In this post we are going to take a look at Domain Generation Algorithms (DGA) and an interesting way to detect them with the help of Deep Learning (LSTM neural net, to be precise).
Take control of your business security, before hackers do.
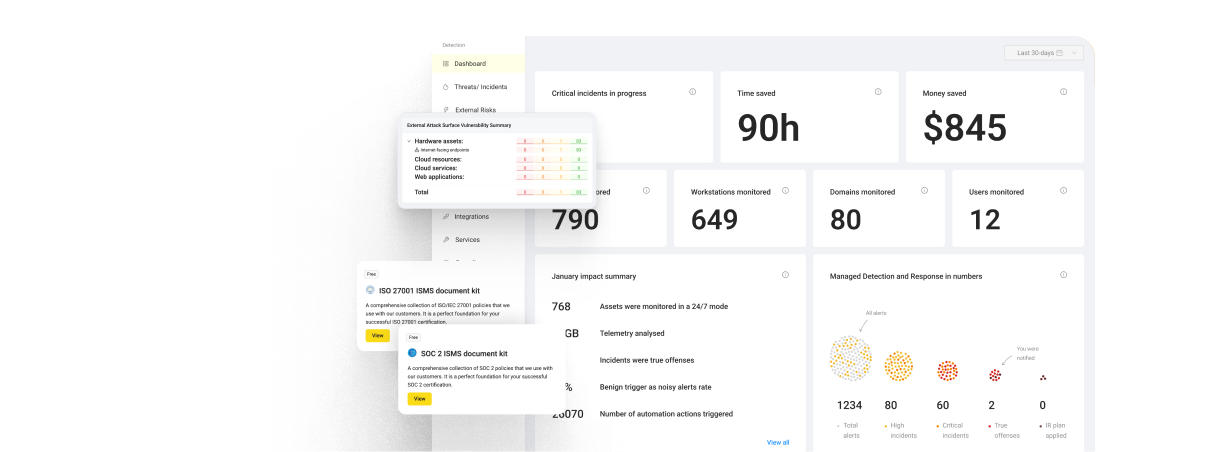
DGA domains are extensively used by many kinds of malware to communicate to the Command and Control servers. Before DGA came into play, most malicious programs used hardcoded lists of IP addresses or domains. Unlike them, DGA is much harder to block by antimalware software or network administrators since it’s nearly impossible to predict the next place commands will come from. It is crucial for businesses to be able to detect network requests to DGA domains on early stages of malware spread to minimize the number of infected machines and to reduce cost of recovery.
What is DGA?
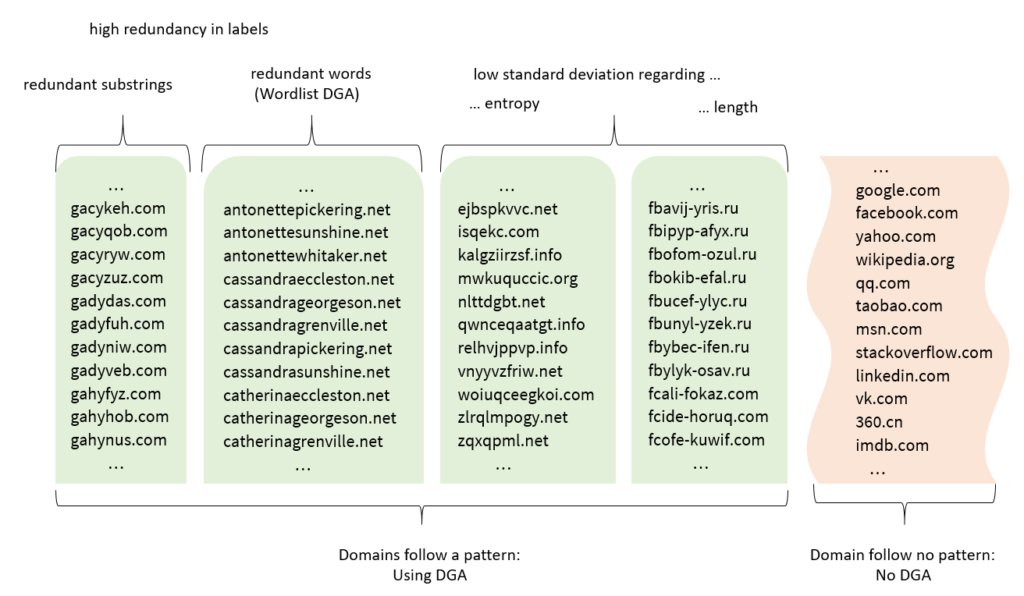
Domain Generation Algorithms (DGA) is a wide family of algorithms that help malicious software periodically generate a large number of domain names that can be used as communication points with Command and Control servers to receive instructions on what to do with the infected host. Here you can find the list of some domain generation algorithms reverse-engineered from real malware. Usually, DGA domains look like random strings and are easily noticeable by the human eye.
Some examples for you to have the idea:
- dceikkdhgikm.bazar
- jk9enwhansl2.org
- trbhxhmbsikoaq.pw
- agdehukoev.ddns.net
However, there are algorithms that use dictionaries to generate a domain. They take 2 or more words and concatenate them in some way to get the result. Domains of this kind seem completely normal and are hard to detect by humans, let alone software.
Some examples:
- indulgentiarumlicet.com
- papacricognitisipro.com
- timelydesignation.co
- eearlynearly.net
DGA domains detection
How do we detect domains generated by DGA? There are two primary techniques: reactionary and real-time. The former technique relies on statistical data such as DNS responses, IP address location, WHOIS, and TLS certificate information to determine domain name legitimacy. Whereas the latter technique involves the analysis of the domain name itself – as a regular sequence of characters. This allows for a wide variety of approaches to detect unnatural or weird domains. The most common ones are:
- Splitting the domain name into N-grams followed by frequency analysis
- Calculating the entropy of the domain (this works poorly with non-ASCII domains and dictionary-based DGAs)
- Using recurrent neural networks (RNN) to analyze the domain.
The N-gram approach proves to be very effective when performance matters but its accuracy is quite average, let alone that the implementation is fairly complex. Here you can find an example of DGA detection using N-grams.
The entropy approach, on the other hand, is most performant and is very low on memory and CPU. Its accuracy is the worst of the three but because of straightforward implementation, simplicity, and speed, it can be utilized in case you need rough estimation and don’t mind some false alarms.
And the most interesting one – machine learning approach. Well-trained neural networks can show some amazing results and the number of false alarms close to zero. However, it compromises performance and resource utilization for exceptional accuracy. If accuracy is mission critical – ML is the way to go!
In this post, I won’t deep dive into deep learning theory – there’re plenty of articles and videos to get you started: one, two, three, four.
Do you want to make your company secure and resilient?
Training dataset
Non-DGA data
To compile a list of non-DGA domain names I used Alexa’s top 1M domains and Cisco Umbrella’s top 1M domains. Combined list contained a lot of duplicates and domains with invalid DNS characters so I had to clean it up a bit to get a list of ~200k labelled “benign” domains.
DGA data
I used reverse-engineered DGAs mentioned before to compile a list of generated domains. After cleaning and removing duplicates I got the set of ~300k domains.
Code
To build a DGA classifier, I’ll be using Keras since it has convenient wrappers for LSTM recurrent neural network.
1. We import all classes and methods we’ll need further:

