have no fear of consequence, and sometimes they do stupid things.
That is fine when an agent drafts an investigation summary. It is dangerous when the same agent can lock out a real employee at 2 a.m. on a hunch.
So the question is not whether the AI is smart. It is whether you have wired in oversight before the agent can take an action it cannot take back, a balance we examine in our piece on whether AI kills or saves your SOC team.
⚙️ What you should actually pay for
Speed alone is a trap. If you keep the same analysts looking at the same alerts, only faster, that is not transformation, just faster noise.
The real value arrives when AI eliminates whole classes of work. The agent handles the repetitive enrichment and verification, so your people stop doing it at all, which is the heart of practical SOC automation.
I might be slightly optimistic on timelines here, but the direction is clear. Pay for work elimination plus oversight, and treat any “no humans needed” claim as a flag to slow down.
This is exactly the model we run at UnderDefense, and we named it for what it is, AI plus a human ally. The AI collects context at scale across identity, endpoint, cloud, and SaaS, and our analysts decide and respond, including talking directly to the affected user when an alert needs human judgment. You can watch every step in the live triage queue, observable and auditable, at https://underdefense.com/platform/. The honest trade-off is that we do not sell a magic lights-out button, because in real operations that button gets someone locked out of payroll on a Friday night.
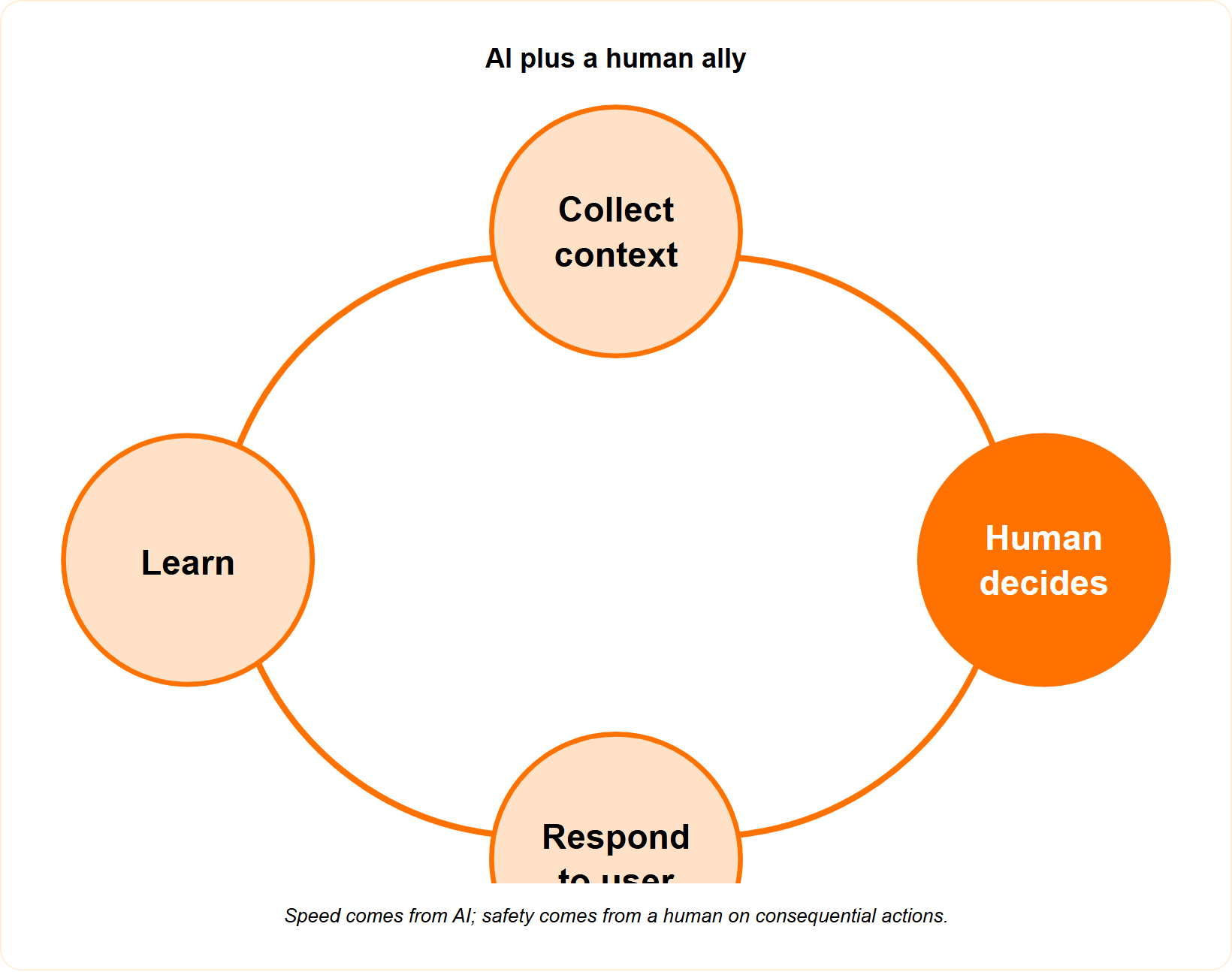
Q7: Does the Investigation-Cap Model Create a Hidden Coverage Gap?
Yes, capacity-capped pricing can quietly recreate a coverage gap. To stay under 4,000 investigations, teams start cherry-picking which alert types to send the agent, leaving low-prevalence streams uninvestigated. Peer-reviewed research shows those rare, neglected alerts are exactly where the costliest misses hide. So the cheapest-looking quote can carry the highest breach risk when the cap forces you to ration coverage.
🎯 The claim: a cap nudges you to ration
Here is my central worry with per-investigation pricing. A hard cap quietly changes behavior, and not for the better.
When every investigation counts against 4,000, teams start deciding which alert types are “worth” sending the agent. That decision feels like cost control, but it is really coverage rationing in disguise, the opposite of true continuous security monitoring.
