Q1: What Is a Data Breach Incident Response Plan and Why Does Every Organization Need One in 2026?
A data breach incident response plan is a documented, structured framework that defines how an organization prepares for, detects, contains, eradicates, recovers from, and reviews security incidents, covering everything from team roles and communication protocols to forensic procedures and regulatory notification workflows.
⚠️ The Numbers That Should Keep You Up at Night
The financial stakes have never been higher. IBM’s Cost of a Data Breach Report found the global average breach cost hit a record $4.88 million in 2024, a 10% spike and the largest year-over-year increase since the pandemic. Compromised credentials remained the top attack vector, accounting for 16% of all breaches at an average cost of $4.81 million per incident. Meanwhile, the 2025 Verizon DBIR analyzed over 12,000 confirmed breaches and documented a critical shift: vulnerability exploitation overtook phishing as the second most common initial access method, with 20% of breaches beginning through exploited vulnerabilities, a 34% increase year over year.
Here’s what makes the gap between prepared and unprepared organizations so stark: organizations with high levels of security staffing shortages, now up 26.2%, faced an average of $1.76 million more in breach costs. The difference between having an IR plan that your team can actually execute and having a PDF that collects dust in SharePoint is, quite literally, millions of dollars and months of recovery time.
⏰ Why 2026 Is a Regulatory Inflection Point
Multiple regulatory shifts are converging simultaneously, and each one compresses the timeline organizations have to respond:
- NIST SP 800-61 Rev 3 (released April 2025) eliminates the rigid incident lifecycle model in favor of continuous, business-aligned functions mapped to CSF 2.0: Govern, Identify, Protect, Detect, Respond, and Recover
- SEC 4-business-day disclosure rules require public companies to report material cybersecurity incidents within four business days of determining materiality, not four days from detection, but from the judgment call that it’s material
- India’s DPDP Act officially commenced enforcement in November 2025, mandating 72-hour breach notification to the Data Protection Board and requiring “reasonable security safeguards” including encryption and access controls
- AI-powered attack sophistication continues to outpace static defenses, with threat actors using generative AI for phishing, social engineering, and automated vulnerability scanning at scale
Each of these regulations assumes you have a working IR plan, not a theoretical one. Auditors, boards, and regulators are no longer asking “do you have a plan?” They’re asking “show me the last time you tested it, and show me the metrics.”
✅ How UnderDefense Operationalizes Your IR Plan
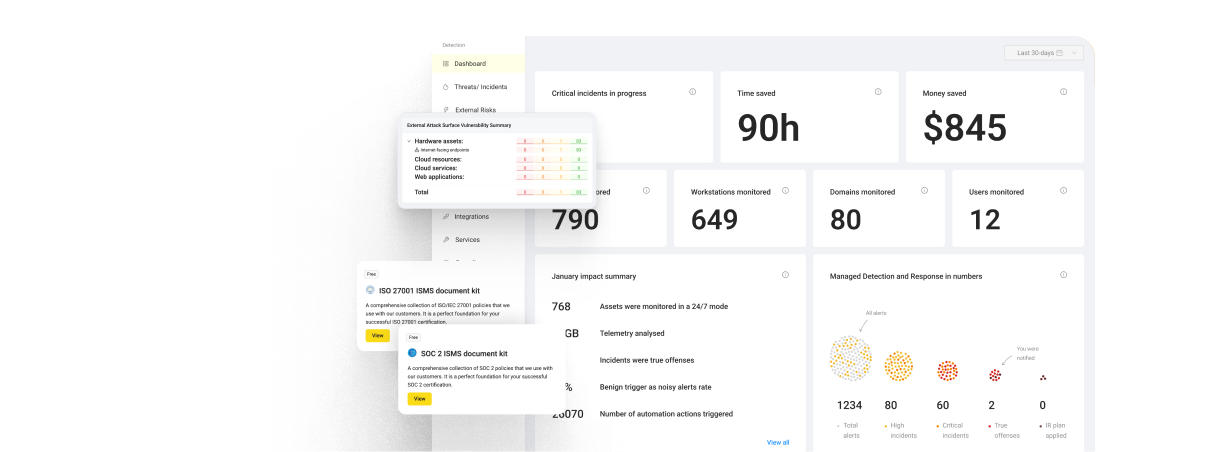
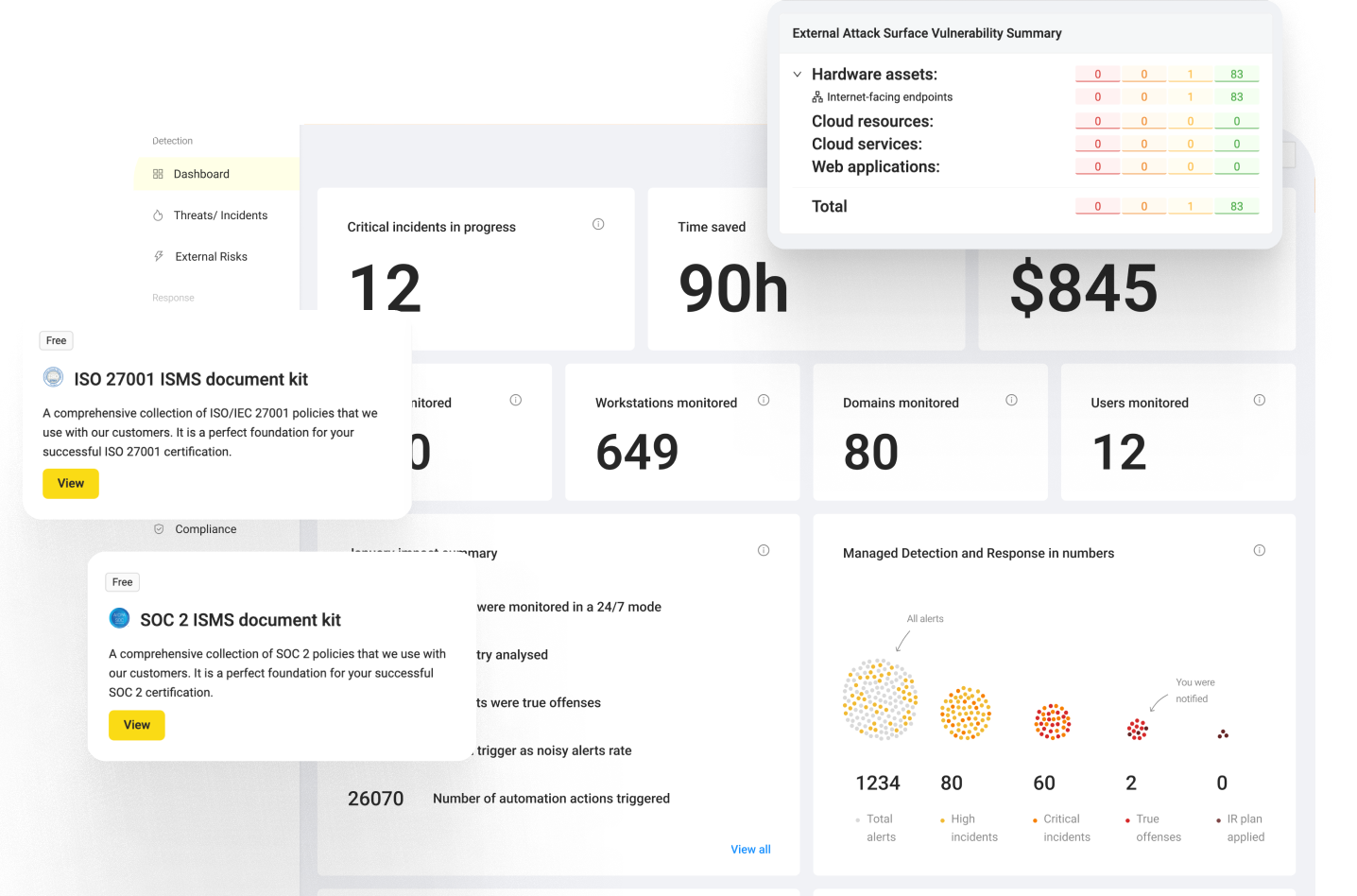
The UnderDefense MAXI platform helps organizations move from documented plans to executable workflows through AI-powered detection, automated playbook execution, and 24/7 concierge analyst response. Rather than handing you a dashboard and wishing you luck, we operationalize the plan, with documented response times of 2-minute alert-to-triage and 15-minute escalation for critical incidents, plus integration across 250+ existing security tools so nothing falls through the cracks between your SIEM, EDR, and cloud consoles.