2. Read DGA and non-DGA datasets:

3. Extract top-level domains (TLD) and clean the dataset from undesired characters:

4. Remove duplicates and label each domain:

5. Combine two datasets and shuffle them:

6. Assign a number for each possible character in the domains and determine the maximum domain length:

7. Encode each domain and build a testing and evaluating dataset:

8. Build and compile LSTM model:

Here I’m using a very basic architecture. First, I use the Embedding layer to turn my input sequence into a fixed-length vector. Then I put an LSTM layer with 128 neurons (this number was chosen experimentally, with trial and error). Then I apply a random Dropout to LSTM layer output to prevent overfitting during training. And finally, a Dense layer with a single neuron with sigmoid activation will produce the final verdict of the model in a range between 0 (benign domain) and 1 (DGA). Since the model is used to do binary classification based on the continuous output of the last layer, I use binary cross-entropy as a loss function and rmsprop as an optimizer to improve accuracy and reduce training time.
9. Train the model for 15 epochs:

The training takes 1-3 hours depending on the hardware. After we trained the model, we can finally feed some domains into it:

Let’s evaluate the model and calculate some statistics to be able to see how the model performs:
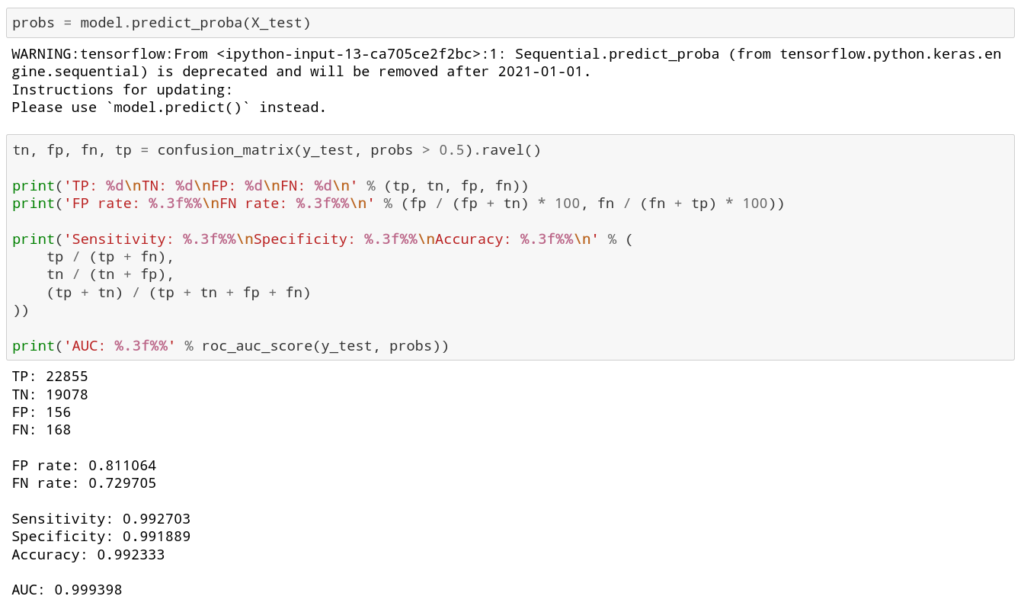
As you can see, model can recognize DGA domains with the accuracy of more than 99%! That’s an amazing result for such a simple model.
Being prudent makes all the difference
Join 500+ companies that work with UnderDefense to protect their operations
Conclusion
In this post I quickly went through the full process of collecting the data, compiling the dataset and building the deep learning model based on LSTM recurrent neural network to distinguish between legitimate domain names and those that are generated by DGA algorithms.
Any feedback is more than welcome and I hope this is helpful!
By Alexander Ragulin