📉 The evidence: misses hide in the rare streams
This is where the research gets uncomfortable. Academic work on security operations shows that the dangerous misses concentrate in low-prevalence alert streams, the rare ones teams are most tempted to drop.
A 2025 survey of alert handling in security operations centers found that high volume pushes teams toward triage shortcuts, and those shortcuts raise the odds of missing a genuine threat. Cap-driven cherry-picking is the same failure mode, just caused by budget instead of fatigue.
So the cheapest quote can carry the highest risk. You save on investigations and pay it back in the one incident you chose not to look at.
🛠️ The Monday action
Do this before you sign any capped contract. Pull your real numbers and see how much you would have to ration.
- Measure the percentage of alerts you actually investigate today.
- Estimate how many full investigations your volume would generate in a year.
- Compare that honestly against the cap, then add headroom for a bad month.
If the cap forces you to skip whole alert categories, you have not bought coverage. You have bought a smaller version of the gap you started with. Our 2026 cybersecurity budget playbook shows how to size that volume honestly.
✅ Coverage without the rationing
The goal should be to make investigations faster across everything, rather than to investigate less. That is the design choice we made at UnderDefense. The UnderDefense Agentic AI SOC investigates and triages at scale, cutting roughly 99% of the noise, while still covering the full alert stream rather than dropping streams to fit a budget line. When an alert needs human context, we ping the user directly through Slack, Teams, or email instead of quietly closing it. The trade-off worth naming is that total coverage takes real orchestration, and that is precisely the work we take off your team’s plate.
Q8: What Does the Evidence Say About Agentic SOC Accuracy?
Independent evidence is encouraging but conditional. In a controlled study, a tool-connected language-model agent reached 60.7% triage accuracy versus 39.3% for human experts, yet stripping its tool access collapsed accuracy by about 71%. That proves integrations, not the model, drive value. Patented methods now show iterative converging investigation and root-cause reasoning. ROI is real when integration depth and report quality are real.