Q2: What Are the Core Phases of a Data Breach Incident Response Plan?
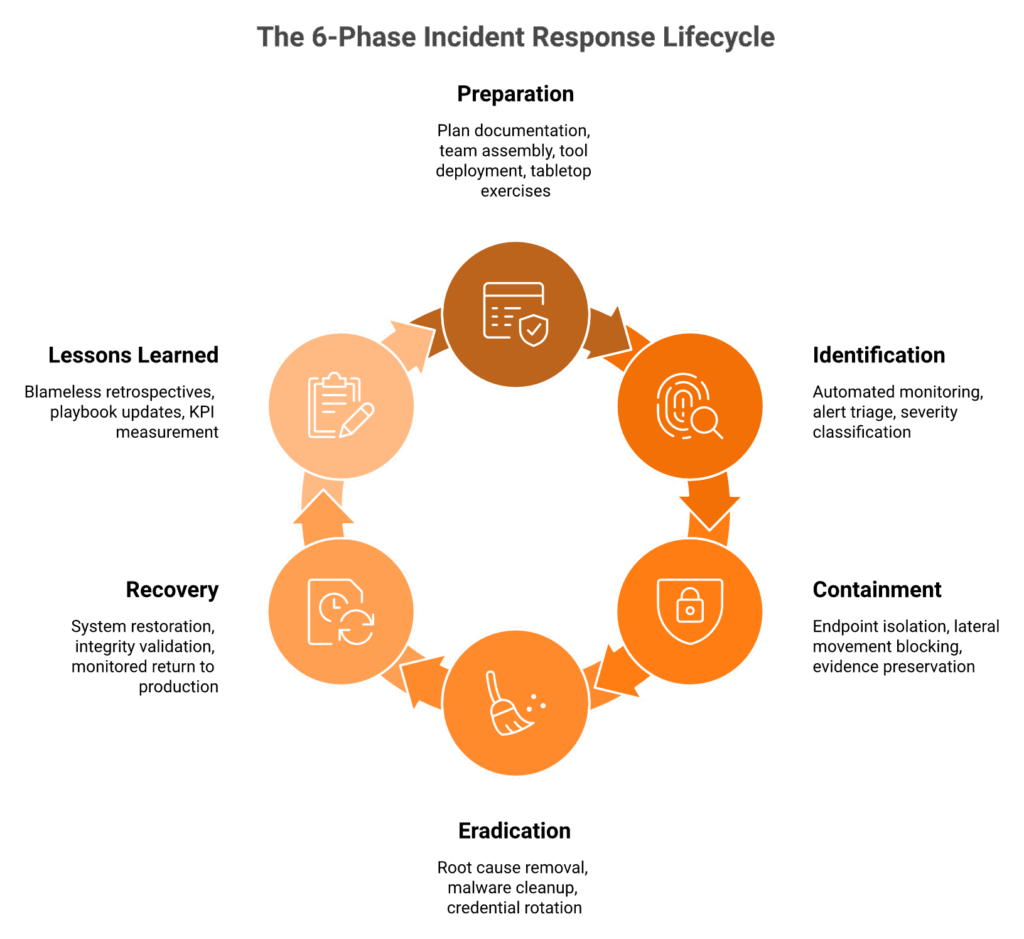
Two dominant models define how organizations structure incident response, and understanding both matters because your auditors and regulators reference them interchangeably. The SANS 6-phase lifecycle follows a sequential path: Preparation → Identification → Containment → Eradication → Recovery → Lessons Learned. NIST SP 800-61 Rev 3, released in April 2025, takes a different approach. It maps incident response to the six CSF 2.0 functions (Govern → Identify → Protect → Detect → Respond → Recover) and deliberately eliminates the rigid lifecycle in favor of a continuous, flexible process that integrates with overall risk management.
The practical difference: SANS gives you a step-by-step playbook. NIST Rev 3 gives you an operating model. Most mature organizations use both, SANS for operational execution, NIST for governance alignment and audit readiness.
🔧 Phase 1: Preparation, the Workhorse Phase
This is where 80% of your IR success is determined, and it happens long before any incident. Preparation includes:
- IR plan documentation with defined roles, escalation paths, and communication protocols
- Team assembly and 24/7 contact trees
- Tool deployment and integration (SIEM, EDR, IDS, cloud monitoring)
- Tabletop exercises and adversary simulation (at minimum, quarterly)
- Asset inventory and critical data classification
- Pre-negotiated retainer agreements with forensics firms and legal counsel
🔍 Phase 2: Identification and Detection
Automated monitoring through SIEM correlation rules, EDR behavioral analysis, and IDS signatures forms the first detection layer. The critical work here is initial severity classification and reducing false positives, because a team drowning in noise will miss the real threat. This is where alert triage efficiency directly determines whether a P1 ransomware event gets caught in 2 minutes or buried under 500 low-priority alerts.
Phase 3: Containment (Short-term and Long-term)
Short-term containment focuses on stopping the bleeding: isolating affected endpoints, blocking lateral movement, and revoking compromised credentials. Long-term containment preserves forensic evidence while keeping business operations running. Think network segmentation, temporary access controls, and monitored honeypots.
Phase 4: Eradication
Remove the root cause entirely: malware payloads, backdoors, compromised accounts, and persistence mechanisms. This is where teams often rush and miss artifacts. A single overlooked scheduled task or registry key means the attacker comes back.
Phase 5: Recovery
Restore systems from verified clean backups, validate data integrity, and gradually return to production. Monitor recovered systems with heightened alerting thresholds for at least 30 to 60 days post-incident.
