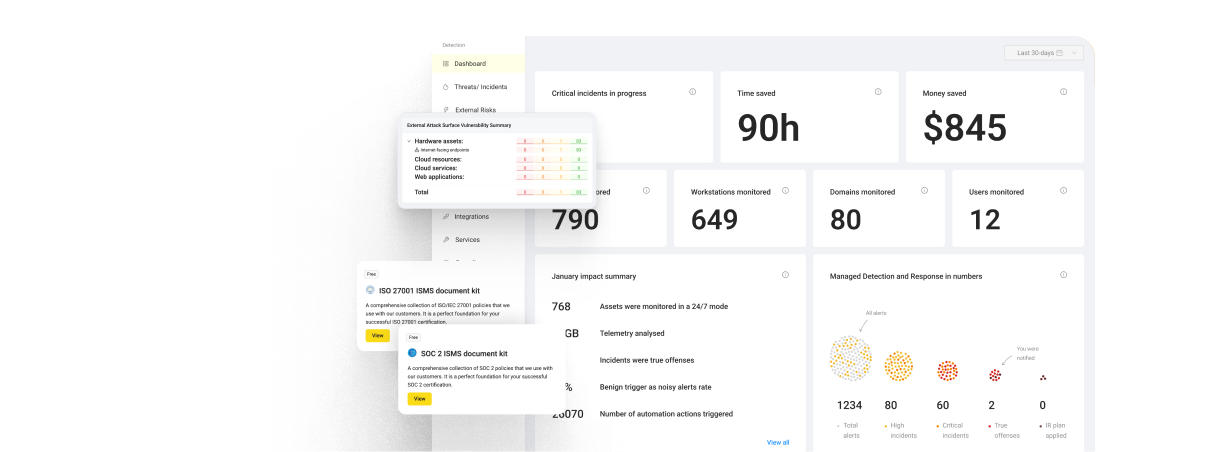
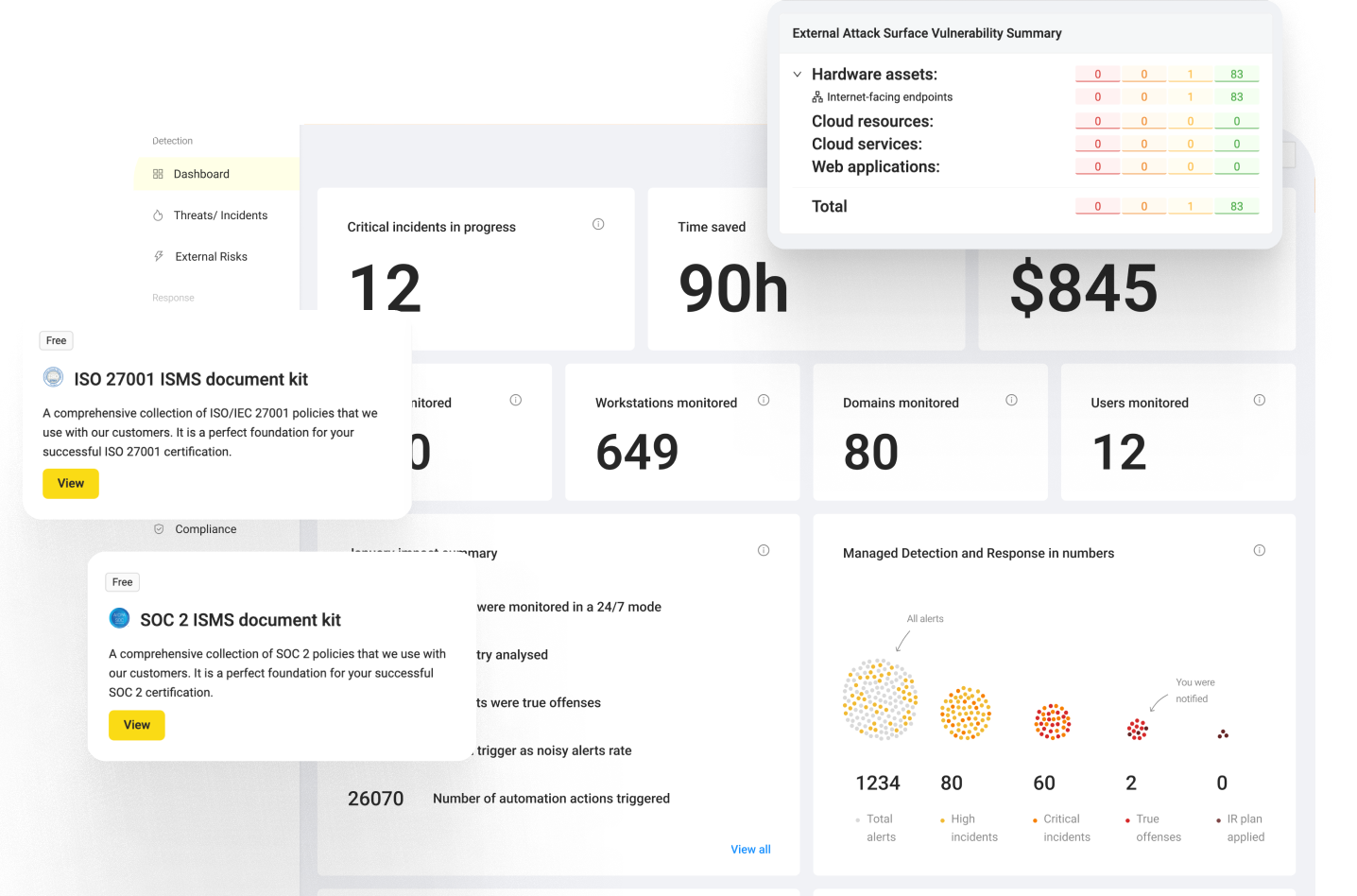
Q1. Why does the 2026 SOC need an end-to-end AI pipeline, not another point tool?
SOC teams in 2026 are drowning. The average enterprise sees 2,992 alerts a day, 63% go untouched, and field studies show 99% of triaged alerts are false positives. Threat actors have already weaponized agentic AI, so adding another point tool only deepens the toil. The fix is a single pipeline that moves anomaly detection, investigation, and containment under one transparent, AI-driven workflow with humans in the loop.
See how UnderDefense Agentic AI SOC resolves a real incident on your stack.
The 9:14 a.m. reality every SOC lead recognizes
Picture a Tier-1 analyst on Monday at 9:14 a.m. There are 1,800 unread alerts in the queue. Two are real. The other 1,798 are noise from a dozen tools that do not talk to each other. ⚠️
This is a pipeline problem. Vectra’s 2026 State of Threat Detection report confirms what the queue already shows: 2,992 alerts per analyst-day, and 63% never get touched at all. The USENIX Security study by Alahmadi, Axon, and Martinovic went further. In real SOC environments, 99% of triaged alerts were false positives, and the root cause was missing context, not bad detection logic.
Then comes the cruelest stat. The SANS 2024 SOC Survey found that 81% of teams reported heavier workloads after adding complex security tools. More tools, more toil. ❌
From alert-tossing MSSPs to outcome-based pipelines
Legacy MSSPs forward alerts. Traditional MDR providers escalate them. Neither owns the outcome. The 2026 model is different: a pipeline where anomaly detection, autonomous investigation, and concierge response sit on one transparent layer, and the SOC measures itself in contained incidents, not raised tickets. ✅
In our experience running UnderDefense Agentic AI SOC across global enterprises, the gap is structural, not cosmetic. You cannot bolt agentic AI onto a tool that was designed to throw alerts over a wall. You have to rebuild around the pipeline. That is what the rest of this article walks through.