🔬 What the evidence actually shows
Let me separate proof from pitch. The strongest independent signal I have seen comes from controlled academic testing, rather than vendor calculators.
A 2025 study at JKU Linz tested language-model agents on cloud alert triage. The tool-connected agent hit 60.7% accuracy against 39.3% for human experts, a meaningful gap.
📊 The result with a catch
Here is the part every buyer should underline. When researchers removed the agent’s tool access, its accuracy fell by roughly 71%.
That single finding reframes the whole purchase. The value lives in the integrations and context, rather than in the model itself. A clever model with shallow access is a confident guesser, which is why deep platform integrations matter more than the model brand.
Field data tells the same story. In one bake-off, a customer sent 12,000 investigations over two weeks, and the AI reached 99.3% agreement with their human team, at about 11 times faster mean time to investigate. What once took three hours dropped to minutes, the kind of result we track through SOC metrics like MTTD and MTTR.
🧪 What to verify in your POC
Patents now point toward iterative, converging investigation and root-cause reasoning rather than single-pass classification. Ask whether a vendor’s investigation truly reasons or just labels.
- Confirm depth of integration with your SIEM, EDR, and identity sources.
- Test on your own alerts, repeating each case 5 to 15 times, since results vary.
- Map detection coverage to the MITRE ATT&CK framework, the industry catalog of attacker techniques.
✅ Grounding the claim
This is why we built UnderDefense around integration depth and observable evidence rather than a black box. The UnderDefense Agentic AI SOC maps its detections to MITRE ATT&CK and runs at about 96% MITRE coverage, so you can audit what is watched and what is not. The honest caveat from the research stands: accuracy holds only when the tool access is real, which is exactly why we keep your existing managed SIEM and EDR connected instead of asking you to trust a sealed model.
Q9: What ROI Should You Expect, and How Does It Compare to Hiring?
DropZone replaced its public price with an ROI calculator modeling roughly $186K in annual return, framing the spend against the cost of a Tier-1 analyst hire. The honest math compares fully loaded analyst salary, ramp time, and attrition against the agent’s investigation throughput. The strongest ROI case combines avoided headcount with hard time-and-cost-saved data rather than a vendor’s default calculator inputs.
💰 The claim: model it like a hire, not a tool
Here is how I would frame this for your board. An agentic SOC competes against the cost of an analyst, so model it that way.
DropZone’s own calculator stacks the spend against a Tier-1 analyst’s loaded cost, modeling around $186K in annual return. That framing is fair, as long as you supply your own inputs rather than the defaults. Our SOC cost calculator lets you run those numbers with your own figures.
📊 The proof: avoided headcount plus measured savings
A vendor calculator is a starting point. The number that survives scrutiny is the one your dashboard measures after go-live.
In field data, an agentic SOC delivered roughly 830% return over three years, with about 99% noise reduction. Pair that with the real cost of a hire, fully loaded salary, months of ramp, and the attrition that resets the clock, a build-versus-buy tension we unpack in our look at outsourced versus in-house SOC.
🗣️ What buyers actually report
The cost-and-value verdict shows up plainly in customer reviews.
“Even with our rapid growth and limited resources, we’ve seen a real improvement in our overall security posture. We now have 24/7 threat detection and response, centralized management, and much more confidence in our data security.”
Inga Miller, CEO, Network Security Company UnderDefense Clutch Verified Review
“Their goal orientation and ease of communication make it a pleasure to work with them.”
Victoria Zhovnir, Information Security Specialist UnderDefense Clutch Verified Review
✅ The metrics to demand in your own model
Do not buy on speed alone. The deeper value comes from eliminating whole classes of manual work, so your people stop doing repetitive triage entirely, the core promise of mature managed detection and response.