📝 Phase 6: Lessons Learned and Post-Incident Review
Conduct blameless retrospectives within 72 hours while details are fresh. Update playbooks, file compliance documentation, and measure KPIs: MTTD (Mean Time to Detect), MTTR (Mean Time to Respond), and containment time.
| SANS Phase | NIST CSF 2.0 Function | Key Activities |
|---|---|---|
| Preparation | Govern, Identify, Protect | Plan documentation, team assembly, tool deployment, tabletop exercises |
| Identification | Detect | Automated monitoring, alert triage, severity classification |
| Containment | Respond | Endpoint isolation, lateral movement blocking, evidence preservation |
| Eradication | Respond | Root cause removal, malware cleanup, credential rotation |
| Recovery | Recover | System restoration, integrity validation, monitored return to production |
| Lessons Learned | Govern, Identify | Blameless retrospectives, playbook updates, KPI measurement |
✅ How UnderDefense Automates Phase Transitions
The UnderDefense MAXI platform automates transitions between these phases. AI-driven detection triggers containment playbooks automatically, while concierge analysts execute eradication and recovery steps without escalating back to the client’s team. The result: your IR plan stops being a document and starts being a living system with 2-minute alert-to-triage, 15-minute mean-time-to-contain for critical incidents, and 250+ tool integrations ensuring nothing gets siloed between phases.
Q3: Who Should Be on Your Incident Response Team and What Are Their Roles?
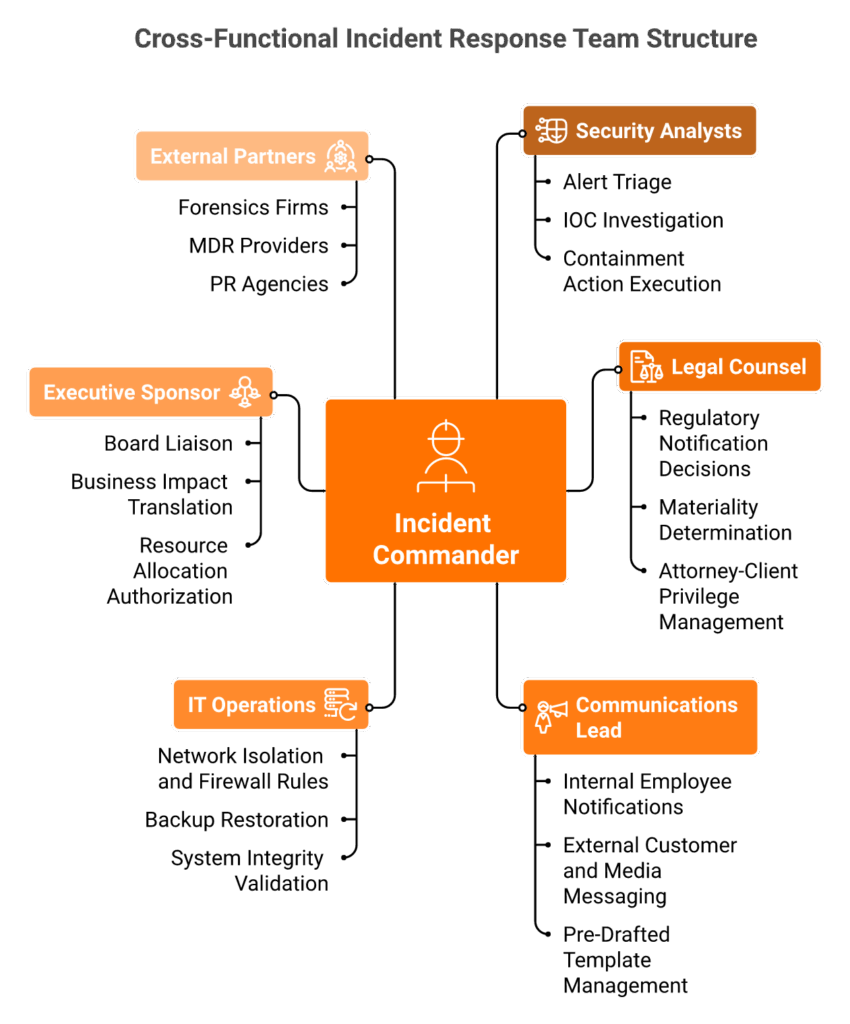
An effective IR team is cross-functional by design, not a security-only function. The biggest mistake I see organizations make is treating incident response as something the security team “owns” while legal, communications, IT operations, and executives show up unprepared when it actually matters. At 2 AM during an active breach, you don’t want the first conversation between your CISO and your General Counsel to be an introduction.
👥 Core IR Team Roles
Incident Commander owns the response end-to-end. Makes containment decisions, authorizes communications, and manages the timeline. This person has authority to override normal change management processes during active incidents.
Security Analysts triage alerts, investigate indicators of compromise, perform forensic analysis, and execute containment actions. They’re the operational backbone.
Legal Counsel makes regulatory notification decisions (GDPR 72-hour, SEC 4-business-day, HIPAA 60-day). Determines materiality, manages attorney-client privilege over forensic reports, and coordinates with outside counsel.
Communications Lead handles internal messaging (employee notifications, board updates) and external messaging (customer notifications, media, regulators). Pre-drafted templates are essential.
IT Operations executes system containment (network isolation, firewall rules), manages backup restoration, and validates system integrity during recovery.
Executive Sponsor serves as the board liaison who translates technical incident status into business impact language. Authorizes resource allocation and strategic decisions.
External Partners include forensics firms, MDR providers, PR agencies, and breach coaches. Pre-negotiated retainer agreements eliminate procurement delays during crisis.
📋 RACI Matrix: Who Does What, When
| IR Phase | Incident Commander | Security Analysts | Legal Counsel | Comms Lead | IT Ops | Executive Sponsor | External Partners |
|---|---|---|---|---|---|---|---|
| Preparation | A | R | C | C | R | I | C |
| Identification | A | R | I | I | C | I | R |
| Containment | A | R | C | I | R | I | R |
| Eradication | A | R | I | I | R | I | R |
| Recovery | A | C | I | C | R | I | R |
| Lessons Learned | A | R | C | C | C | I | C |
R = Responsible, A = Accountable, C = Consulted, I = Informed
⚠️ The 24/7 Coverage Gap
Here’s the operational reality most mid-market organizations face: you need 24/7 analyst coverage, but you can’t staff it. Building an internal SOC with round-the-clock Tier 3–4 analysts requires 8 to 12 FTEs at a minimum. That’s $1.5 to $2.5M annually in a market where security analyst tenure averages 18 months before burnout-driven turnover. This is the critical gap that makes external MDR partnerships not a luxury, but an operational necessity.
Team readiness requirements that often get overlooked include: security clearances for forensics personnel, 24/7 contact trees tested quarterly (not just documented), escalation procedures with defined SLAs at each tier, and pre-negotiated retainer agreements with forensics firms and legal counsel so procurement doesn’t become a bottleneck during an active breach.
✅ How UnderDefense Fills the Gap
UnderDefense serves as the external MDR layer that fills the 24/7 analyst gap, providing Tier 3–4 concierge analysts, forensic investigation support, and direct user verification via ChatOps (Slack, Teams, email). This effectively extends the client’s IR team without headcount expansion. As one G2 reviewer put it:
“UnderDefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection.”
— Inga M., CEO UnderDefense G2 – Verified Review
Q4: How Do You Build Severity-Tiered Playbooks for Different Breach Scenarios?
