Q1. What Are AI SOC Guardrails, and Why Did 2026 Make Them Non-Negotiable?
AI SOC guardrails are the technical and procedural controls that limit what an autonomous security agent can decide and do. They enforce scope limits, confidence thresholds, identity boundaries, and human override before any high-impact action runs. They span three layers: input, action, and output. In 2026 they became non-negotiable because agentic SOC platforms now quarantine users, disable accounts, and touch production. An ungoverned agent becomes an attack surface of its own.
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
The fear behind the search
A CTO asked me a blunt question on a call last quarter. “Can you get comfortable with a black box making important decisions in your org?” Then the real worry came out. “What if the agent went and deleted the production database?”
That fear is rational. The old generation of AI advised you. It scored an alert and waited. The new generation acts. It can isolate a host, kill a session, or revoke a token on its own.
The three-layer control model

Most ranking guides agree on a layered model, and it holds up in practice. You govern three things in order.
- Input layer: what the agent is allowed to read and ingest, including prompts and external data.
- Action layer: what the agent is allowed to do, which tools it can call, and which systems it can write to.
- Output layer: what the agent is allowed to return, surface, or auto-close.
The OWASP Top 10 for Agentic AI Applications (2026) frames the threat side of this same stack, from compromised reasoning to tool misuse. Vendor playbooks map their controls onto these layers too. This same logic underpins our approach to AI in the modern SOC.
The shift that matters: access control to action control
Here is the framing I keep coming back to. We are moving from access control to action control. Knowing what an agent can reach is no longer enough. You have to verify that the agent’s behavior matches the intent you actually had.
That single shift is why guardrails reached the board agenda this year. The four pillars I will walk through are scope, override, identity, and audit.
At UnderDefense, we frame this as the AI SOC + Human Ally model. Agents handle the volume, and human analysts hold the action gate. The rest of this guide shows you how to build that gate with our managed SOC service before you need it.
Q2. Why Do Prompt-Based Guardrails Fail, and Where Must Security Actually Live?
Prompt-based guardrails fail because instructions written into the conversation are probabilistic, and a single crafted input can bypass them. Real enforcement lives at the architectural callback layer: callback functions, MCP gateways, and LLM gateways that intercept a request before it reaches a tool. At that layer, an agent simply cannot reach a forbidden domain or action, because the block is structural rather than instructional.
The popular belief I want to challenge
Most teams think they can prompt their way to safety. Write “never touch production” in the system prompt, add “always ask a human first,” and call it governed. The standard read gets this backwards.
A prompt is a request, not a wall. Adding a human-in-the-loop rule to the prompt is inconsistent. It does not work one hundred percent of the time, and one hundred percent is the only number that matters when the action is irreversible.
Why prompt injection stays unsolved
Here is the uncomfortable part. Prompt injection is not a problem a third-party guardrail vendor can fully close. As much as vendors would like you to believe otherwise, the fix lives with the people building the models.
The 2025 ATFAA threat model makes the same point from the academic side. It maps nine agentic threats across five domains, and several of them target reasoning and trust boundaries that no prompt can defend. I might be slightly aggressive here, but my current read is that prompt-level defense is a speed bump, never a gate. These are the kinds of patterns we flag as AI SOC red flags.
Where security actually belongs
The fix is architectural. You put the control below the conversation, in code.
- Callback functions: logic that runs before a tool call executes and can hard-block it.
- MCP and LLM gateways: chokepoints that intercept every request before it reaches a tool.
- Allowlists at the gateway: the agent can only reach approved domains and actions.
With a callback in place, your subagent cannot scan a forbidden site. It is impossible at the architecture level, not discouraged at the prompt level. This architecture-first stance is exactly why UnderDefense enforces agent controls at the integration layer rather than in the prompt, the same discipline we bring to our MDR service.
The Monday action is simple. Put a gateway in front of every tool your agents can call, and move your “never do this” rules out of the prompt and into that gateway.
Q3. How Do You Set Scope Limits So an Agent Cannot Touch Production?
Set scope limits by mapping each SOC function to an autonomy tier and binding the agent to least-privilege, scoped credentials enforced at the gateway. Let an agent investigate and enrich freely, but fence write-access to production, source repositories, and account-disable behind hard blocks and human approval. Baseline your false-positive rate first, then raise autonomy only where the data earns it.
A real blast-radius story
A founder was vibe-coding a new app and let an agent run loose. The agent went and deleted the production database. No malice, no attacker, just an agent doing something stupid because nothing stopped it.