Before signing, insist your ROI model tracks these:
- Incidents handled, and analyst days saved per month.
- Dollars saved against a fully loaded hire.
- The false-positive versus true-positive verdict trend over time.
This is exactly what we expose at UnderDefense. Our ROI dashboard shows incidents handled, analyst time saved, and dollars saved as observable, audited outcomes, viewable on https://underdefense.com/platform/, rather than a pre-filled calculator you cannot verify. The honest caveat is that your numbers will differ from any vendor’s defaults, which is the whole point of measuring them yourself.
Q10: Should You Build, Buy DropZone, or Choose a Managed AI SOC?
Build only with rare engineering depth to maintain a non-deterministic agent in production, knowing DIY is exponentially harder than buying. Buy DropZone if you have a capable in-house team that needs Tier-1 investigation automation and can absorb the response work. Choose a managed AI SOC if you need detection and response together, someone to act on the verdict, rather than just a faster alert.
⚠️ The trap: build-versus-buy looks simpler than it is
I talk to sophisticated teams who assume they can just build the agent. The honest answer is that the difficulty of DIY-ing an AI agent is exponentially higher than buying one, a recurring theme in our guide to building a SOC.
A language model in production behaves a bit like a slot machine. The same prompt can return different answers, so you need real engineering depth to keep it stable and safe.
🧱 The counter-argument: give me the Lego bricks
There is a fair pushback, and I respect it. Some mature teams say, give me all the Lego bricks and the data, and skip the black box.
That is the right instinct on data ownership. Keep your SIEM and your logs under your control, so no vendor locks you in, which is why our managed SIEM keeps your data in your own tenant.
The trade-off is maintenance. Owning the bricks means owning the upkeep, the tuning, and the on-call when the agent does something a teenager would.
✅ Match the path to your profile

Here is how I would decide, plainly.
- Build if you have rare in-house engineering depth and want to own every brick.
- Buy DropZone if you have a capable team that just needs Tier-1 investigation sped up.
- Choose managed if you need detection and response together, with someone to act on the verdict.
For lean teams, the managed path removes the most risk. At UnderDefense we run a fully managed AI SOC with a 15-minute escalation for critical incidents, and our analysts learn your VIPs, critical assets, and what normal looks like in your environment. When an incident does land, our incident response team acts on the verdict. The honest trade-off is less hands-on-keyboard control for you, which is exactly the burden lean teams are trying to shed.
Q11: How Should You Budget for an Agentic AI SOC Without Getting Burned?
Budget for an agentic AI SOC by pricing the outcome rather than the agent. Start from your real investigatable alert volume, add overage and external-tool metering, demand a predictable cap so no rogue agent torches a quarter’s budget, and score every vendor on who responds, not just who detects. Favor transparent, all-inclusive packaging, insist on a board-ready investigation report, and run a paid bake-off before signing.
💰 The principle: price the outcome, not the agent
The budgeting mistake I see most often is pricing the tool instead of the result. The outcome you actually want is resolved incidents, with someone accountable for the response.
Start from reality. Pull your real numbers before any vendor pulls them for you, because their defaults rarely match your queue, and our 2026 cybersecurity budget playbook shows how to gather them.
✅ The six-step evaluation checklist
Walk this list before you sign anything. Each step closes a gap I have watched teams fall into, and our MDR buyers guide expands on every one.
- Measure your real volume. Count the alerts you actually investigate today, not the raw firehose.
- Price the overage. Ask exactly what happens, and what it costs, when you exceed the plan.
- Check external-tool metering. Some agents bill for every enrichment lookup, so model that.
- Demand a predictable cap. No single rogue agent should be able to torch a quarter’s budget.
- Ask who responds. Score detection and response separately, since detection alone leaves work on you.
- Run a paid bake-off. Send a real alert sample, and validate each verdict 15 times to confirm it holds.