The One-Size-Fits-All Playbook Problem
Most IR plans treat every incident identically, the same escalation chain fires whether it’s a failed login attempt or active ransomware encryption. I’ve reviewed dozens of IR plans across mid-market companies, and the pattern is consistent: a single runbook, a single escalation path, and a single response speed regardless of severity. This creates two predictable failure modes: over-response to minor incidents (wasting analyst hours on noise) and under-response to critical ones (missing the containment window because the P1 ransomware alert sat in the same queue as 200 P4 policy violations).
❌ Why Static Playbooks Fail at Scale
Traditional MDR providers compound this problem. Arctic Wolf and ReliaQuest deliver the same alert-and-escalate workflow regardless of severity. A P4 suspicious login gets the same ticket as a P1 active data exfiltration. The result: alert fatigue on low-severity noise, and critical incidents buried in the queue. Legacy MSSPs add rigid, pre-defined playbooks that can’t adapt to novel attack patterns or differentiate between a developer running a legitimate script at 2 AM and an attacker using the same tool for lateral movement.
One G2 reviewer of Red Canary captured this frustration well:
“Over the past few years, we’ve undergone several external penetration tests, and during these assessments, Red Canary was not able to identify the malicious activity while the tests were ongoing.”
— Verified User, Insurance Red Canary – G2 Verified Review
📋 The Severity Framework: P1 to P4 Classification
| Severity | Definition | Response SLA | Escalation Trigger | Containment Action |
|---|---|---|---|---|
| ⭐ P1 — Critical | Active data exfiltration, ransomware encryption, confirmed APT activity | 15 min | Immediate Incident Commander activation, board notification within 1 hour | Endpoint isolation, credential revocation, network segmentation, forensic preservation |
| P2 — High | Confirmed unauthorized access, lateral movement detected, BEC compromise | 1 hour | Security Analyst + Legal Counsel engaged | Account suspension, MFA enforcement, affected system quarantine |
| P3 — Medium | Suspicious activity requiring investigation (anomalous login, unusual data access) | 4 hours | Assigned to analyst for triage | Monitoring escalation, user verification via ChatOps |
| P4 — Low | Policy violations, failed login patterns, configuration drift | 24 hours | Automated triage and logging | Documentation, policy reminder, trend analysis |
Scenario-specific playbook summaries:
- Ransomware: Immediate endpoint isolation → kill encryption processes → preserve forensic image → activate backup recovery → notify legal for regulatory assessment
- Insider Threat: Restrict access without alerting subject → forensic capture of activity → legal/HR coordination → evidence preservation chain-of-custody
- Cloud Compromise: Revoke API keys → rotate credentials → audit IAM permissions → review CloudTrail/audit logs → assess data exposure scope
- Supply Chain Attack: Isolate affected vendor integrations → audit dependency versions → activate vendor communication protocol → sweep for IOCs across environment
✅ UnderDefense’s Severity-Aware Approach
The UnderDefense MAXI platform automatically classifies incidents by severity using AI-driven enrichment across 250+ integrated tools. P1 incidents trigger immediate analyst response with automated containment, including endpoint isolation and credential revocation, executed by concierge analysts, not escalated back to the client. For P3 to P4, AI handles triage and user verification via ChatOps, escalating only confirmed threats that require human judgment.
“Not having to worry about ransomware, alert overload and reporting. Getting a clear view of my security posture, where the threats are coming from and how they are handled. They literally took care of all our problems.”
— Arlin O., Enterprise UnderDefense G2 – Verified Review
“Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User, Program Development UnderDefense G2 – Verified Review
💰 This severity-tiered approach is why UnderDefense maintains 100% ransomware prevention across 500+ MDR clients over 6 years, because a P1 ransomware event gets a fundamentally different response than a P4 policy violation, executed in minutes rather than hours.
Q5: What Are the Breach Notification Requirements Across GDPR, HIPAA, SEC, and Other Regulations?
If you’re operating across jurisdictions, a single breach can trigger half a dozen notification clocks simultaneously, and getting any one of them wrong means regulatory penalties stacked on top of breach costs. This isn’t theoretical. I’ve seen organizations scramble through overlapping GDPR, HIPAA, and SEC timelines during active incidents, and the ones who survive without penalties are the ones who mapped requirements before the crisis hit.
⚠️ The Multi-Regulation Overlap Problem
A breach involving EU customer health data stored in a U.S.-listed company’s cloud environment could trigger GDPR’s 72-hour supervisory authority notification, HIPAA’s 60-day individual notification, SEC’s 4-business-day materiality disclosure, and state-level CCPA requirements, all running concurrently with different clocks, different thresholds, and different penalty structures. The organizations that handle this well have parallel notification workflows pre-built. The ones that don’t? They’re running around with legal counsel at 3 AM trying to figure out which regulator to call first.
📋 Multi-Regulation Breach Notification Comparison
| Regulation | Notification Timeline | Who Must Be Notified | Threshold / Trigger | Maximum Penalty |
|---|---|---|---|---|
| GDPR | 72 hours to supervisory authority; “without undue delay” to data subjects for high-risk breaches | DPA + affected individuals | Breach likely to result in risk to rights and freedoms of individuals | Up to €20M or 4% global annual revenue |
| HIPAA | 60 days to individuals; within 60 days to HHS; immediate to media if 500+ affected in a state | Individuals + HHS + media (if applicable) | Unauthorized access, use, or disclosure of PHI | Up to $2.13M per violation category per year |
| SEC (Item 1.05) | 4 business days after materiality determination via Form 8-K | SEC + public shareholders | Material cybersecurity incident (substantial likelihood a reasonable investor would consider it important) | Enforcement actions, fines, securities fraud liability |
| CCPA/CPRA | “Most expedient time possible and without unreasonable delay” | California AG + affected consumers | Breach of unencrypted personal information | $7,500 per intentional violation; $750–$7,500 per consumer in private action |
| PCI-DSS | Within 72 hours to acquirer/card brands | Acquirer, card brands, forensic investigator | Compromise of cardholder data | Fines up to $500K per incident + potential card brand disqualification |
| DPDP Act (India) | “Without delay” to Data Protection Board; within 72 hours per emerging guidance | Data Protection Board + affected data principals | Any personal data breach | Up to ₹250 crore (~$30M) |
⏰ Critical Decision Points That Trip People Up
The clocks don’t all start the same way. GDPR’s 72 hours begins when you have a “reasonable degree of certainty” a breach occurred, not when you confirm every detail. HIPAA’s 60-day window runs from discovery, not the breach date itself. The SEC’s 4-business-day deadline starts from your materiality determination, not detection, but the SEC expects you to make that determination “without undue delay.” In practice, over 70% of companies in the first 100 days of the rule filed within four business days of detecting the incident, averaging 5.45 business days from detection to disclosure.
Here’s the decision flow when a breach is detected:
- Classify data types involved: PII, PHI, payment data, material business data
- Identify applicable regulations, mapping data types to GDPR, HIPAA, SEC, CCPA, PCI-DSS, and DPDP
- Initiate parallel notification workflows. Don’t sequence them; run simultaneously.
- Document everything. GDPR Article 33(5) requires breach documentation regardless of whether notification is required.