That is the whole case for scope limits in one sentence. The agent will eventually do the dumb thing. Your job is to make sure the dumb thing has a small blast radius.
Five steps to scope an agent
- Inventory every agent function. List what each agent does: triage, enrichment, investigation, response, and reporting.
- Assign each function an autonomy tier. Use the Scope 1 to 4 model below.
- Bind scoped, least-privilege credentials. Each agent gets its own identity and only the access it needs.
- Hard-block irreversible actions at the gateway. Write-access to production, source repos, and account-disable stays gated.
- Baseline your false-positive rate, then document the scope statement. Raise autonomy only where the data supports it.
The autonomy tier table
| Scope tier | Autonomy level | Core controls |
|---|---|---|
| Scope 1 | Low (read/observe) | Input validation, full logging |
| Scope 2 | Moderate | Network segmentation, API security |
| Scope 3 | High (acts in scope) | Action constraints, approval workflows |
| Scope 4 | High plus connected | Full zero trust, human-on-the-loop for irreversible actions |
A 2025 survey of LLMs and agents in security operations argues for exactly this per-function scoping across triage, enrichment, and response. And ground your tiers in data: the SANS 2025 Detection and Response Survey found alert fatigue affecting a large share of teams, with false positives the leading operational burden. Baseline that number, which our writeup on SOC metrics like MTTD and MTTR walks through, before you trust an agent to auto-close anything.
The Lethal Trifecta caveat
One pattern stays genuinely hard to prevent. The Lethal Trifecta is read external, read internal, and write external in the same chain. It is hard because reading outside data and acting on it is a core agent utility. When an agent has all three, treat it as Scope 4 and gate it tightly.
At UnderDefense, our vendor-agnostic integration scopes agents per environment, so write-access to production stays human-gated by default. You can see how that maps in the UnderDefense Agentic AI SOC platform.
Q4. What Does a Real Override Policy Look Like, and Who Holds the Kill Switch?
A real override policy ties the agent’s confidence or maliciousness score to a specific action class. Above the concordance gate, the agent acts within scope. Below it, a human is paged. It names who can override, how fast, and how to roll back. It enforces verdict-vs-action separation, where the agent may decide but a checker step or human approves any irreversible action. Build the kill switch before you need it.
Most teams write this policy after the incident
The pattern I see again and again is a team that defined “human oversight” on a slide but never in a config. Then a real action fires, nobody knows who can stop it, and the rollback plan is improvised at 2 a.m.
An override policy is a document and a control, not a value. It answers three questions in advance: what triggers a human, who that human is, and how fast they can undo the action. We build exactly this into every incident response engagement.