That bake-off is not theory. One customer ran 12,000 investigations over two weeks before committing, which is exactly the rigor a budget this size deserves. Comparing providers in our MDR price guide can frame that test.
🗣️ A real example to anchor against
This is the responsiveness and value bar I would hold a vendor to.
“Dramatically reduced incident response times, thanks to Slack integration. We also noted a significant decline in potential breaches, ensuring client trust remains intact.”
Alexander Benedychuk, CEO, RegisTeam UnderDefense Clutch Verified Review
⏰ Where I’d land
Humans click, but agents swarm, and your budget has to assume both. The low-regret choice is transparent, all-inclusive packaging where the response is included, rather than sold back to you later, an approach echoed in our MDR pricing.
That is the model we built at UnderDefense, a predictable OPEX price with concierge human response and a board-ready investigation report on every incident. So here is my real question for you, rather than a pitch: what does your alert queue actually look like on a bad Monday, and how many of those alerts does anyone truly investigate today? Tell me that, and we can size the right model together.
See how UnderDefense Agentic AI SOC resolves a real incident on your stack.
1. How much does DropZone AI cost in 2026?
DropZone AI historically listed at roughly $36,000 per year for a single AI SOC analyst capped at 4,000 full investigations, which works out to about $9 per investigation. That package bundled unlimited human users, more than 80 integrations, threat intelligence feeds, and an 8-hour SLA on investigations.
The price climbed over time:
- Near $24,000 in 2024.
- A $36,000 floor by 2025.
- Public pricing pulled entirely in 2026.
After a $37M Series B and a channel push, DropZone moved every deal behind a sales quote across Base, Enterprise, and MSSP tiers. A private number means you cannot benchmark your quote against a public floor, so your leverage now depends on understanding the unit you are buying.
We run the opposite play on packaging. We lead with clear, all-inclusive operating-expense MDR pricing you can read upfront, so the conversation starts with scope rather than a guessing game over the quote.
2. What does one DropZone AI license actually include?
One DropZone license covers up to 4,000 full investigations per year, unlimited human users, all alert categories, more than 80 integrations, and threat-intel feeds under an 8-hour SLA. The mental model that fixes most budget mistakes is simple: you are not paying per analyst seat, you are paying for investigation capacity.
One investigation is a complete report:
- A summary of what happened.
- A verdict on the alert.
- The work log showing how the agent reached it.
Related alerts from a single incident collapse into one investigation, so a noisy attack does not drain your count in one burst. Tiers climb from Base (shared) to Enterprise (single-tenant isolation) to MSSP (multi-tenant), and that isolation question is usually a compliance question in disguise.
We price the outcome instead, bundling managed detection plus human response, which is the heart of our managed detection and response service, so you are not rationing a counter to stay under a cap.
3. What happens when you hit the 4,000 investigation cap?
As you approach the cap, DropZone sends a grace-window notification rather than cutting you off mid-incident. You then buy additional capacity packages, with volume discounts available for larger commitments.
The risk to model is straightforward: if your real alert volume runs hot, overage becomes a recurring line, not a one-time top-up. Before requesting a quote, do one thing:
- Pull your last 90 days of alert data.
- Estimate how many would become full investigations.
- Project that forward and add headroom for a bad month.
If that number sits comfortably under 4,000, the base tier is honest value. If it routinely spikes past it, model the overage now, because that is where a clean-looking quote gets expensive.
This is exactly the volume math we walk through in our 2026 cybersecurity budget playbook, so you walk into any vendor call with your own numbers rather than their defaults.
4. Why does agentic AI cost more than a standard SaaS subscription?
Agentic AI costs more because each investigation burns real compute. A standard SaaS tool charges you for access to software, while an agentic SOC charges you for autonomous labor that thinks, and thinking costs tokens.
The mechanics are concrete:
- DropZone fires more than 100 distinct language-model calls to investigate a single alert.
- Agents generate roughly 450% more network traffic than a human doing the same task.