✅ How UnderDefense Simplifies Compliance During Incidents
The UnderDefense MAXI platform automatically generates audit-ready compliance documentation during incident response, mapping containment and remediation actions to regulation-specific evidence requirements. Forever-free compliance kits included with MDR mean notification workflows and evidence templates are pre-built, not improvised at 2 AM during a crisis.
Q6: How Does AI-Powered Detection Transform Incident Response in 2026?
Traditional IR plans are built on an assumption that’s quietly falling apart: that human analysts will triage every alert, investigate every anomaly, and make every containment decision manually. In 2026, with the average SOC receiving thousands of alerts daily and attackers using AI to generate polymorphic malware and automate reconnaissance, this assumption isn’t outdated but operationally dangerous.
The Detection Gap Nobody Wants to Talk About
Organizations running CrowdStrike EDR, Splunk SIEM, and Microsoft Defender still rely on manual correlation across tools. Your EDR sees endpoint behavior. Your identity platform sees user context. Your SIEM collects logs. But none of them reason across each other automatically. You, the analyst, become the manual correlation layer, stitching together context from three consoles at 2 AM. The result? Dwell times stretch, and every breach cost report confirms the same finding: longer dwell time equals higher financial impact.
As one CISO I spoke with put it: “I can’t automate everything. I can’t get to a fully lights-out automated security stack because we always run into situations that need human analysis.” That’s the operational reality.
❌ Detection Without Response Is Just Expensive Alerting
Here’s what I see with legacy providers: AI-powered detection tools generate more alerts, not better outcomes. Arctic Wolf’s AI flags anomalies but escalates them back to your team for investigation, so you still own the resolution. CrowdStrike’s OverWatch identifies threats, but containment requires customer action. The result is faster detection paired with the same slow human response bottleneck.
Traditional MSSPs compound this by running AI models on generic rulesets that don’t understand your organizational context. They’ll tell you “suspicious login detected, please investigate.” That’s not managed detection and response. That’s an alert feed.
“We received little value from ArcticWolf. The product offered little visibility when we were using it… Anything you want to look at or changes you need to make in the product must go through their engineering team.”
— Matt C., Manager, Cybersecurity Services Arctic Wolf – G2 Verified Review
The AI-Era Shift: From Alert Generation to Autonomous Triage
The transformation isn’t about detecting more threats but resolving them faster. AI-powered behavioral analytics correlate signals across endpoints, identity, cloud, and network to classify severity automatically. SOAR integration executes containment playbooks without human intervention for confirmed P1 threats. User verification bots confirm suspicious activity directly with affected employees via Slack or Teams. The result: MTTD drops from days to minutes, and MTTR from hours to sub-30-minutes for critical incidents.
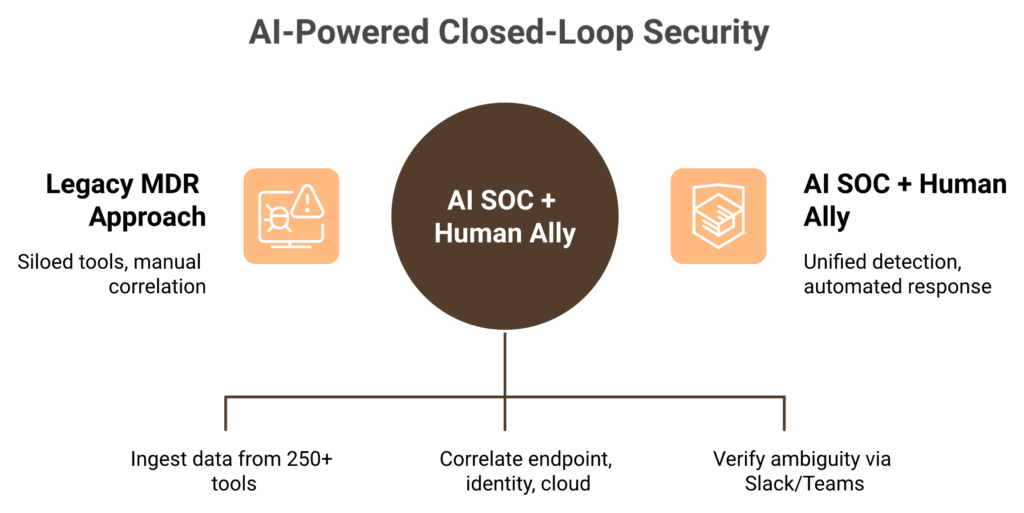
✅ UnderDefense’s AI SOC + Human Ally Model
We built UnderDefense MAXI specifically for this threat landscape. It ingests telemetry from 250+ existing tools, applies AI-driven enrichment to classify and prioritize threats, and triggers automated response for confirmed incidents. But the differentiator is the Human Ally layer. When AI can’t resolve ambiguity (“Was that Jane’s legitimate login from a new device?”), concierge analysts verify directly via Slack, Teams, or email.
This closed-loop AI + human model achieves 99% alert noise reduction while maintaining 96% MITRE ATT&CK coverage. Detection and response happen in the same system, by the same team, with no escalation back to the customer.
“Their team cleaned up our configurations and got the noise under control within the first week. Now when we get an alert, we know it’s something worth looking into… We’re not wasting time piecing together what happened from different systems anymore.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
“Before MAXI, we were slightly overwhelmed with alerts and often unsure of how to prioritize or respond. Now, not only do we get alerts, but we also get clear guidance on how to handle them. False positives have become a rarity.”
— Valeriia D., Marketing Specialist UnderDefense G2 – Verified Review
UnderDefense detected and contained threats 2 days faster than CrowdStrike OverWatch in documented case studies, because AI-driven detection without human context still leaves gaps only analysts communicating directly with users can close.
Q7: What Should a Post-Breach Board Report and Executive Communication Include?
Board reporting during and after a breach isn’t optional anymore. It’s a regulatory expectation under SEC materiality disclosure rules and GDPR’s accountability principle. But here’s what actually loses CISOs their executive confidence: not the breach itself, but failing to communicate its impact in business terms. If your board report reads like a SOC ticket instead of a risk assessment, you’ll lose budget support faster than you lost data.
⏰ The Communication Cadence
Before you even think about content, lock in the rhythm. Boards and executive teams need structured updates, not ad-hoc emails:
| Communication Stage | Timing | Audience | Purpose |
|---|---|---|---|
| Initial Alert | Within 1 hour of confirmed incident | CISO → CEO, General Counsel | Acknowledge the incident; state what’s known, what’s not |
| Situation Update | Every 4 hours during active incident | Incident Command → Executive Team | Containment status, scope changes, regulatory triggers |
| Post-Incident Brief | Within 72 hours of containment | CISO → C-Suite | What happened, what was the impact, what’s next |
| Full Board Report | Within 30 days | CISO → Board of Directors | Comprehensive analysis, root cause, strategic recommendations |
📋 Board Report Template: Seven Sections That Matter
1. Executive Summary (2 to 3 sentences)
What happened, what was the impact, and is it contained. Board members don’t want to parse log files. They want the operational headline. Example: “On March 14, a credential-stuffing attack compromised 12,400 customer records. The breach was contained within 4 hours. No financial data was accessed.”