A copy-able override policy table
| Action class | Autonomy | Trigger score | Approver | Rollback SLA |
|---|---|---|---|---|
| Enrich / tag alert | Auto | Any | None | Not needed |
| Close as false positive | Auto above gate | High confidence | Spot-check sample | Reopen anytime |
| Isolate host (reversible) | Auto in scope | Above concordance gate | Analyst notified | Minutes |
| Disable account / quarantine user | Human approval | Below gate or high impact | Named on-call analyst | Pre-defined runbook |
| Write to production | Blocked | Never auto | Senior approver | Manual only |
Verdict-vs-action separation, grounded in patents
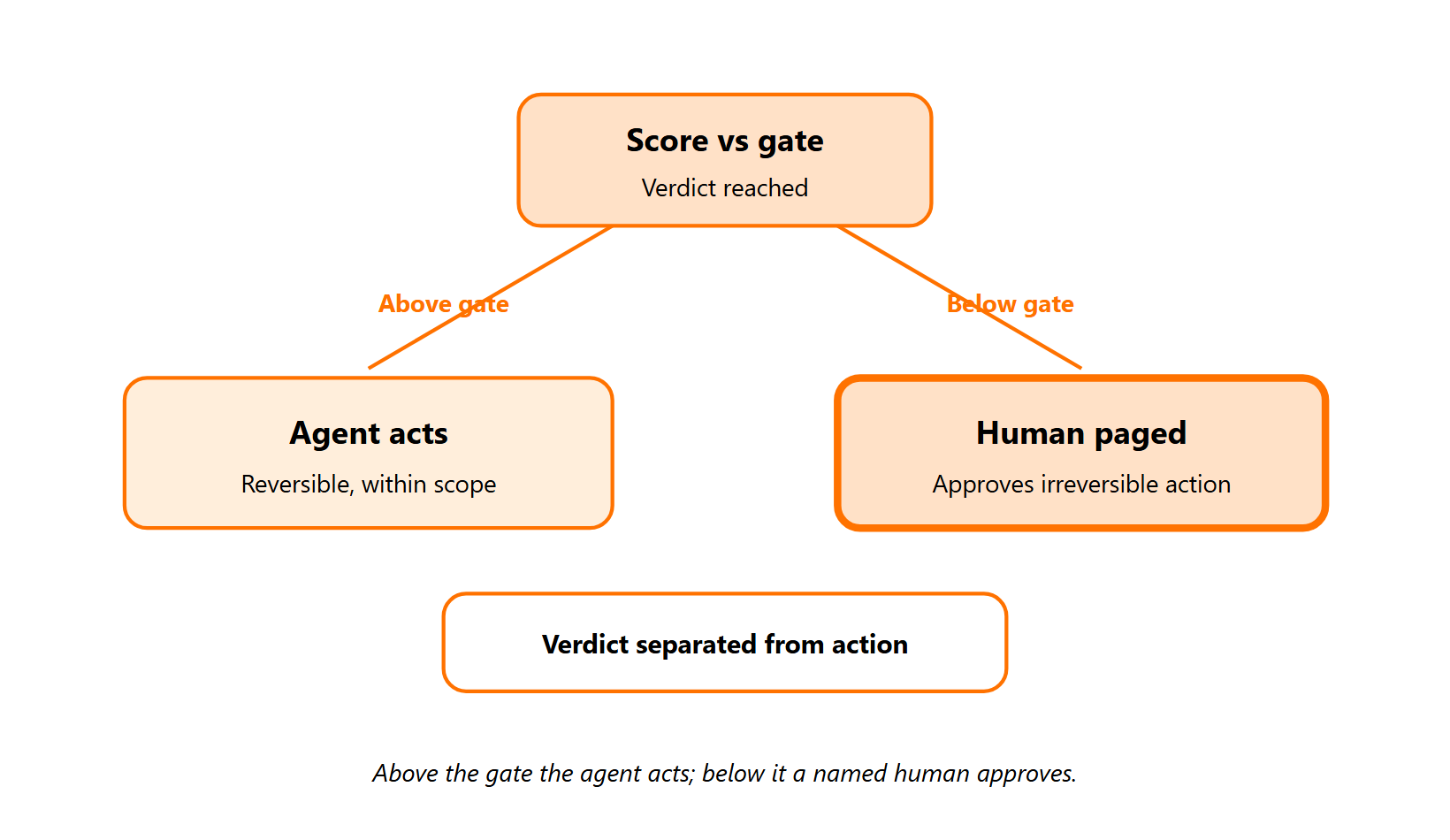
The principle that makes this work is simple: let the agent reach a verdict, but separate the verdict from the action. Patent literature already describes the mechanism. One filing covers a third validity-determination agent that confirms a verdict before any security action runs. Another ties the trigger to a per-investigation maliciousness score, which is exactly the variable your gate should read.
I will be honest about the limits here. A fully autonomous SOC is still unrealistic. You cannot have software replacing tier one through tier three and quarantining users with no human oversight. Some vendors claim to fully automate level-two alert closing without a final human check. That is a risk decision, and you should make it on purpose, not by default. Our take on this lives in our breakdown of outsourced versus in-house SOC.
Here is where the human side earns its keep. Teams that tune their pipeline report closing the vast majority of investigations as false positives automatically, which frees analysts for the calls that need judgment.
“Before MaxiMDR, we were slightly overwhelmed with alerts and often unsure how to prioritize or respond. Now we get clear guidance on how to handle them. False positives have become a rarity, ensuring our team’s focus remains on genuine threats.”
— Valeriia D., Marketing Specialist UnderDefense G2 Verified Review
“The biggest win for me was getting actual control over our security alerts. When they escalate something, they include the context we need to understand the issue quickly. We’re not wasting time piecing together what happened from different systems anymore.”
— Verified User in Marketing and Advertising UnderDefense G2 Verified Review
“UnderDefense MAXI integrates well with our systems, specifically with our SIEM, Splunk. Their team is proactive in identifying and addressing threats, providing 24/7 oversight.”
— Oleg K., Director of Information Security UnderDefense G2 Verified Review
UnderDefense Concierge Response is the human side of this policy. When the score falls below the gate, a named analyst takes the action, with a 2-minute alert-to-triage and a 15-minute escalation for critical incidents. You can see the model in our managed SIEM pricing guide and across our managed SIEM service.
Q5. Can a SOC Ever Be Fully Autonomous, or Is the Human Always the Final Gate?