- A single misbehaving agent has run up almost $24,000 in token spend in one observed environment.
The honest reframe for a CFO is that this is the cost of work a human analyst would otherwise do, slower and at a higher fully-loaded salary. That turns a scary token line into a defensible headcount-avoidance argument.
We built our platform on flat operating-expense pricing that bundles agent labor and human response into one predictable number, so the token shock never lands on your quarter. You can run your own figures with our SOC cost calculator.
5. What is the real total cost of ownership beyond the sticker price?
The sticker price is the floor, not the ceiling. An agentic SOC does not work alone, so every investigation queries your other tools, and those tools often charge by query, ingestion, or API call.
Build your budget as a four-layer stack:
- Base license: the annual subscription floor.
- Overage: investigations past your 4,000 cap.
- External tool metering: the agent querying your SIEM, EDR, and threat intel.
- Tenancy step-up: the delta for Enterprise isolation or MSSP multi-tenancy.
The trap line is external metering, because it scales with how aggressively the agent investigates. Carry one sentence into procurement: ask the vendor to model your total cost across all four layers at your projected volume, in writing.
We softened that structurally by integrating with your existing customer-owned SIEM and EDR, which keeps your data in your own tenant via our managed SIEM, and bundling response into one OPEX figure rather than layering metered add-ons.
6. How does DropZone AI pricing compare to competitors?
DropZone’s roughly $36K flat entry undercuts much of the agentic cohort. For context across the category:
- Torq starts near $60K per year.
- MixMode and Exabeam bulk tiers run past $100K.
- Prophet Security, 7AI, Daylight, and Kai trend toward custom enterprise quotes.
The models differ more than the prices. DropZone meters investigations, traditional MDR charges per endpoint or flat, and many vendors stop at escalating an alert rather than resolving it. A low sticker price means little when you still own every response action yourself.
That gap between detection and resolution is the real cost, and it is the column we built ourselves to fill. We price flat per endpoint, so the bill does not swing with your incident volume, and our analysts act on the verdict instead of handing it back.
If you are weighing options, our MDR buyers guide walks through the questions that surface this detect-only gap.
7. Is a fully autonomous SOC worth paying for?
A fully autonomous SOC is not yet real, and paying as though it were is a budgeting mistake. It remains technically impossible to fully replace a SOC from Tier 1 to Tier 3 with software, and the real-world risk of a tool quarantining users with no human oversight is the part marketing skips.
The analogy we keep returning to: agents are like teenagers. They are supremely intelligent, but they have no fear of consequence, so they sometimes do stupid things. That is fine when an agent drafts a summary, but dangerous when the same agent can lock out a real employee at 2 a.m.
So pay for the right thing:
- Work elimination, where AI removes whole classes of manual triage.
- Oversight, where a human approves consequential actions.
- Speed only if it is paired with both, since faster noise is still noise.
This is the model we run, AI plus a human ally, and we treat any ‘no humans needed’ claim as one of the AI SOC red flags to slow down on.
8. What ROI should you expect from an agentic SOC versus hiring an analyst?
An agentic SOC competes against the cost of an analyst, so model it that way. DropZone’s own calculator stacks the spend against a Tier-1 analyst’s loaded cost, modeling around $186K in annual return, which is fair as long as you supply your own inputs rather than the defaults.
The numbers that survive scrutiny are the ones your dashboard measures after go-live:
- Incidents handled, and analyst days saved per month.
- Dollars saved against a fully loaded hire, including ramp and attrition.
- The false-positive versus true-positive verdict trend over time.
In field data, an agentic SOC delivered roughly 830% return over three years with about 99% noise reduction, and one bake-off reached 99.3% agreement with a human team at 11 times faster mean time to investigate.
We expose these as observable, audited outcomes rather than a pre-filled calculator, and you can frame the hiring trade-off through our view on outsourced versus in-house SOC.