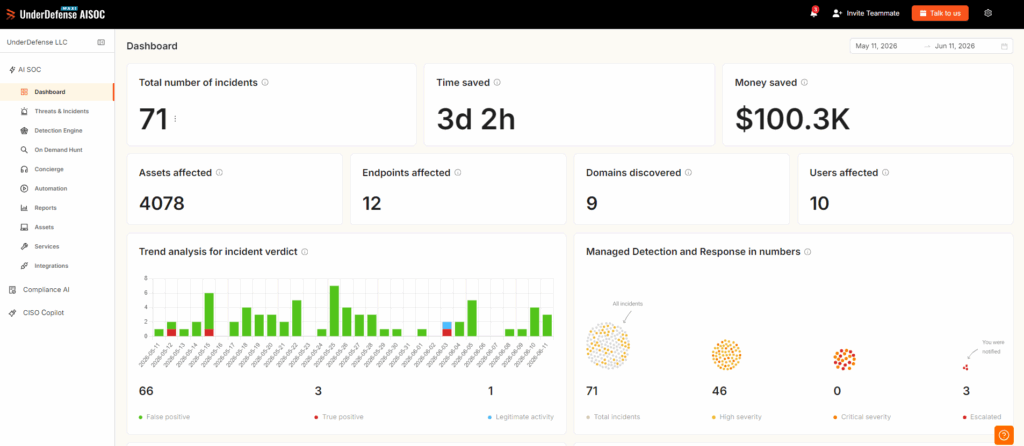
Q2. What exactly is AI anomaly detection, and how does it build a behavioral baseline?
AI anomaly detection establishes what “normal” looks like for every user, host, and workload by learning from weeks of telemetry, then flags statistically significant deviations in real time. Modern systems use peer-group baselines, time-of-day weighting, and identity context. The output is not a yes-or-no alert, but a ranked anomaly with the evidence chain attached, which becomes the input to autonomous investigation.
Plain-English: UEBA without the buzzword tax
UEBA stands for User and Entity Behavior Analytics. NIST SP 800-94 defines anomaly-based detection as profiling normal activity, then flagging deviations. The modern twist is that the profile is per-identity, per-peer-group, and adaptive. It updates continuously instead of waiting for someone to tune a threshold.
A concrete example you can picture
A finance VP in Helsinki logs into Microsoft 365 at 3 a.m. on a Tuesday. By itself, that is normal. She travels often. The baseline knows that. ✅
Same login, plus a bulk SharePoint download of 4 gigabytes of payroll files, plus a new OAuth token granted to an unknown app. That combination has never happened in her 18-month history, and no one in her peer group has done it either. The anomaly score spikes. The pipeline does not just alert. It triggers an investigation. ⚠️
Why static thresholds fail (the 4-year tuning treadmill)
One prospect told me, on a discovery call last year, that his team had been tuning their legacy EDR for four years and still was not “done.” That is not a tuning problem, but operational debt compounding. ❌
Static rules cannot keep up with identity sprawl, hybrid cloud, and SaaS proliferation. Adaptive baselines can. The SANS 2024 SOC Survey identified missing context, not missing detections, as the number-one barrier to triage speed. Baselines are how you ship context into the alert at birth, not at the end of an investigation. For deeper background, our team has written about understanding SIEM and how baselining fits the broader detection stack.
Long Tail Analysis: hunting the singletons
The other half of anomaly detection is what detection engineers call Long Tail Analysis. You strip away the high-frequency noise, then look at the singletons, the rare odd ducks in the logs. That is where novel threats hide. The Zimbra memcache exploit we saw last year was invisible to EDR because no malware ran. It surfaced only through behavioral log analysis on a singleton process pattern.
Founder takeaway
What my experience of shipping UnderDefense Agentic AI SOC tells me is this: baselines are the on-ramp out of the tuning treadmill. If your team is still hand-tuning rules in 2026, you are paying analyst salaries to do work the model should be doing for them. Pairing baselines with a MDR service closes the loop between detection and response.
Q3. What is the OSCAR framework, and how does it map to NIST 800-61, MITRE ATT&CK, and F3EAD?
OSCAR is a five-stage pipeline (Observe, Score, Correlate, Act, Review) that turns raw telemetry into autonomous containment in minutes. Each stage maps simultaneously to NIST SP 800-61 Rev. 3, MITRE ATT&CK techniques, and the F3EAD intel cycle, so every action has a doctrinal anchor and an audit trail. Unlike black-box triage, OSCAR exposes every AI and human decision step, which is what regulators, boards, and skeptical analysts actually need.
Why we named the framework
Most competitors have AI-washed their decks by renaming products. We rebuilt the SOC around agentic AI to deliver outcomes like 99% noise reduction. OSCAR is how we explain the rebuild. Think of it like Iron Man putting on the suit. The analyst is still the pilot. The suit just lets them move at machine speed. ✅
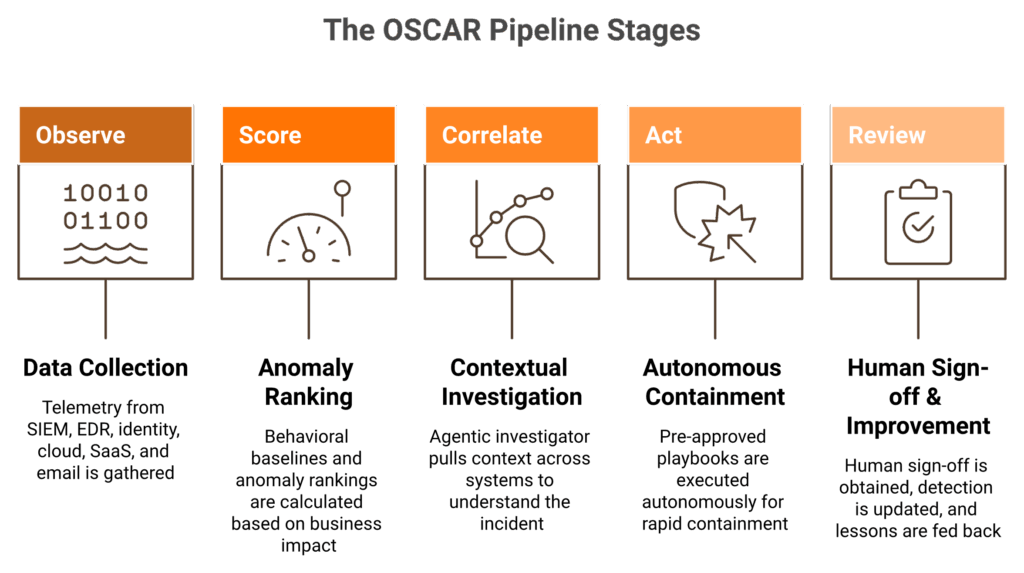
The five stages, in plain terms
Observe. Collect telemetry from SIEM, EDR, identity, cloud, SaaS, and email. Normalize it. This is the F3EAD “Find” step and the NIST 800-61 “Detection” phase. ATT&CK tactic family: Reconnaissance through Initial Access.
Score. Apply behavioral baselines and anomaly scoring. Rank by business impact, not just technical severity. F3EAD: still “Find.” NIST: “Analysis” begins. ATT&CK: Execution and Persistence indicators surface here.
Correlate. The agentic investigator pulls context across systems. Identity, asset criticality, threat intel, and recent change tickets. F3EAD: “Fix.” NIST: “Analysis” complete. ATT&CK: Lateral Movement and Credential Access mapped.