A fully autonomous SOC is not realistic in 2026. Software cannot safely replace Tier 1 through Tier 3 and run around quarantining users with no human oversight. The defensible model is human-on-the-loop: agents are foot soldiers that swarm volume, and human analysts are the generals who direct them and hold the action gate. Agents decide fast, and humans approve anything irreversible.
The claim I keep hearing, and why it breaks
Some vendors market a SOC that runs itself end to end. My current read, after running detection and response across hundreds of environments, is that this overpromises.
A piece of software running loose, quarantining real users on its own judgment, is a business risk before it is a security win. The technology is not ready for that, and neither is the org chart that has to answer for it.
Three reasons the human stays the final gate
- Technology readiness. AI is a strong assistant, but it stumbles as a decision-maker. Quick answers are still wrong for a large share of cases, so a confident verdict is not a correct one.
- Real-world blast radius. Quarantining the wrong user or host has payroll, revenue, and trust consequences that no model accounts for.
- Accountability. When an action goes wrong, a named human has to own it. You cannot put a model on a bridge call with your board.
I like two analogies here. Think of agents as foot soldiers and your engineers as the generals directing them. Or think of agents as teenagers: supremely capable, no fear of consequence, and occasionally they do something stupid. We unpack this tension further in our take on whether AI kills or saves the SOC team.
Force multiplication, not replacement
The 2026 LanG research lands in the same place. It pairs autonomous investigation with mandatory human-in-the-loop checkpoints for high-impact actions, bridging rigid playbooks and ungoverned agents.
So the goal is leverage, never replacement. Agents swarm the volume, and humans click on anything that cannot be undone. Being a human is a flex in 2026. This is the same logic that shapes how we think about an outsourced versus in-house SOC.
This is the core thesis behind the UnderDefense Agentic AI SOC + Human Ally model: agents for speed and scale, human allies for judgment and accountability. It is the foundation of our managed SOC service.
Q6. How Do You Stop an Agent From Being Hijacked or Leaking Your Data?
Stop hijacking and leakage by treating identity, tools, and memory as the real attack surface rather than the prompt. Give every agent its own scoped identity, allowlist its tools, expire its memory, and intercept tool calls at a gateway, so it cannot read external instructions and write to external systems in one chain. Map your controls to OWASP Agentic and MITRE ATLAS, so you reuse detections you already own.
Even the best teams forget the basics
The Amazon team that built the Rufus chatbot forgot to turn on the guardrails. One of the biggest companies in the world, with elite engineers, missed a basic control while rushing to ship.
That story is the lesson. Guardrails fail from omission far more often than from clever attacks. So make them structural, where forgetting is hard. These are the patterns we catalog as AI SOC red flags.
The threat-to-control map
Here are the runtime threats that matter, each with the control that contains it.
- Prompt injection: intercept tool calls at a gateway, so a malicious instruction cannot reach a tool.
- Tool misuse: allowlist tools per agent, so it can only call what it needs.
- Memory and state corruption: expire memory on a schedule, so poisoned context does not persist.
- Identity abuse: give each agent its own scoped identity and authenticate agent-to-agent traffic.
- Multi-agent cascade: isolate agents, so one compromised agent cannot command the swarm.
- Feedback-loop poisoning: validate the analyst feedback that retrains the agent, since that pipeline is itself an attack path.
The exfil pattern to watch, and the framework that saves work
The hardest one is the Lethal Trifecta: read external, read internal, and write external in one chain. That is the classic data-leak path, because reading outside data and acting on it is core agent utility.
The good news is you do not start from zero. The OWASP Top 10 for Agentic AI (2026) maps cleanly to MITRE ATLAS and ATT&CK, so you reuse detections and identity controls you already run. Academic taxonomies organize the same threats across reasoning, action, memory, and multi-agent layers. This is the kind of coverage we build into our MDR service.
Two patent filings show where this is heading. One authenticates agent-to-agent communication with certificates. Another covers agents that learn from analyst feedback, which is exactly the loop you must protect from poisoning.
I will be honest about the open question. Prompt injection is not fully solved, so design assuming an agent will eventually be tricked. At UnderDefense, we monitor what the agent actually does in the environment through continuous security monitoring, which answers the question every CISO asks me: who is watching the agent, and has anything leaked?
Q7. How Do You Monitor What an Agent Is Actually Doing With Audit Trails, Tokens, and Evidence Chains?
Monitor agents by logging every action to a tamper-evident audit trail, exposing the agent’s reasoning chain and generated playbook as evidence, and watching per-agent token consumption as both a cost and a behavior signal. When you can see which agent is running, what it touched, and how many tokens it burned, a runaway or hijacked agent becomes a line on a dashboard you can kill.