2. Incident Timeline
Discovery → Containment → Eradication → Recovery, with timestamps. This is your evidence of speed and competence.
3. Business Impact Assessment
Data types compromised, number of records affected, customer/revenue impact, and operational downtime. Quantify financial exposure. Even estimates carry weight.
4. Regulatory Exposure
Which regulations were triggered, notification status for each, and potential penalties. Reference specific deadlines: “GDPR notification filed within 48 hours. HIPAA notification in progress, 60-day deadline is May 15.”
5. Root Cause Analysis
Attack vector, vulnerabilities exploited, and detection gaps. Be honest. Boards respect transparency more than spin. If your EDR missed the initial access because of a configuration gap, say so.
6. Remediation Actions
Completed actions (credentials revoked, endpoints isolated, patches applied) and planned actions (security architecture changes, tool deployment, and policy updates) with owners and deadlines.
7. Strategic Recommendations
Budget requests, technology changes, and process improvements. This is where the breach becomes a catalyst for investment rather than just a cost center.
💡 Communication Best Practices
Use business language, not technical jargon. Instead of “the adversary leveraged a LOLBin to execute lateral movement via SMB,” write “the attacker used built-in Windows tools to move across our network undetected.” Quantify financial exposure wherever possible. Present containment evidence clearly, because boards need confidence that the bleeding has stopped. Provide clear decision points: approve remediation budget, authorize external disclosure, and engage regulatory counsel.
✅ How UnderDefense Supports Board-Ready Reporting
UnderDefense’s incident response reporting includes board-ready documentation. UnderDefense MAXI generates timeline-stamped evidence, impact assessments, and compliance mappings that CISOs can present directly to executive leadership without spending days compiling reports manually. When every hour counts for SEC’s 4-business-day materiality disclosure window, having automated documentation isn’t a luxury but an operational necessity.
Q8: How Do You Test and Validate Your Incident Response Plan?
An untested IR plan is a document, not a capability. I’ve seen organizations with 50-page incident response playbooks that fell apart the first time a real ransomware attack hit, because nobody had ever actually walked through the steps under pressure. Testing isn’t a compliance checkbox. It’s how you find out whether your plan survives contact with reality.
☐ IR Plan Testing Readiness Checklist
Run through these honestly. Checking the box because you plan to doesn’t count:
- Do you conduct tabletop exercises at least quarterly with cross-functional participation (IT, Security, Legal, and Comms)?
- Do your simulations include realistic scenarios, such as ransomware, insider threat, cloud compromise, and supply chain attack?
- Are executive stakeholders included in at least one annual exercise?
- Do you measure MTTD, MTTR, and containment time during drills?
- Are lessons from each exercise documented and incorporated into updated playbooks within 30 days?
- Do you test notification workflows end-to-end, including regulatory, customer, and board communication?
- Have you validated backup and recovery procedures with actual restore tests in the last 90 days?
- Do you benchmark IR performance against industry standards (NIST CSF, SANS)?
⭐ Score Interpretation
| Score | Assessment | What It Means |
|---|---|---|
| 7–8 ✅ | Mature IR program | Focus on optimization, advanced threat hunting, and continuous improvement |
| 4–6 ✅ | Critical gaps exist | Your plan may fail under real-world pressure. Testing frequency or scenario coverage needs work. |
| 0–3 ✅ | Document, not capability | Untested plans are unreliable plans. You need immediate investment in validation. |
⏰ Recommended Testing Frequency
- Tabletop exercises, quarterly, rotating scenarios (ransomware, BEC, cloud breach, and insider threat)
- Full red team/blue team simulations, semi-annually, with external adversary emulation
- Backup and restore validation, quarterly, including actual data recovery from backups
- Plan review and update, after every real incident + annually at minimum
- Executive communication drills, annually, testing board notification and regulatory disclosure workflows
The key insight from working with hundreds of organizations: the teams that test quarterly improve measurably. The teams that test annually are essentially gambling that their plan still works.
✅ How UnderDefense Fills the Testing Gap
Here’s an operational reality most people miss: if you’re running 24/7 MDR, your detection and response workflows are being validated every single day by real-world threats, not just during scheduled drills. UnderDefense conducts continuous IR plan validation through real-time threat monitoring that effectively stress-tests detection, triage, and containment workflows with every incident. Quarterly threat landscape briefings identify new scenario types for your tabletop exercises. And the UnderDefense MAXI platform’s automated playbook execution means containment procedures are validated with every confirmed threat, not just during annual simulations.
“UnderDefense has changed our approach to cybersecurity. At first, we hired them for managed SIEM service, but after they demonstrated the value of MDR, our management was motivated to act on it. Now, with their security monitoring and incident response we know our endpoints are well-protected.”
— Yaroslava K., IT Project Manager UnderDefense G2 – Verified Review
“With their proactive monitoring and rapid incident response capabilities, we can detect and mitigate security threats.”
— Alexey S., CEO UnderDefense G2 – Verified Review
UnderDefense clients achieve measurable MTTD/MTTR improvements within 30 days of onboarding, because real-time threat response provides more validation data than annual tabletop exercises ever could.
Q9: What Does a Real-World Data Breach Forensics Investigation Look Like?
It’s 3:12 AM on a Sunday. Your monitoring system sends 47 alerts in 90 seconds, and endpoints across three departments are encrypting files simultaneously. By the time your on-call engineer logs in at 3:28 AM, the attacker has already moved laterally from the initial phishing compromise to your file servers, backup systems, and Active Directory. The ransom note demands $2.4M in Bitcoin within 48 hours. Your IR plan is a 40-page PDF that nobody has opened since last year’s compliance audit.
⚠️ Why This Happened: The Forensic Timeline
The encryption at 3:12 AM wasn’t the beginning. It was the finale. Here’s what forensics uncovered:
Day -14: A finance team member clicked a credential-harvesting link in a spoofed vendor email. The email gateway flagged it as “medium risk” but didn’t block it.
Day -12: Harvested credentials used to access VPN. The identity platform logged an unusual location, but no one investigated the alert.
Day -7: Privilege escalation via unpatched Active Directory vulnerability. EDR flagged suspicious Kerberoasting activity; the alert sat in a queue.
Day -3: Attacker performed reconnaissance, mapped backup infrastructure, and deleted shadow copies. SIEM logged volume spikes, but correlation rules weren’t tuned for this pattern.
Day 0, 3:12 AM: Simultaneous encryption across three departments. Game over.
Fourteen days of dwell time. Each security tool saw a fragment of the attack. The email gateway caught the phish, identity flagged the anomalous login, EDR detected privilege escalation, and SIEM logged the data spikes. But nothing correlated them into a single attack chain.
💸 The Hidden Costs Nobody Budgets For
The ransom is just the headline number. The real costs stack up fast:
- Average ransomware recovery cost: $1.85M (including downtime, remediation, and legal fees)
- Mean downtime: 23 days before full operational recovery
- Reputational damage: Customer churn, lost contracts, and depressed valuation during fundraising or exit
- Regulatory penalties: GDPR, HIPAA, and SEC fines layer on top of operational losses
✅ How This Should Have Worked
With cross-tool correlation in place, the attack chain becomes visible on Day -12, not Day 0. Here’s the alternative timeline:
Day -12, 11:43 AM: AI correlates the phishing email, credential anomaly, and unusual VPN login as a single attack chain. Severity auto-classified as P1.