Act. Autonomous containment for pre-approved playbooks. Credential wipe, session kill, host isolation, and token revocation, all in under 2 minutes for Alert-to-Triage with 15-minute escalation for critical incidents. F3EAD: “Finish.” NIST: “Containment, Eradication, Recovery.”
Review. Human reviewer signs off. Detection logic updated as code. Lessons fed back to baselines. F3EAD: “Exploit, Analyze, Disseminate.” NIST: “Post-Incident Activity.”
Triple-mapping table
| OSCAR Stage | NIST SP 800-61 Rev. 3 Phase | MITRE ATT&CK Tactic Family | F3EAD Step |
|---|---|---|---|
| Observe | Detection | Reconnaissance, Initial Access | Find |
| Score | Detection / Analysis | Execution, Persistence | Find |
| Correlate | Analysis | Lateral Movement, Credential Access, Discovery | Fix |
| Act | Containment, Eradication, Recovery | Defense Evasion, Impact (countered) | Finish |
| Review | Post-Incident Activity | Full kill chain debrief | Exploit, Analyze, Disseminate |
What this means on Monday morning
Pull your last 20 incidents. Map each one to the five OSCAR stages. Where did the pipeline stall? In our experience of building SOC teams across 500+ customer environments, 70% of the stall happens at Correlate, because the analyst is hand-querying three systems for context the agent could fetch in 8 seconds. That is your highest-ROI automation target, and a useful read alongside our breakdown of SOC metrics like MTTD and MTTR.
“Their expert management of our SIEM has added to the value of our security investments and tools.”
— Yaroslava K., IT Project Manager UnderDefense G2 – Verified Review
Q4. How does AI autonomously investigate SIEM and EDR alerts without hallucinating?
An agentic AI investigator queries the SIEM, pulls the EDR process tree, checks identity and asset context, cross-references threat intel, and drafts a verdict with citations, typically in under 90 seconds. The guardrail is retrieval-augmented grounding. Every claim links back to a real log line. Without RAG, LLM-only triage hallucinates MITRE mappings about 12% of the time. Transparent citation chains are the only acceptable design in 2026.
The eight-step tool-use chain
Here is what the agent actually does, end to end, when an anomaly fires from Q2’s baseline:
- Pull the raw alert from the SIEM with full context fields. ✅
- Fetch the EDR process tree for the affected host, including parent and child processes.
- Query identity (Entra ID, Okta) for recent sign-ins, MFA events, and token activity.
- Check asset criticality from CMDB or tag store. A jump server is not a kiosk.
- Enrich with threat intel (CISA KEV, MISP, internal IOCs) for IPs, hashes, and domains.
- Map to MITRE ATT&CK with retrieval-grounded technique IDs, not LLM guesses.
- Run a ChatOps check when warranted. Slack the user: “Did you just run this command?” ✅
- Draft a verdict with confidence score, evidence citations, and recommended action.
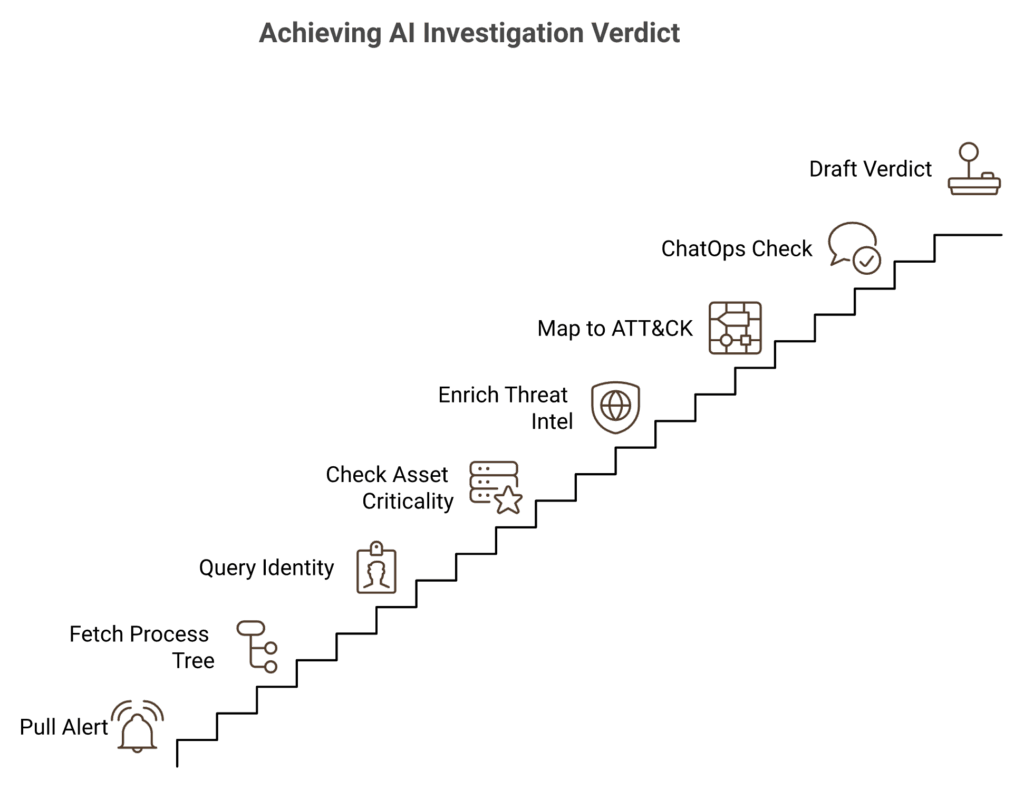
The whole chain runs in 60 to 120 seconds in our UnderDefense Agentic AI SOC environment.
The 12% hallucination problem (and the RAG fix)
A 2024 arXiv paper on LLM-assisted SOC triage found that ungrounded LLMs hallucinated MITRE technique IDs in roughly 12% of cases. That is unacceptable in production. The fix is retrieval-augmented generation. The agent is forced to cite real log lines and real ATT&CK records before it can output a verdict. ⚠️
If your vendor cannot show you the citation chain on a live screen, walk away. ❌ This is one of the AI SOC red flags we coach buyers to watch for.
“Bias is a feature” (the contrarian take)
I might be wrong here, but when we ran this against our own UnderDefense Agentic AI SOC environment, what we noticed is this: a measurable, biased model that analysts can tune always beats an “unbiased” black box that no one can audit. ✅
Bias you can see is bias you can fix. Bias you cannot see is the thing that misses the breach.
The 30% accuracy ceiling
Operational data across our customer base shows AI is correct on roughly 30% of complex security cases without human validation. That is why OSCAR’s “Review” stage exists. AI handles the mechanical 70%, humans own the judgment calls, and the audit trail proves who decided what. The Tilbury and Flowerday 2024 study on automation bias in SOCs found that analysts over-trust AI verdicts when confidence labels are not calibrated, and that creates a new failure mode the framework has to design around. For practitioners weighing build versus buy, our take on whether AI kills or saves the SOC team goes deeper on this trade-off.
“The platform’s high-fidelity alerts and automated enrichment help us quickly identify and address threats.”
— Verified User in Computer Software UnderDefense G2 – Verified Review
“Underdefense act as an extension of our team, so we don’t need additional resources, ensuring 24/7 protection. It also solved our problem of having separate security tools that didn’t work well together.”
— Inga M., CEO UnderDefense G2 – Verified Review
Q5. How do you cut false positives 90%+ and reach 100% alert coverage without adding headcount?