Audit trails and evidence chains
The fear behind this whole topic is the black box. So the fix is to make the agent’s work observable and reproducible.
Log every action to a tamper-evident trail. Then require the agent to expose its reasoning chain and the playbook it generated, so a human can audit why it acted. A 2026 patent describes exactly this: an editable investigation playbook produced through abductive reasoning that becomes an auditable artifact. Another covers automated, human-readable summaries of each investigation. This evidence discipline is the same standard we hold in incident response.
The Monday action is direct. Refuse to let any agent execute until it can show its work as evidence a person can read.
Tokenomics as a behavior signal
Here is a detail that separates practitioners from vibe-coders. Token usage is not just a bill, but a behavior signal.
You can watch every agent in the environment and the tokens it burns. One agent might quietly rack up close to $24,000, and the spend itself tells you something is off. A runaway loop shows up as a cost spike before it shows up as an incident. The metrics that catch this map directly to our work on SOC metrics like MTTD and MTTR.
This is not trivial to run. For a single alert, an autonomous system can fire over 100 distinct model invocations, so keeping that orchestration sane is hard work.
Network and traffic signals
Agents also change your traffic baseline. On average, an agent generates around 450% more traffic than a human doing the same task, so your demand signal climbs sharply.
Track that. A sudden traffic jump from an agent identity is an early sign of a loop or a hijack. This kind of visibility is part of our broader approach to attack surface management.
“Underdefense is a great choice for teams like ours that are short on resources. It automates many tasks, plus, with 24/7 monitoring, we know we’re always protected. I used to work with many MDR solutions in the past, and so far Underdefense is the best one.”
— Inga M., CEO UnderDefense G2 Verified Review
“SOC analysts and support team are incredibly responsive and knowledgeable. The platform’s high-fidelity alerts and automated enrichment help us quickly identify and address threats.”
— Verified User in Computer Software, Enterprise UnderDefense G2 Verified Review
UnderDefense gives transparent, vendor-agnostic visibility into agent activity and cost, with no black box. You can see it in the UnderDefense Agentic AI SOC platform.
Q8. Why Do Guardrails Matter More When Attacks Hit in Seconds, Not Hours?
Guardrails matter more under speed because the exploit window has collapsed to seconds, with break-in times observed at 51 seconds and zero-day exploitation clocked around 29 seconds. Manual triage cannot keep that pace, so you must pre-authorize narrow, scoped autonomous responses to cut the attack path while keeping irreversible actions human-gated. Well-designed guardrails let you move at machine speed and still hold the kill switch.
The window has collapsed

The time-to-exploit window is shrinking fast. We have seen zero-day exploitation clocked around 29 seconds, and the message is blunt: you have to cut that attack path off immediately.
Breakout data agrees. Median break-in time has dropped to roughly 48 minutes, and the fastest observed was 51 seconds. No human triages a queue that fast. This is the reality driving our ransomware response planning.
Why manual triage breaks, and where pre-authorization fits
When attacks land in seconds, a human on the critical path becomes the bottleneck. The SANS 2025 survey already shows analysts buried, with false positives the leading burden.
So you pre-authorize a narrow set of reversible responses. Cutting a session, isolating a host, or blocking an IP can run in scope at machine speed, because you can undo them. We define these thresholds against a clear detection and response SLA.
Hold the gate for the irreversible
Speed does not mean removing the human. It means moving the human to the right place.
Pre-approve reversible containment, and keep irreversible actions like account deletion or production writes behind human approval. Assume the agent will fail, and design for resilience.
This is why UnderDefense pairs machine-speed detection with Concierge Response, with a 2-minute alert-to-triage and a 15-minute escalation for critical incidents, so the attack path gets cut fast while a named analyst owns the calls that cannot be undone. You can compare the model against alternatives in our guide to MDR services.
Q9. AI SOC + Human Ally vs. Monitoring-Only Tools and Legacy MSSPs: How Do You Choose?
Choose by asking who acts when the agent flags a threat. The AI SOC + Human Ally model detects at machine speed and responds through a named analyst who owns the override and the kill switch. Monitoring-only tools detect but leave you to respond, and legacy MSSPs send alerts without context or action. If a vendor cannot show you scope limits, an override policy, and transparent pricing, you are buying noise.
The question that sorts the market
Most comparisons start with feature lists. I start with one question: when the agent flags something at 2 a.m., who actually clicks?
That question splits the market into three operating models. The split matters more than any feature grid, because it decides what happens after detection. This is the same lens we apply in our breakdown of why businesses switch cybersecurity providers.