Day -12, 11:45 AM: Automated containment isolates the compromised endpoint and disables the harvested credentials.
Day -12, 11:48 AM: Analyst messages the affected employee via Slack: “Did you authorize a VPN login from this location at 10:37 AM?” Employee confirms they didn’t.
Day -12, 12:15 PM: Threat eradicated. Full forensic report generated. Attack chain documented. Zero encryption. Zero ransom.
How UnderDefense Would Have Handled This
We built UnderDefense MAXI for exactly this scenario. Cross-tool correlation connects email gateway alerts, identity anomalies, EDR detections, and SIEM logs into a unified timeline, automatically. AI-driven severity classification flags the credential compromise as P1 within minutes, not days. Automated endpoint isolation stops lateral movement before it starts. And our concierge analysts verify directly with the affected user through Slack or Teams, closing the context gap that left 47 alerts sitting uninvestigated.
UnderDefense has documented 2-minute alert-to-triage and 15-minute escalation for critical incidents, and maintains a 100% ransomware prevention record across all MDR clients over six years. From a 14-day dwell time and $2.4M ransom demand to same-day detection and containment, that’s the difference between an IR plan on paper and one operationalized through an AI SOC with Human Ally support.
Q10: What Are the Essential Templates and Checklists for Your Data Breach Response Plan?
A solid IR plan isn’t one document but a toolkit. Most organizations have a single incident response policy document and call it done. What they’re missing are the operational templates that make the plan executable under pressure. Here are the six essential templates every IR program needs.
📋 The Six Templates Every IR Plan Requires
1. Master IR Plan Template
The backbone document defining roles (RACI matrix), IR phases (preparation → detection → containment → eradication → recovery → lessons learned), escalation paths, communication channels, and decision authority. This isn’t a policy statement but a runbook your team opens at 2 AM.
2. Incident Severity Classification Matrix
A clear, pre-agreed matrix that removes ambiguity during active incidents:
| Severity | Criteria | Response SLA | Example |
|---|---|---|---|
| P1 — Critical | Active data exfiltration, ransomware encryption, compromised admin credentials | 15-minute escalation; all-hands | Ransomware encrypting production servers |
| P2 — High | Confirmed malware, lateral movement, unauthorized access to sensitive data | 1-hour triage; IR team engaged | Compromised user account accessing financial databases |
| P3 — Medium | Suspicious behavior requiring investigation, policy violations | 4-hour triage; assigned analyst | Unusual login from new geography, unverified |
| P4 — Low | False positive candidates, informational alerts, minor policy deviations | Next business day review | Automated scan triggering known benign signature |
3. Breach Notification Decision Tree
A regulation-by-regulation flowchart that determines notification obligations. When data types are classified (PII, PHI, payment data, and material business information), the tree maps each to applicable regulations, including GDPR, HIPAA, SEC, CCPA, PCI-DSS, and DPDP Act, and triggers parallel notification workflows with specific timelines and responsible parties.
4. Stakeholder Communication Templates
Pre-drafted, lawyer-reviewed message templates for five audiences: regulatory bodies, affected customers, internal employees, media/public, and board of directors. During an active incident, nobody should be wordsmithing from scratch.
⏰ Evidence Preservation and Post-Incident Review
5. Evidence Preservation Checklist
Forensic integrity depends on procedure, not improvisation:
- Capture volatile data first (RAM, running processes, and network connections)
- Create forensic disk images before any remediation
- Preserve log files across SIEM, EDR, identity, cloud, and email systems
- Document chain-of-custody for every evidence artifact
- Retain all communication records related to the incident
6. Post-Incident Review Framework
A structured retrospective template covering: timeline reconstruction, root cause analysis, detection gap assessment, playbook updates needed, and KPI measurement (MTTD, MTTR, containment time, and false positive rate during the incident). Every review should produce at least three actionable improvements integrated into updated playbooks within 30 days.
⏰ Incident Response Quick-Reference Cheat Sheet
| Timeframe | Actions |
|---|---|
| First 15 Minutes | Activate IR team, isolate affected systems, preserve volatile evidence |
| First Hour | Classify severity (P1–P4), notify legal counsel, begin forensic imaging |
| First 24 Hours | Complete containment, initiate eradication, draft regulatory notification |
| First 72 Hours | Complete eradication, begin recovery, submit GDPR notification if applicable |
| First 30 Days | Complete recovery, finalize board report, conduct lessons-learned review |
✅ How UnderDefense Operationalizes These Templates
Organizations using the UnderDefense MAXI platform don’t execute these templates manually. Automated playbooks handle severity classification, containment actions, and evidence collection in real time. Concierge analysts manage stakeholder communication and compliance documentation during active incidents, so your CISO isn’t simultaneously triaging threats and drafting board updates. The result: templates become living workflows, not dusty PDFs pulled out during a crisis.
1. What are the six core phases of a data breach incident response plan?
We structure every data breach incident response plan around six proven phases that map to both the SANS lifecycle and the updated NIST SP 800-61 Rev 3 framework.
-
Preparation is where 80% of IR success is determined — documenting roles, deploying tools like SIEM and EDR, and running quarterly tabletop exercises.
-
Identification and Detection focuses on automated monitoring, alert triage, and initial severity classification to separate real threats from noise.
-
Containment (short-term and long-term) isolates affected endpoints, blocks lateral movement, and preserves forensic evidence.
-
Eradication removes root causes entirely — malware, backdoors, persistence mechanisms, and compromised credentials.
-
Recovery restores systems from verified clean backups with heightened monitoring for 30 to 60 days post-incident.
-
Lessons Learned conducts blameless retrospectives within 72 hours, updates playbooks, and measures MTTD, MTTR, and containment time.
The practical difference between SANS and NIST Rev 3 is that SANS provides a sequential playbook while NIST maps IR to continuous CSF 2.0 functions. Most mature organizations use both — SANS for operational execution, NIST for governance alignment. Our incident response services automate transitions between these phases so your plan becomes a living system, not a static document.
2. Who should be on an incident response team and what are their responsibilities?
We’ve seen the same mistake across dozens of organizations: treating incident response as a security-only function. An effective IR team must be cross-functional by design, assembled and rehearsed well before any breach occurs. The core roles we recommend:
-
Incident Commander — owns the response end-to-end, makes containment decisions, and has authority to override normal change management during active incidents.
-
Security Analysts — triage alerts, investigate IOCs, perform forensic analysis, and execute containment actions.
-
Legal Counsel — makes regulatory notification decisions across GDPR, HIPAA, SEC, and other frameworks.
-
Communications Lead — handles internal and external messaging using pre-drafted, lawyer-reviewed templates.
-
IT Operations — executes system containment, manages backup restoration, and validates system integrity.
-
Executive Sponsor — translates technical status into business impact for the board.
-
External Partners — MDR providers, forensics firms, and breach coaches on pre-negotiated retainers.