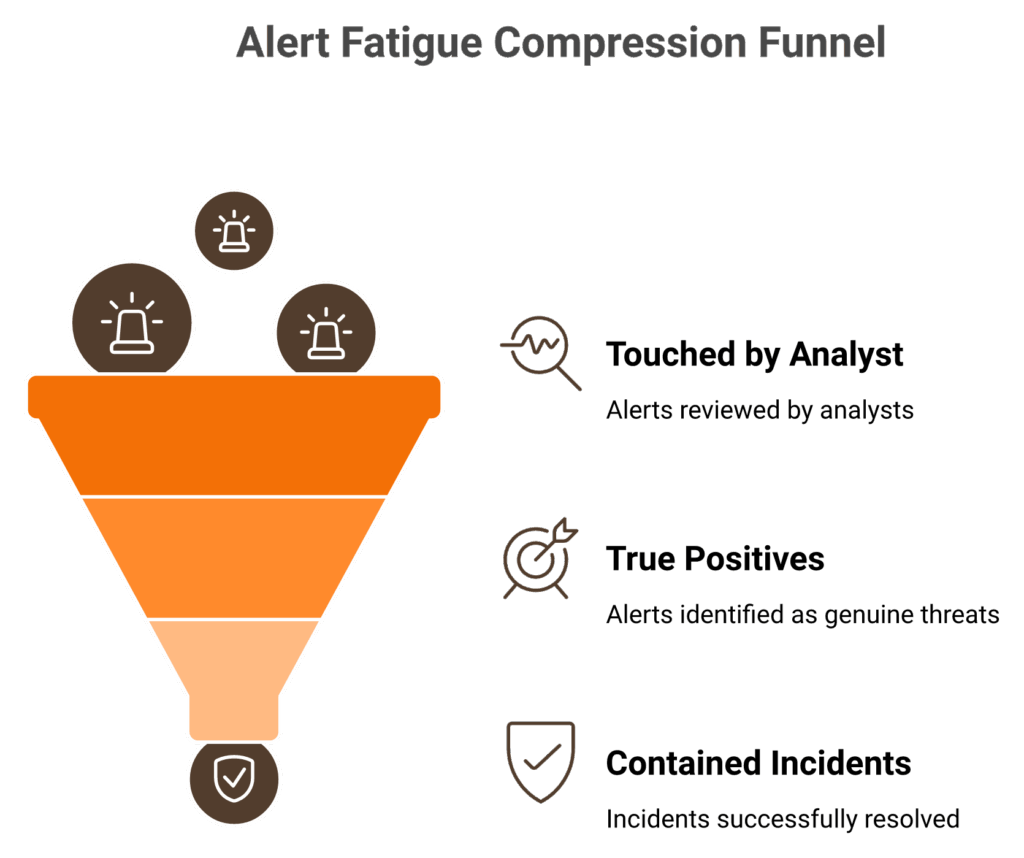
False positive reduction at scale is not suppression. It is adding context. Asset criticality, identity, and peer behavior turn “suspicious PowerShell” into “patch automation, benign,” or “lateral movement, contain now.” The math is brutal: 2,992 alerts a day at 8 minutes each equals 399 analyst hours, impossible for any team. Agentic AI handles the mechanical work in seconds. Humans review the high-confidence escalations. That is how 100% coverage stops being a slogan.
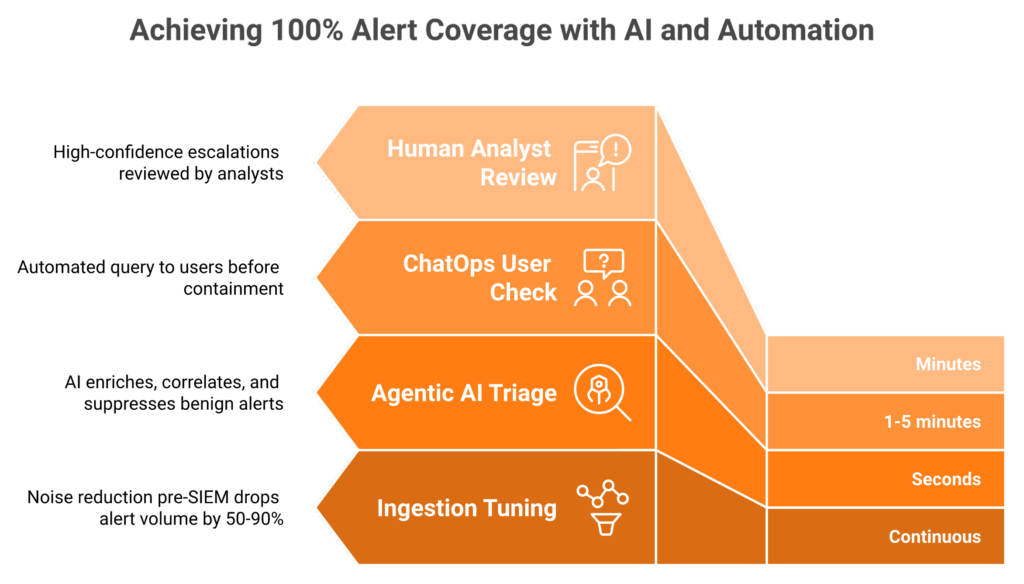
The contrarian truth: unlimited ingestion is a liability
Most MSSPs sell “unlimited ingestion” as a feature. I see it as a tax. When you pipe every log into a SIEM (Security Information and Event Management) without custom detection engineering, you get a noisy black box. Analysts learn to ignore it. That is how breaches sit undetected for 10 days, the global median dwell time reported in Mandiant M-Trends 2024.
The 2024 IBM Cost of a Data Breach report pegs the average breach at $4.88 million, with detection delays as a top cost driver. Volume without curation does not buy you safety. It buys you bills and burnout. Our managed SIEM pricing guide walks through the math of when ingestion becomes an actual liability on the P&L.
Ingestion tuning ROI: cut volume 50 to 90 percent, fund the SOC
In our experience running UnderDefense Agentic AI SOC across customer environments, ingestion tuning routinely strips 50 to 90 percent of low-value telemetry before it ever hits the SIEM bill. That cut funds the SOC outright. One mid-market customer we onboarded (600 endpoints, Splunk-heavy) saved enough on Splunk ingest to pay for our service in the first quarter, and still kept the high-fidelity logs that mattered for detection.
A reviewer captured the same pattern on G2:
“The biggest win for me was getting actual control over our security alerts. Before the guys from UD stepped in, we were getting bombarded with alerts from all our security tools. Their team cleaned up our configurations and got the noise under control within the first week.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
Detection logic as code, not as PDF
The teams that survive 2026 treat detections like software. Rules in Python or Sigma. Version control in Git. CI/CD pipelines for deployment. Peer review before anything fires in production. That is the foundation of the SANS 2024 SOC Survey definition of a mature Tier 3 program.
Compare that to vendors who ship a closed rule pack and call it “AI.” When the rule misfires, you have no diff, no rollback, and no accountability. Detection-as-code gives you all three. Teams new to this discipline often benefit from our breakdown of SOC automation as a CISO checklist.
The coverage math, worked out
Tego Cyber’s 2026 alert fatigue study found the average enterprise SOC processes 2,992 alerts per day, and analysts touch only 38 percent before the queue resets. At 8 minutes per alert, full coverage demands 399 hours per day. No team has that.
Here is how we get to 100 percent coverage without adding people.
| Layer | Work done | Time |
|---|---|---|
| Ingestion tuning | Drop 50 to 90% noise pre-SIEM | Continuous |
| Agentic AI triage | Enrich, correlate, and suppress benign | Seconds |
| ChatOps user check | “Did you run this?” before containment | 1 to 5 minutes |
| Human analyst review | High-confidence escalations only | Minutes |
The Iron Man Suit, not the autopilot
I keep coming back to this analogy because it is honest. AI is the suit. The analyst is still the pilot. Operational data we have seen, alongside published SOC research, suggests AI gets the call right roughly 30 percent of the time on novel cases. That is a useful assistant, not a sole decision maker. Tilbury and Flowerday’s 2024 work on automation bias warns that fully delegating to AI creates new failure modes, especially when analysts stop reading the evidence.