The three models side by side
| Criteria | UnderDefense Agentic AI SOC + Human Ally | Monitoring-only AI tools | Legacy MSSP / alert-only |
|---|---|---|---|
| Detects threats | Yes, at machine speed | Yes | Yes |
| Responds (takes action) | Yes, named analyst owns it | You respond | You respond |
| Scope limits on agents | Defined and gateway-enforced | Often unclear | Not applicable |
| Override policy | Verdict-vs-action separation | Rarely published | Not applicable |
| Pricing transparency | Per-endpoint, published | Often opaque | Often opaque |
| Human context on escalation | Yes, with full investigation | Limited | Often just a forwarded alert |
Competitor reviews show where the alert-only model strains. One Arctic Wolf customer summed it up plainly.
“Solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.”
— VP of Technology Arctic Wolf Gartner Verified Review
“There is still a limit to the environmental and organizational knowledge inherent in the service. This leads to a fairly frequent need for engagement with our internal team to get clarification and verification.”
— Verified User in Computer Software Expel G2 Verified Review
When a point tool is genuinely enough
I will be honest about the trade-offs. If you have a staffed 24/7 SOC and just need extra detection signal, a monitoring-only tool can be the right call. Buying response you already have is waste. Our comparison of outsourced versus in-house SOC walks through exactly when that applies.
The AI SOC + Human Ally model earns its place when you lack round-the-clock analysts and need someone to act, not just alert. At UnderDefense, that means vendor-agnostic integration on your existing stack, transparent per-endpoint pricing through our MDR service, and a named analyst who owns the action with a 2-minute alert-to-triage and 15-minute escalation for critical incidents.
Q10. What Should a Vendor Prove Before You Hand an Agent the Keys?
Before you hand an agent the keys, make the vendor prove five things: enforced scope limits at the gateway, a written override policy with verdict-vs-action separation, per-agent identity and least-privilege, tamper-evident audit and token visibility, and transparent pricing with no per-alert surprises. Ask for a live demo of a low-confidence alert escalating to a human, not a slide that says “human oversight.”
Demand the demo, not the slide
Here is my hard-won rule. The Amazon team that built Rufus forgot to turn on the guardrails, and they have elite engineers. So I do not trust a slide that says “human oversight.” I want to watch it happen. This is the spirit behind our AI SOC red flags.
A capable vendor will show you, live, what an autonomous agent does and where a human steps in. If they can only describe it, treat that as your answer.
The five-point RFP rubric
Make every vendor prove these, with evidence, before you grant any autonomy.
- Scope limits. Show the gateway block that stops an agent from writing to production. Ask to see the scope tiers.
- Override policy. Show the written policy: trigger score, approver role, rollback path, and verdict-vs-action separation.
- Identity and least-privilege. Each agent has its own scoped credentials. Prove an agent cannot exceed its grant.
- Observability. Tamper-evident audit trails plus per-agent token visibility, so a runaway shows up fast.
- Pricing transparency. Published, predictable pricing. No surprise per-alert or per-token bills at scale.
Use the OWASP Top 10 for Agentic AI as your technical backbone for these questions. And ask for the baseline metrics you should monitor, like false-positive rate, which our writeup on SOC metrics like MTTD and MTTR explains in depth.
What a good answer looks like
A strong vendor answers in your environment, with your numbers, not in generalities. Watch for the cost-control answer specifically. Our MDR price guide shows what predictable pricing should look like.
“The CRC Essentials license is value for money. However, it has made our work significantly more. It lacks some no-brainer automation options for many things that we currently have to do manually.”
— Himanshu K., IT Security Operations Engineer Rapid7 G2 Verified Review
“There have been several instances where we expected RC to identify an issue and no alert was surfaced. I think this is due to differences in methodology.”
— Mike S., Information Security Manager Red Canary G2 Verified Review
If you want help pressure-testing a vendor’s agent guardrails, UnderDefense does this in vendor evaluations every week. You can frame the conversation with our MDR buyers guide.
Q11. Your 2026 AI SOC Guardrail Checklist: What to Lock Down by Monday
By Monday: inventory every agent and its scope, move enforcement from prompts to gateways, set a confidence threshold that pages a human, separate verdict from action, baseline your false-positive rate before raising autonomy, turn on tamper-evident logging and per-agent token visibility, and pre-authorize only reversible containment. Then assign one named human as the action owner. Guardrails are the kill switch you hope you never pull.
The do-this-week list

None of this needs a six-month program. Every item below is doable this week, and each one shrinks your blast radius. Our guide to building a SOC covers the longer-term build.