Each role should be mapped in a RACI matrix across all IR phases. The 24/7 coverage gap is the critical challenge for mid-market teams — building an internal SOC with round-the-clock analysts requires 8–12 FTEs at $1.5M–$2.5M annually, which is why external MDR partnerships have become an operational necessity.
3. What are the breach notification requirements for GDPR, HIPAA, and SEC in 2026?
We’ve helped organizations navigate overlapping notification timelines during active incidents, and the ones who avoid penalties are those who mapped every requirement before the crisis hit. A single breach can trigger multiple clocks simultaneously:
-
GDPR — 72 hours to the supervisory authority from when you have “reasonable certainty” a breach occurred; “without undue delay” to affected individuals for high-risk breaches. Penalties reach up to €20M or 4% of global annual revenue.
-
HIPAA — 60 days to affected individuals from discovery; immediate media notification if 500+ records are affected in a single state. Fines up to $2.13M per violation category per year.
-
SEC (Item 1.05) — 4 business days after materiality determination via Form 8-K. The clock starts not from detection but from the judgment call that the incident is material.
-
DPDP Act (India) — “Without delay” to the Data Protection Board, with emerging guidance targeting 72 hours. Penalties up to ₹250 crore (~$30M).
The key operational requirement is running parallel notification workflows, not sequential ones. Our compliance services auto-generate audit-ready documentation mapping containment actions to regulation-specific evidence requirements, so legal counsel isn’t improvising at 2 AM.
4. How do you build severity-tiered playbooks for different breach scenarios?
We’ve reviewed dozens of IR plans across mid-market companies, and the pattern is consistent: a single runbook, a single escalation path, and a single response speed regardless of severity. This creates two predictable failure modes — over-response to minor incidents and under-response to critical ones. We recommend a P1-to-P4 severity classification:
-
P1 (Critical) — Active data exfiltration, ransomware encryption, or confirmed APT. Response SLA: 15 minutes. Triggers immediate Incident Commander activation and board notification within 1 hour.
-
P2 (High) — Confirmed unauthorized access, lateral movement, or BEC compromise. Response SLA: 1 hour.
-
P3 (Medium) — Suspicious activity requiring investigation. Response SLA: 4 hours.
-
P4 (Low) — Policy violations, failed login patterns, configuration drift. Response SLA: 24 hours.
Each severity level needs its own playbook for common scenarios: ransomware, insider threat, cloud compromise, and supply chain attack. The UnderDefense MAXI platform auto-classifies incidents by severity using AI-driven enrichment, triggering automated containment for P1 threats while AI handles P3–P4 triage — ensuring critical events never sit in the same queue as policy violations.
5. How does AI-powered detection improve incident response times in 2026?
We built our detection model around a reality most organizations face: traditional IR plans assume human analysts will triage every alert manually, but with SOCs receiving thousands of alerts daily and attackers using AI for polymorphic malware and automated reconnaissance, that assumption has become operationally dangerous. The transformation isn’t about detecting more threats — it’s about resolving them faster:
-
AI-powered behavioral analytics correlate signals across endpoints, identity, cloud, and network to classify severity automatically.
-
SOAR integration executes containment playbooks without human intervention for confirmed P1 threats.
-
User verification bots confirm suspicious activity directly with affected employees via Slack or Teams.
The result: MTTD drops from days to minutes, and MTTR from hours to sub-30-minutes for critical incidents. But detection without response is just expensive alerting. Many legacy providers flag anomalies but escalate them back to your team for investigation, so you still own the resolution bottleneck. We designed UnderDefense MAXI with an AI SOC + Human Ally model that achieves 99% alert noise reduction while maintaining 96% MITRE ATT&CK coverage. When AI can’t resolve ambiguity, concierge analysts verify directly — no escalation back to the customer.
6. How often should you test and validate your incident response plan?
We’ve seen organizations with 50-page incident response playbooks fall apart during their first real ransomware attack because nobody had ever walked through the steps under pressure. An untested IR plan is a document, not a capability. Here’s the testing cadence we recommend based on working with hundreds of organizations:
-
Tabletop exercises — quarterly, rotating scenarios (ransomware, BEC, cloud breach, insider threat) with cross-functional participation.
-
Full red team/blue team simulations — semi-annually, with external adversary emulation.
-
Backup and restore validation — quarterly, including actual data recovery tests, not just confirming backups exist.
-
Executive communication drills — annually, testing board notification and regulatory disclosure workflows end-to-end.
-
Plan review and update — after every real incident plus annually at minimum.
The teams that test quarterly improve measurably. The teams that test annually are essentially gambling that their plan still works. If you’re running 24/7 MDR, your detection and response workflows get validated every day by real-world threats — not just during scheduled drills. This continuous validation through real-time monitoring provides more actionable data than annual tabletop exercises ever could.
7. What should a post-breach board report include for executive leadership?
We’ve seen more CISOs lose executive confidence not because of the breach itself, but because they failed to communicate its impact in business terms. If your board report reads like a SOC ticket instead of a risk assessment, you’ll lose budget support faster than you lost data. Every post-breach board report should include these seven sections:
-
Executive Summary — 2–3 sentences: what happened, what was the impact, is it contained.
-
Incident Timeline — Discovery → Containment → Eradication → Recovery with timestamps proving speed and competence.
-
Business Impact Assessment — Data types compromised, records affected, customer/revenue impact, and operational downtime quantified in financial terms.
-
Regulatory Exposure — Which regulations were triggered, notification status for each, and potential penalties with specific deadlines.
-
Root Cause Analysis — Attack vector, vulnerabilities exploited, and detection gaps. Boards respect transparency over spin.
-
Remediation Actions — Completed and planned actions with owners and deadlines.
-
Strategic Recommendations — Budget requests and technology changes that turn the breach into a catalyst for investment.
Communication cadence matters too: initial alert within 1 hour, situation updates every 4 hours during active incidents, post-incident brief within 72 hours, and full board report within 30 days. Our incident response reporting generates timeline-stamped evidence and compliance mappings your CISO can present directly to leadership.
8. What templates and checklists are essential for an executable data breach response plan?
We see the same gap across most organizations: they have a single incident response policy document and call it done. A solid IR plan isn’t one document — it’s a toolkit of six essential templates that make the plan executable under pressure.
-
Master IR Plan Template — the backbone runbook defining roles (RACI matrix), phases, escalation paths, and decision authority. This is what your team opens at 2 AM.
-
Incident Severity Classification Matrix — a pre-agreed P1–P4 framework that removes ambiguity during active incidents.
-
Breach Notification Decision Tree — a regulation-by-regulation flowchart mapping data types to GDPR, HIPAA, SEC, CCPA, PCI-DSS, and DPDP Act notification obligations.
-
Stakeholder Communication Templates — pre-drafted, lawyer-reviewed messages for regulators, customers, employees, media, and the board.
-
Evidence Preservation Checklist — covering volatile data capture, forensic disk imaging, log preservation, and chain-of-custody documentation.
-
Post-Incident Review Framework — structured retrospective covering timeline reconstruction, root cause analysis, detection gap assessment, and KPI measurement.
We provide a free incident response plan template that covers these components. For organizations using UnderDefense MAXI, automated playbooks handle severity classification, containment, and evidence collection in real time — turning templates into living workflows.