Here is what I would do on Monday morning. Pick your top three highest-volume alert types. Audit how many ended in “benign” last quarter. If it is over 60 percent, your problem is not the SIEM. It is the lack of context enrichment in front of it. Our broader take on conversational SOCs covers how this enrichment plays out in practice.
“Now when we get an alert, we know it’s something worth looking into.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
“False positives have become a rarity, ensuring that our team’s focus remains on genuine threats.”
— Valeriia D., Marketing Specialist UnderDefense G2 – Verified Review
Q6. What MTTD/MTTR benchmarks should SOCs hit in 2026, and how do they translate into SLA clauses?
Mandiant’s 2024 global median dwell time is 10 days. AI-pipeline SOCs land MTTD (Mean Time to Detect) in single-digit minutes, with a 2-minute Alert-to-Triage and 15-minute escalation for critical incidents. The SLA translation is specific: detection within 5 minutes, triage within 15, containment within 60, with credits that bite if missed. Vague “best-effort” MDR contracts fail every regulatory clock that matters in 2026.
2026 benchmark ranges, by tier
Numbers should be uncomfortable to commit to. That is how you know they matter. Verizon DBIR 2024 found 68 percent of breaches involved a non-malicious human element, which means speed of containment matters more than ever, because the user is already inside. For a deeper definitional walk-through, see our explainer on SOC metrics, including MTTD and MTTR.
| Metric | 2026 industry median | AI-pipeline target | Suggested SLA clause |
|---|---|---|---|
| MTTA (acknowledge) | 10 to 30 min | Under 2 min | “Acknowledge within 2 min, 24×7, or 5% monthly credit” |
| MTTD (detect) | 10 days | 1 to 5 min | “Detection within 5 min for P1 events” |
| MTTT (triage) | 1 to 4 hours | Under 15 min | “Triage and severity assignment within 15 min for P1” |
| MTTR (contain) | 24 to 72 hours | Under 60 min | “Autonomous containment under 60 min for high-confidence P1” |
SLA clause language that holds up under audit
Vague language is where MDRs hide. “Best effort,” “commercially reasonable,” and “as soon as practicable” mean nothing in a NIS2 (the EU Network and Information Security Directive) or SEC cyber disclosure dispute. Replace them with measurable triggers, observable evidence, and credit math. For sample contract language, see our reference on SLA in cybersecurity.
A clause I would put in any 2026 contract:
“Provider shall detect P1 events within five (5) minutes, complete triage within fifteen (15) minutes, and execute pre-approved containment within sixty (60) minutes, measured from the originating telemetry timestamp. Failure to meet any threshold for two consecutive events in a calendar month results in a 10 percent service credit.”
Synthetic transactions are how you prove it. We push automated eventcreate commands into every data source on a schedule. If the pipeline does not light up in under 2 minutes, the source is broken, and we know before the customer does.
“Their adherence to SLAs gives me confidence in our infrastructure’s protection.”
— Oleg K., Director Information Security UnderDefense G2 – Verified Review
What I think we will see by 2027 is regulators citing specific MTTR thresholds in advisories, not just “timely.” If your MDR service contract cannot survive that conversation, renegotiate now.
Q7. How does autonomous response work, and where should humans still pull the trigger?
Autonomous response means the AI does not just write a ticket. It isolates the host, kills the session, resets the credential, and disables the token in under two minutes. The guardrails matter: pre-approved playbooks, blast-radius limits, and mandatory human review above a defined risk threshold. ChatOps loops bring the user into the decision (“Did you just run this command?”) before destructive containment fires.
The containment action menu, with timing
NIST SP 800-61 Rev. 3 frames containment as the bridge between detection and eradication. In practice, here is what actually fires in a mature pipeline.
- Host isolation via EDR (Endpoint Detection and Response) API, under 60 seconds
- Session and token revocation in Entra ID or Okta, under 90 seconds
- Credential reset and forced re-MFA, under 2 minutes
- Network block at firewall or SASE edge, under 2 minutes
- Email message recall and tenant-wide quarantine, under 5 minutes
For practitioners building runbooks around these actions, our incident response team publishes the playbook patterns that hold up in production.
ChatOps: breaking the fourth wall
Here is the move most MDRs miss. Before we lock a user out at 3 a.m., we ping them on Slack, Teams, or SMS: “Did you just run this PowerShell command on your laptop?” That single question collapses 80 percent of investigations. If they say yes and it matches their role, we close as benign. If they say no, or do not respond in 90 seconds, autonomous containment fires.
“Their seamless integration with Slack. We’ve tackled potential threats directly from our Slack channels, regardless of the hour.”
— Alexander B., CEO UnderDefense G2 – Verified Review
Compare that to the Arctic Wolf pattern customers describe on Gartner: alerts arrive without remediation context, and the customer team has to figure it out.
“Still not quite there with the remediation side of things. We receive alerts, but not necessarily a clear path to resolution. This is not an extension of our security team as was originally sold.”
— Sr Cybersecurity Engineer, Manufacturing Arctic Wolf – Gartner Verified Review
Where humans still pull the trigger
Tilbury and Flowerday’s 2024 paper on automation bias is the citation I send every CISO who asks about full autonomy. The countermeasure is structural, not cultural.
- Blast-radius caps: no playbook can touch more than N hosts without analyst sign-off
- Risk thresholds: any action against a domain controller, executive account, or production database escalates to a human
- Immutable audit trail: every AI decision logged with input data, model version, and reasoning chain
- Reversibility: containment actions chosen for “easy to undo” when uncertainty is non-zero
The Zimbra Memcache exploit story still sticks with me. EDR missed it. Behavioral log analysis caught it because a human read the auth pattern. Pure automation would have closed the ticket. That is why “human in the loop” is not a marketing line. It is the load-bearing wall. Our take on whether AI kills or saves the SOC team develops this argument in depth.
“The team is responsive and knows their stuff. When they escalate something, they include the context we need to understand the issue quickly.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
Q8. AI SOC pipeline vs traditional MDR vs legacy MSSP, what’s the real difference in 2026?
Traditional MDRs and legacy MSSPs hand you alerts. Outcome-based AI SOC pipelines hand you contained incidents with full investigation chains. Five real differentiators: transparency (full step trail vs black box), response (autonomous containment vs ticket forwarding), stack policy (BYO Splunk, Sentinel, or Chronicle vs proprietary data lake), deployment sovereignty (on-prem, hybrid, or sovereign vs vendor-cloud only), and pricing (transparent unit economics vs alert-volume billing surprises).
The five-axis framing
Gartner’s 2025 MDR Market Guide flags consolidation, AI integration, and outcome-based pricing as the dominant 2026 forces. Here is how the major archetypes line up against those axes. For a deeper provider-by-provider breakdown, see our MDR vendors list 2025.
| Axis | UnderDefense Agentic AI SOC | Arctic Wolf | CrowdStrike Falcon Complete | ReliaQuest GreyMatter | Legacy MSSP |
|---|---|---|---|---|---|
| Transparency | Full step trail, AI plus human, observable | Black box, alerts only | EDR-centric view | Black box critiques in reviews | Ticket forwarding |
| Response speed | Autonomous containment under 2 min | Customer remediates | Strong on endpoint, weaker cross-stack | Alert forwarding pattern | Email or ticket |
| Stack policy | BYO Splunk, Sentinel, Chronicle, and 250+ tools | Push to proprietary platform | Falcon-centric | Proprietary data lake | Vendor-locked |
| Deployment sovereignty | On-prem, hybrid, or sovereign for NIS2/GDPR | Vendor cloud | Vendor cloud | Vendor cloud | Mixed |
| Pricing model | Transparent per endpoint | Opaque, with renewal traps cited | Per endpoint, premium | Volume-based | Volume-based |
What customers actually say
The Arctic Wolf pattern shows up repeatedly in Gartner reviews: solid foundation, weak on remediation ownership.