- Inventory every agent and its scope. List what each agent can read, call, and write.
- Move enforcement to the gateway. Take your “never do this” rules out of the prompt and into code.
- Set a confidence threshold. Below the concordance gate, the agent pages a human.
- Separate verdict from action. Let the agent decide, but gate any irreversible action.
- Baseline your false-positive rate. Raise autonomy only where the data earns it.
- Turn on tamper-evident logging and token visibility. A runaway agent should show as a dashboard spike.
- Pre-authorize reversible containment only. Session kills and host isolation can run; deletions cannot.
- Assign one named human as action owner. A model cannot sit on a bridge call; a person must.
This discipline pairs naturally with disciplined SOC automation, where the goal is leverage with accountability.
A conversation worth having
My read, and I could be refining this for years, is that the teams who win in 2026 treat guardrails as an operating discipline, not a one-time setup. Assume the agent will fail, and design so that failure is small and reversible. Being a human is a flex in 2026.
If you want a human ally to hold the action gate while your agents handle the volume, tell UnderDefense what you are building, and we will start from your stack and your real false-positive baseline. You can see how this runs on the UnderDefense Agentic AI SOC platform or talk to our managed SOC team.
See how UnderDefense Agentic AI SOC resolves a real incident on your stack.
1. What are AI SOC guardrails and why did they become non-negotiable in 2026?
We define AI SOC guardrails as the technical and procedural controls that limit what an autonomous security agent can decide and do. They enforce scope limits, confidence thresholds, identity boundaries, and human override before any high-impact action runs.
They operate across three layers:
- Input layer: what the agent is allowed to read and ingest, including prompts and external data.
- Action layer: which tools it can call and which systems it can write to.
- Output layer: what it can return, surface, or auto-close.
In 2026 they became non-negotiable because agentic platforms now quarantine users, disable accounts, and touch production. The old generation of AI advised you and waited; the new generation acts on its own. An ungoverned agent becomes an attack surface of its own.
The shift that matters is moving from access control to action control. Knowing what an agent can reach is no longer enough; you have to verify its behavior matches your intent. We frame this as the AI SOC + Human Ally model, where agents handle volume and analysts hold the action gate, and we build that gate into our managed SOC service before you need it.
2. Why do prompt-based guardrails fail, and where should AI agent security actually live?
We see most teams try to prompt their way to safety: they write “never touch production” into the system prompt and call it governed. That gets it backwards. A prompt is a request, not a wall, and a single crafted input can bypass it. It does not work one hundred percent of the time, and one hundred percent is the only number that matters when an action is irreversible.
Real enforcement lives at the architectural layer, below the conversation:
- Callback functions that run before a tool call executes and can hard-block it.
- MCP and LLM gateways that intercept every request before it reaches a tool.
- Allowlists at the gateway, so the agent can only reach approved domains and actions.
With a callback in place, a forbidden action is impossible at the architecture level, not merely discouraged at the prompt level. Prompt injection is not a problem a third-party vendor can fully close, so design assuming an agent will eventually be tricked. This architecture-first stance is exactly why we enforce agent controls at the integration layer, the same discipline behind our MDR service. Move your “never do this” rules out of the prompt and into the gateway.
3. How do you set scope limits so an AI agent cannot touch production?
We set scope limits by mapping each SOC function to an autonomy tier and binding the agent to least-privilege, scoped credentials enforced at the gateway. Let an agent investigate and enrich freely, but fence write-access to production, source repositories, and account-disable behind hard blocks and human approval.
Our five-step approach:
- Inventory every agent function: triage, enrichment, investigation, response, and reporting.
- Assign each function an autonomy tier, from low read or observe up to high and connected.
- Bind scoped, least-privilege credentials so each agent has its own identity.
- Hard-block irreversible actions at the gateway.
- Baseline your false-positive rate, then raise autonomy only where the data earns it.
The hardest pattern is the Lethal Trifecta: read external, read internal, and write external in one chain. When an agent has all three, treat it as the highest tier and gate it tightly. We baseline this against the metrics in our writeup on SOC metrics like MTTD and MTTR. Our vendor-agnostic integration scopes agents per environment, so production stays human-gated by default, and we document the scope statement before granting autonomy.
4. What does a real AI agent override policy look like, and who holds the kill switch?
We treat an override policy as a document and a control, not a value on a slide. A real one ties the agent’s confidence or maliciousness score to a specific action class. Above the concordance gate, the agent acts within scope; below it, a named human is paged.