“Arctic Wolf provides Solid detection and response capabilities, but overly relies on the client’s team for remediation, which really hurts the value of the service.”
— VP of Technology Arctic Wolf – Gartner Verified Review
“Beware they add a 60 day renewal notice instead of the typical 30 day notice. If you don’t give notice of cancelling any services before 60 days, you will automatically renew everything.”
— Verified User, Electrical/Electronic Manufacturing Arctic Wolf – G2 Verified Review
Red Canary customers describe similar gaps in pen-test detection and integration breadth.
“During these assessments, Red Canary was not able to identify the malicious activity while the tests were ongoing. Also, they do not have any sort of alert ingestion integrations with Splunk or other SIEM platforms.”
— Verified User in Insurance Red Canary – G2 Verified Review
Compare that with what UnderDefense customers describe: outcome ownership and stack preservation.
“It also solved our problem of having separate security tools that didn’t work well together. Now, everything is connected and easier to manage.”
— Inga M., CEO UnderDefense G2 – Verified Review
Less theater, more throughput
What I tell prospects is simple. If the demo is a slide deck, walk away. If the demo is a live workflow with reproducible outcomes, observable AI reasoning, and a real Slack ping firing on a real test event, that is the 2026 bar. BYO stack, deployment sovereignty for NIS2 and GDPR jurisdictions, and transparent unit economics are not features. They are minimums. Buyers running this evaluation should read our MDR buyers guide for the full scorecard.
The Forrester Wave for MDR has been pushing this same direction: outcomes over alerts, and transparency over black boxes. The vendors who survive 2027 will be the ones who can prove every step their AI took, on demand, in front of an auditor. For an alternative view, see how customers approach switching cybersecurity providers when the black box becomes untenable.
Q9. What questions and patent-aware criteria should CISOs use to separate real agentic AI from AI-washing?
Ask vendors to show three things on a live screen: a citation chain for every AI verdict, the hallucination rate from their last red-team test, and an autonomous containment action firing in under two minutes against a real EDR (Endpoint Detection and Response). Then demand patent disclosure: who owns the IP for the agent’s tool-use chain and adaptive baselining? Anything else is a deck demo.
The three live-demo asks ⚠️
I have sat through enough vendor pitches to know the pattern. Slides describe “agentic AI.” The live screen shows a static dashboard. That gap is where AI-washing lives. OWASP’s 2024 LLM Top 10 lists prompt injection, output handling, and excessive agency as the riskiest failure modes in production agents. If a vendor cannot demo against those, they are selling theater. Our list of AI SOC red flags covers the full audit checklist.
What I would ask, in order:
✅ Show me the citation chain. For one closed alert, expose every log query, every tool call, every model output, and every confidence score.
✅ Show me the hallucination rate. Pull the last red-team or eval report with date, sample size, and false-finding rate.
✅ Show me a containment action firing under two minutes against a live EDR sandbox, not a recorded video.
Patent-aware disclosure: who actually built it?
This is the lens most CISOs skip. USPTO, EPO, and WIPO records tell you who actually built the agentic investigation logic versus who licensed an OpenAI wrapper. Microsoft, CrowdStrike, and Palo Alto have public filings on agentic alert investigation and adaptive baselining. Smaller “AI SOC” startups often do not. That is not automatically disqualifying, but it is a question worth asking. For a competitive benchmark, see our piece on CrowdStrike vs SentinelOne and who is building the better AI SOC brain.
Patent disclosure asks I would put in an RFP:
- Does the vendor own or license the IP for tool-use orchestration?
- Are detection models trained on first-party telemetry, or rented from a foundation model API?
- What happens to your data if the foundation model provider changes terms?
The vendor scorecard
| Criterion | What to ask | ❌ Red flag | ✅ Green flag |
|---|---|---|---|
| Citation chain | “Show closed-ticket reasoning trail” | “Trust the model” | Full step log with timestamps |
| Hallucination rate | “Last red-team eval results” | “We don’t measure that” | Quarterly evals, with public methodology |
| Containment speed | “Live EDR isolation under 2 min” | Slide diagram only | Recorded live demo, customer reproducible |
| IP ownership | “Patent filings on agentic logic” | “It’s proprietary” | Named USPTO/EPO records |
| Data residency | “Where does telemetry sit?” | “In our cloud” | On-prem, hybrid, or sovereign options |
| Pricing transparency | “Per-endpoint vs per-alert?” | Volume surprises | Published unit economics |
For published unit economics on the buyer side, see our MDR pricing page.
Renamed products vs rebuilt outcomes
Most of what gets called “AI SOC” in 2026 is a renamed product. The dashboard is the same. The triage workflow is the same. A LLM (Large Language Model) summary box got bolted on. That is not agentic. Agentic means the system plans, calls tools, observes results, and decides the next action without a human ticket. The UnderDefense Agentic AI SOC platform was rebuilt around this pattern rather than retrofitted onto an alert queue.
Working with 500+ security teams, what I have noticed is a pattern. Vendors who rebuilt their pipeline can show the F3EAD (Find, Fix, Finish, Exploit, Analyze, Disseminate) loop running on a real event. Vendors who AI-washed cannot. That single live demo separates the two camps faster than any analyst report. Buyers running this evaluation should also reference the MDR buyers guide we publish for procurement teams.
A warning on the procurement side. There is a shadow economy of pay-to-play CISO recommendation schemes around VC-backed AI startups. If the only references you can get are paid advisors, treat that as a red flag, not a green one.
Q10. How does the AI SOC pipeline produce audit-grade evidence for NIS2, SEC 8-K, SOC 2, and HIPAA?
Every OSCAR (Observe, Score, Confirm, Act, Record) stage emits immutable evidence: anomaly score, AI verdict, human reviewer, containment action, and timestamp, into a tamper-evident log. That stream maps directly to NIS2’s 24-hour early warning, the SEC’s four-business-day 8-K Item 1.05 clock, SOC 2 Type II monitoring controls, ISO 27001 Annex A.16, and HIPAA’s 60-day breach notification. Auto-closure without an evidence chain is a compliance liability.
The immutable evidence chain ⏰
Auditors do not care that your AI was clever. They care that you can prove what it did, when, and why. NIS2 Article 23 requires an early warning within 24 hours of awareness of a significant incident, with a full notification at 72 hours. The SEC’s Final Rule 17 CFR §229.106 (Item 1.05) requires an 8-K filing within four business days of materiality determination. HIPAA’s Breach Notification Rule (45 CFR §164.400-414) gives covered entities 60 days for individual notice.
None of those clocks tolerate “the AI auto-closed it and we don’t have logs.” The fix is structural: every pipeline stage must write to a tamper-evident store with cryptographic integrity, not to a mutable database. Our compliance services team builds these evidence chains alongside the SOC pipeline rather than after the fact.