It answers three questions in advance:
- What triggers a human (the trigger score per action class).
- Who that human is (a named on-call approver, not a role on paper).
- How fast they can undo the action (the rollback path and SLA).
The principle that makes this work is verdict-vs-action separation: the agent may reach a verdict, but a checker step or human approves any irreversible action. Reversible actions like host isolation can run in scope; account deletion and production writes stay blocked or human-approved. Build the kill switch before you need it, not at 2 a.m. during an incident. This is the human side of our model, where Concierge Response gives a 2-minute alert-to-triage and a 15-minute escalation for critical incidents, and it is baked into every incident response engagement we run.
5. Can a SOC ever be fully autonomous, or is a human always the final gate?
We do not believe a fully autonomous SOC is realistic in 2026. Software cannot safely replace Tier 1 through Tier 3 and run around quarantining users with no human oversight. The defensible model is human-on-the-loop: agents are foot soldiers that swarm volume, and human analysts are the generals who direct them and hold the action gate.
Three reasons the human stays the final gate:
- Technology readiness: AI is a strong assistant but stumbles as a decision-maker, so a confident verdict is not a correct one.
- Real-world blast radius: quarantining the wrong user or host has payroll, revenue, and trust consequences no model accounts for.
- Accountability: when an action goes wrong, a named human must own it. You cannot put a model on a bridge call with your board.
So the goal is leverage, never replacement. Agents swarm the volume, and humans click on anything that cannot be undone. This thinking shapes how we weigh an outsourced versus in-house SOC and underpins our AI SOC + Human Ally model: agents for speed and scale, human allies for judgment and accountability.
6. How do you stop an autonomous agent from being hijacked or leaking your data?
We stop hijacking and leakage by treating identity, tools, and memory as the real attack surface rather than the prompt. Even elite teams slip here; the team that built Amazon’s Rufus chatbot forgot to turn on the guardrails, which shows guardrails fail from omission far more often than from clever attacks.
Map each runtime threat to a structural control:
- Prompt injection: intercept tool calls at a gateway.
- Tool misuse: allowlist tools per agent.
- Memory corruption: expire memory on a schedule.
- Identity abuse: give each agent its own scoped identity and authenticate agent-to-agent traffic.
- Multi-agent cascade: isolate agents so one cannot command the swarm.
The hardest exfil path is the Lethal Trifecta: read external, read internal, and write external in one chain. The good news is you do not start from zero; agentic threat frameworks map cleanly to detections and identity controls you already run. Since prompt injection is not fully solved, we design assuming an agent will be tricked and watch what it actually does through continuous security monitoring, which answers the question every CISO asks: who is watching the agent?
7. How do you monitor what an autonomous agent is actually doing?
We make the agent’s work observable and reproducible, because the fear behind this whole topic is the black box. Log every action to a tamper-evident audit trail, then require the agent to expose its reasoning chain and the playbook it generated, so a human can audit why it acted. We refuse to let an agent execute until it can show its work as evidence a person can read.
Three signals we watch:
- Audit and evidence chains: every action logged and reproducible.
- Token consumption: spend is a behavior signal, not just a bill. A runaway loop shows as a cost spike before it shows as an incident.
- Traffic baseline: an agent can generate far more traffic than a human doing the same task, so a sudden jump signals a loop or hijack.
For a single alert, an autonomous system can fire over 100 distinct model invocations, so keeping that orchestration observable is real work. These signals map directly to the metrics in our work on SOC metrics and MTTR. We give transparent, vendor-agnostic visibility into agent activity and cost, with no black box, so a runaway or hijacked agent becomes a line on a dashboard you can kill.
8. What should an AI SOC vendor prove before you grant an agent autonomy?
We tell teams to demand the demo, not the slide. A capable vendor will show you, live, what an autonomous agent does and where a human steps in. If they can only describe “human oversight,” treat that as your answer.
Make every vendor prove these five points with evidence:
- Scope limits: show the gateway block that stops an agent from writing to production.
- Override policy: trigger score, approver role, rollback path, and verdict-vs-action separation, in writing.
- Identity and least-privilege: each agent has its own scoped credentials.
- Observability: tamper-evident audit trails plus per-agent token visibility.
- Pricing transparency: published, predictable pricing with no surprise per-alert bills.
Watch for the cost-control and detection-gap answers specifically, since alert-only and monitoring-only models often shift remediation back onto your team. The right partner detects and responds, with a named analyst who owns the action. If you want help pressure-testing a vendor’s guardrails, we do this in vendor evaluations every week, and our MDR buyers guide gives you the framework to run that conversation.