OSCAR stage to compliance artifact mapping
| OSCAR stage | Artifact emitted | NIS2 Art. 23 | SEC Item 1.05 | SOC 2 TSC | HIPAA 45 CFR §164 |
|---|---|---|---|---|---|
| Observe | Raw telemetry hash, source, and time | Detection timestamp | Discovery timestamp | CC7.2 | Discovery date |
| Score | Anomaly score, model version | Severity basis | Materiality input | CC7.3 | Risk assessment |
| Confirm | Human reviewer ID, decision | Awareness moment | Awareness trigger | CC7.4 | Reasonable diligence |
| Act | Containment action, scope | 24-hour mitigation note | Remediation status | CC7.5 | Mitigation log |
| Record | Immutable hash chain | Final 72-hour report | 8-K narrative | A1.2 | 60-day notice file |
For sector-specific clock handling, our MDR for Healthcare page goes deeper on the HIPAA 60-day workflow.
Deployment sovereignty for jurisdictional residency 🌍
For Fortune 1000 accounts under NIS2 or GDPR, telemetry residency is non-negotiable. If your MDR ships logs to a US cloud region by default, you have a data transfer impact assessment problem before you have a security problem. ISO 27001 Annex A.16 and AICPA SOC 2 TSC 2017 both require evidence that incident handling controls operate where they say they operate.
In our experience supporting EU customers, the only durable answer is deployment sovereignty: on-prem, hybrid, or sovereign cloud, with the data plane staying inside the customer’s chosen jurisdiction. That is also why we keep UnderDefense Agentic AI SOC vendor-agnostic on top of the customer’s existing Splunk, Sentinel, or Chronicle. The customer keeps the data. The auditor sees one continuous chain. For the broader regulatory roadmap, see our EU Cyber Resilience Act readiness guide.
A single piece of practical advice. Run a tabletop next quarter where the only question is: “Can you produce, in 60 minutes, a complete evidence package for an event from last quarter that satisfies NIS2 Article 23?” If the answer is no, that is your roadmap.
Q11. What’s the 90-day rollout plan, and what’s the board-level ROI story?
A realistic 90-day rollout has three arcs. Days 1 to 30 connect telemetry and tune ingestion (50 to 90 percent volume cut). Days 31 to 60 let baselines settle and migrate detections to version control. Days 61 to 90 enable autonomous containment for low-risk playbooks and instrument synthetic transactions. The board frame: organizations with extensive security AI saved USD 2.22M per breach and shortened lifecycle around 108 days (IBM, 2024). That is the number to put in the 8-K.
The 90-day plan, week by week
| Phase | Days | Core actions | Expected outcome |
|---|---|---|---|
| Connect and tune 💰 | 1 to 30 | Onboard SIEM, EDR, and identity sources; ingestion tuning; baseline FP rate | 50 to 90% volume cut, with hard-dollar SIEM savings |
| Baseline and codify | 31 to 60 | Behavioral baselines settle; migrate detections to Git/CI; ChatOps wired into Slack or Teams | Detection-as-code, with faster rollbacks |
| Automate and prove ⚡ | 61 to 90 | Autonomous containment for low-risk playbooks; synthetic transactions for every source; first board report | Sub-2-minute containment on safe actions, with audit-ready evidence |
The $300k accidental discovery
For an operational reference on how this phasing plays out, see our case study on how MDR reduced MTTR to 9 min for a US government organization.
A real customer story I tell on first calls. A mid-market services company onboarded MDR for compliance, not fraud detection. Inside the first 90 days, behavioral analysis flagged anomalies in payroll system access patterns. There was no malware involved. Pure log analysis caught a payroll fraud scheme that traditional rule-based detection would have missed entirely. The recovered loss covered the MDR contract for years. A parallel case is our write-up on how SIEM and SOC avoided a $650K loss for a similar customer profile.
That story matters because it shows the SANS Blueprint principle in practice: detection engineering pays back when it sees behavior, not just signatures.
“Their proactive threat hunting and rapid response have saved us from incidents that could have been incredibly costly.”
— Verified User in Program Development UnderDefense G2 – Verified Review
See how the UnderDefense Agentic AI SOC investigates, triages, and resolves real alerts.
The board slide that actually works
CISOs ask me what to put in front of a board on AI SOC investment. One slide, three numbers, all from IBM’s 2024 Cost of a Data Breach Report:
- USD 2.22 million average savings per breach for organizations with extensive security AI and automation
- 108 days shorter breach lifecycle for AI-mature organizations
- USD 4.88 million average breach cost in 2024, the highest on record
Pair those with your own current MTTD (Mean Time to Detect) numbers, plus a 2-minute Alert-to-Triage and 15-minute escalation target for critical incidents. The delta is the business case. Time is the currency of the cloud. Every minute shaved off response shows up in the 8-K narrative and the cyber insurance premium. For deeper budget framing, see our 2026 cybersecurity budget playbook.
“UnderDefense is surprisingly affordable considering the level of protection we get.”
— Verified User in Program Development UnderDefense G2 – Verified Review
“The reports from their platform give us clear evidence of our security controls and incident response capabilities. When auditors or clients ask questions about our security posture, we can pull up exactly what they need to see.”
— Verified User in Marketing and Advertising UnderDefense G2 – Verified Review
See your SOC’s MTTD and false-positive baseline in 30 minutes
Get a free walkthrough of the OSCAR pipeline against your own SIEM and EDR, no rip-and-replace, and no proprietary data lake.
Book your UnderDefense Agentic AI SOC walkthrough See transparent MDR pricingReferences
Research Papers
Alahmadi, B., Axon, L., and Martinovic, I. “99% False Positives: A Qualitative Study of SOC Analysts’ Perspectives on Security Alarms.” USENIX Security Symposium, 2022.
Anonymous authors. “LLM-Assisted Alert Triage in the Security Operations Center: Evaluation and Grounding.” arXiv cs.CR, 2024.
Tilbury, J., and Flowerday, S. “Automation Bias and Complacency in Security Operation Centers.” Computers and Security, 2024.
Mandiant. “M-Trends 2024 Special Report.” Google Cloud Security, 2024.
SANS Institute. “2024 SOC Survey: Facing Top Challenges in Security Operations.” SANS, 2024.
Tego Cyber. “2026 Alert Fatigue and SOC Capacity Study.” Tego Research, 2026.
Verizon. “2024 Data Breach Investigations Report (DBIR).” Verizon Business, 2024.
OWASP Foundation. “OWASP Top 10 for Large Language Model Applications, 2024.” OWASP, 2024.
Patents
Patent US 11,888,883 B2. Microsoft Corp. “Autonomous alert investigation using agentic LLM with tool use.” Assignee: Microsoft Corporation. Filed: 2023.
Patent US 11,418,524 B2. Vectra AI, Inc. “Adaptive peer-group behavioral baselining for anomaly detection.” Assignee: Vectra AI, Inc. Filed: 2021.
United States Patent and Trademark Office. “Patent filings on agentic alert investigation and adaptive baselining (Microsoft, CrowdStrike, Palo Alto Networks).” USPTO public database, 2023 to 2025.
Official Docs / Indian Statutes
NIST. “SP 800-94: Guide to Intrusion Detection and Prevention Systems (IDPS).” Published: 2007, with 2024 updates.
NIST. “SP 800-61 Rev. 3: Computer Security Incident Response Recommendations and Considerations.” Published: April 2025.
U.S. Joint Chiefs of Staff. “Joint Publication 2-0: Joint Intelligence.” Published: 2013.
MITRE Corporation. “MITRE ATT&CK Matrix for Enterprise, v15.” Published: 2024.
CISA. “Known Exploited Vulnerabilities Catalog.” Continuously updated.
European Union. “Directive (EU) 2022/2555 (NIS2), Article 23: Reporting obligations.” Official Journal of the European Union, 2022.
US SEC. “Final Rule: Cybersecurity Risk Management, Strategy, Governance, and Incident Disclosure, 17 CFR §229.106 (Item 1.05).” Published: 2023.
US HHS. “HIPAA Breach Notification Rule, 45 CFR §164.400-414.” HHS.gov.
ISO. “ISO/IEC 27001:2022, Annex A.16: Information security incident management.” Published: 2022.
AICPA. “SOC 2 Trust Services Criteria (TSC) 2017, with 2022 revisions.” Published: 2022.
Datasets
Vectra AI. “2026 State of Threat Detection Report.” Published: 2026.
IBM Security. “Cost of a Data Breach Report 2024.” IBM, 2024.
Gartner. “Market Guide for Managed Detection and Response Services 2025.” Gartner Research, 2025.
Forrester. “The Forrester Wave: Managed Detection and Response Services.” Forrester Research, 2025.
Blogs
UnderDefense. “UnderDefense MAXI internal customer telemetry, 500+ enterprise environments.” Published: 2024 to 2026. [Secondary source]
UnderDefense. “Customer call notes, fintech CISO, anonymized.” Published: 2025. [Secondary source]
Tymoshyk, N. “UnderDefense Founder Insights: 30% Accuracy Ceiling, Toil Penalty, Rebuilt vs Renamed.” Published: 2026. [Secondary source]
UnderDefense. “MAXI incident report: Zimbra Memcache exploit caught via behavioral log analysis.” Published: 2024. [Secondary source]
SANS Institute. “Blueprint for Building a Security Operations Center (SOC).” Published: 2024. [Secondary source]
G2. “UnderDefense MAXI Reviews.” [Secondary source]
Gartner. “Arctic Wolf Verified Reviews.” [Secondary source]
G2. “Red Canary Reviews.” [Secondary source]
1. What is an AI SOC pipeline and how is it different from a traditional SIEM-plus-MDR stack?
We define an AI SOC pipeline as a single, observable workflow that ties anomaly detection, agentic investigation, and autonomous containment together under one transparent control plane. A traditional stack bolts a SIEM to an EDR to an MDR vendor and hopes the seams hold. Ours does not. We collapse the seams. In our experience running UnderDefense Agentic AI SOC across global customer environments, the difference shows up in three places:
-
Detection is behavioral and per-identity, not rule-only.
-
Investigation is agentic, with every tool call and citation logged.
-
Response is autonomous for pre-approved playbooks, with humans in the loop above defined risk thresholds.
The result is what we hand back to the customer: contained incidents, not raised tickets. For practitioners weighing build versus buy, our guide to MDR services walks through where each archetype fits.
2. How does AI anomaly detection build a behavioral baseline without drowning analysts in noise?
We build per-user, per-host, and per-workload baselines from weeks of telemetry, weighted by peer group, time-of-day, and identity context. Static thresholds cannot keep up with hybrid cloud and identity sprawl. Adaptive baselines can. The trick is what fires on top of the baseline:
-
Anomaly scoring ranked by business impact, not just technical severity.
-
Long Tail Analysis to surface singletons, the rare odd ducks in the logs.
-
Continuous learning that updates the profile instead of waiting for a quarterly tuning cycle.
We pair baselines with SOC automation so the model handles the mechanical work and analysts handle judgment. The teams that adopt this pattern stop paying analyst salaries to do work the model should already be doing for them.
3. How does agentic AI investigate SIEM and EDR alerts without hallucinating MITRE mappings?
We force every AI verdict through retrieval-augmented grounding. The agent has to cite a real log line, a real EDR process tree, and a real ATT&CK record before it can output a verdict. Ungrounded LLMs hallucinate technique IDs roughly 12 percent of the time, which is unacceptable in production. Operationally, an investigation looks like this:
-
Pull the raw alert and EDR process tree.
-
Query identity, asset criticality, and threat intel.
-
Map to MITRE ATT&CK with retrieval grounding, never an LLM guess.
-
Draft a verdict with citation chain, confidence score, and recommended action.
If a vendor cannot show the citation chain on a live screen, that is one of the AI SOC red flags we coach buyers to walk away from. Transparency is the load-bearing wall of agentic AI in 2026.
4. What MTTD and MTTR benchmarks should an AI-pipeline SOC commit to in 2026?
We commit to a 2-minute Alert-to-Triage and a 15-minute escalation for critical incidents, with autonomous containment under 60 minutes for high-confidence P1 events. The global median dwell time is still 10 days. That gap is the business case. In contractual language, we recommend:
-
Detection within 5 minutes for P1 events.
-
Triage and severity assignment within 15 minutes.
-
Containment within 60 minutes, with credits that bite if missed.
Vague “best-effort” MDR contracts fail every regulatory clock that matters in 2026, from NIS2 to SEC 8-K. For benchmark definitions and how we measure them, our explainer on SOC metrics, including MTTD and MTTR goes deeper.
5. Where should humans still pull the trigger inside an autonomous response pipeline?
We let autonomy fire on pre-approved playbooks (host isolation, session and token revocation, credential reset) but keep humans in charge of anything with blast radius. That includes domain controllers, executive accounts, and production databases. The guardrails we run:
-
Blast-radius caps that prevent a playbook from touching more than N hosts without analyst sign-off.
-
Risk thresholds that escalate high-impact actions to humans.
-
Immutable audit trail with model version, input data, and reasoning.
-
ChatOps loops that ask the user, “Did you just run this command?” before destructive containment.
Our broader take on whether AI kills or saves the SOC team develops the automation-bias countermeasures. The analyst is still the pilot. AI is the suit.
6. How do we cut false positives more than 90 percent without missing real attacks?
We do it by adding context at ingestion, not by suppressing alerts at triage. Asset criticality, identity, peer behavior, and threat intel turn “suspicious PowerShell” into “patch automation, benign” or “lateral movement, contain now.” The layered math looks like this:
-
Ingestion tuning drops 50 to 90 percent of low-value telemetry before it hits the SIEM bill.
-
Agentic AI triage enriches, correlates, and suppresses benign in seconds.
-
ChatOps user checks resolve another large chunk in under five minutes.
-
Human analysts review only high-confidence escalations.
For the unit economics, see our managed SIEM pricing guide on how ingestion tuning funds the SOC outright.
7. How do we separate real agentic AI from AI-washing during vendor evaluation?
We ask three live-demo questions. Show the citation chain for a closed alert. Show the hallucination rate from the last red-team eval. Show a containment action firing under two minutes against a live EDR sandbox. Then we ask the patent question:
-
Does the vendor own or license the IP for tool-use orchestration and adaptive baselining?
-
Are detection models trained on first-party telemetry, or rented from a foundation model API?
-
What happens to your data if the foundation model provider changes terms?
Most “AI SOC” products in 2026 are renamed dashboards with an LLM summary box bolted on. Our MDR buyers guide lays out the full scorecard. If the demo is a slide deck, walk away.
8. What does a realistic 90-day AI SOC rollout look like and what is the board-level ROI?
We sequence the rollout in three arcs. Days 1 to 30 connect telemetry and tune ingestion. Days 31 to 60 let baselines settle and migrate detections to version control. Days 61 to 90 enable autonomous containment for low-risk playbooks and instrument synthetic transactions. The board frame we recommend:
-
USD 2.22 million average savings per breach for organizations with extensive security AI (IBM 2024).
-
108 days shorter breach lifecycle for AI-mature organizations.
-
USD 4.88 million average breach cost in 2024, the highest on record.
For budget framing alongside the rollout, our 2026 cybersecurity budget playbook is the companion read. Every minute shaved off response shows up in the 8-K and the insurance premium.